 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaSplit: Adaptive Trade-offs for Resource-constrained Distributed Deep Learning
Dec 02, 2021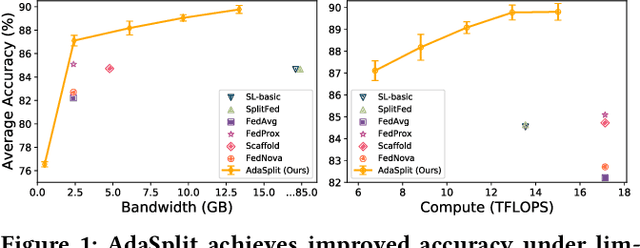
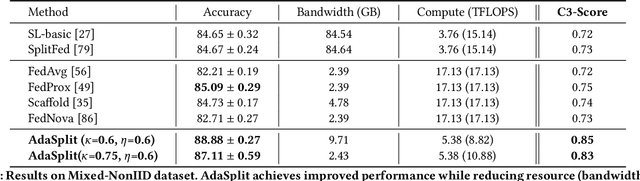
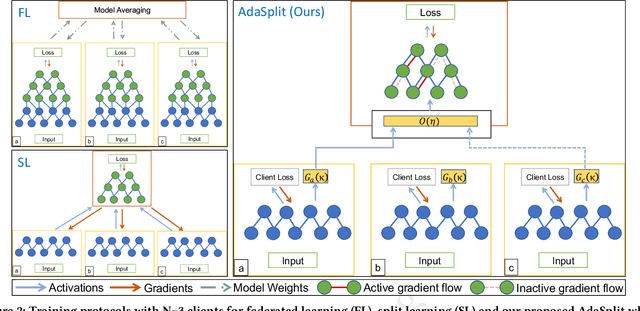
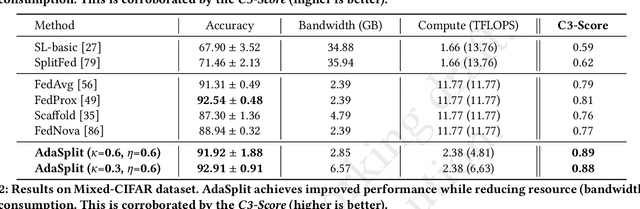
Distributed deep learning frameworks like federated learning (FL) and its variants are enabling personalized experiences across a wide range of web clients and mobile/IoT devices. However, FL-based frameworks are constrained by computational resources at clients due to the exploding growth of model parameters (eg. billion parameter model). Split learning (SL), a recent framework, reduces client compute load by splitting the model training between client and server. This flexibility is extremely useful for low-compute setups but is often achieved at cost of increase in bandwidth consumption and may result in sub-optimal convergence, especially when client data is heterogeneous. In this work, we introduce AdaSplit which enables efficiently scaling SL to low resource scenarios by reducing bandwidth consumption and improving performance across heterogeneous clients. To capture and benchmark this multi-dimensional nature of distributed deep learning, we also introduce C3-Score, a metric to evaluate performance under resource budgets. We validate the effectiveness of AdaSplit under limited resources through extensive experimental comparison with strong federated and split learning baselines. We also present a sensitivity analysis of key design choices in AdaSplit which validates the ability of AdaSplit to provide adaptive trade-offs across variable resource budgets.
Private measurement of nonlinear correlations between data hosted across multiple parties
Nov 08, 2021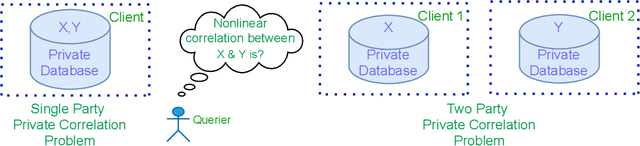

We introduce a differentially private method to measure nonlinear correlations between sensitive data hosted across two entities. We provide utility guarantees of our private estimator. Ours is the first such private estimator of nonlinear correlations, to the best of our knowledge within a multi-party setup. The important measure of nonlinear correlation we consider is distance correlation. This work has direct applications to private feature screening, private independence testing, private k-sample tests, private multi-party causal inference and private data synthesis in addition to exploratory data analysis. Code access: A link to publicly access the code is provided in the supplementary file.
Parallel Quasi-concave set optimization: A new frontier that scales without needing submodularity
Aug 19, 2021
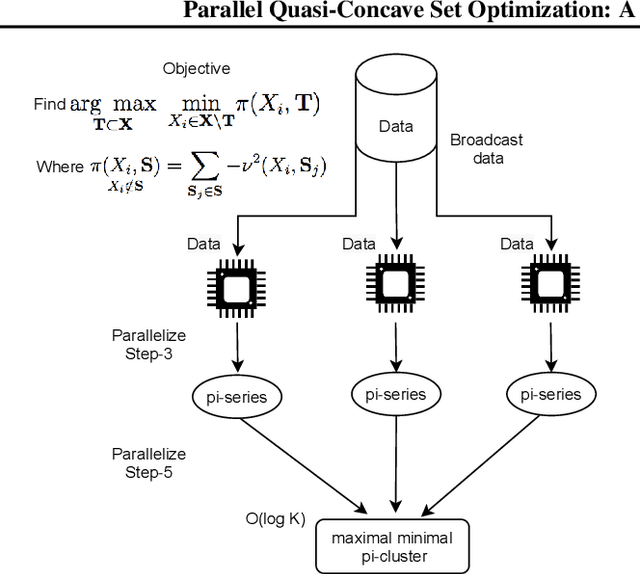
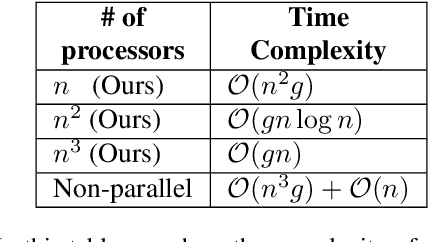
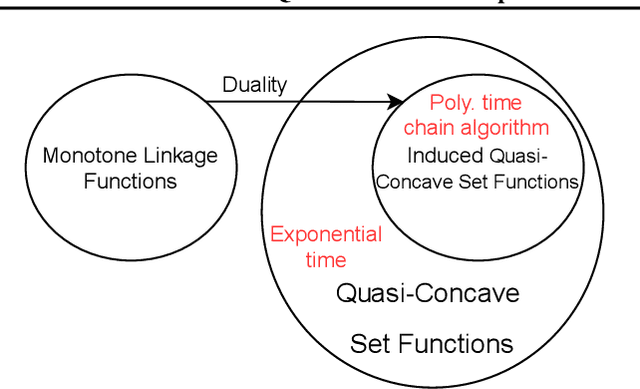
Classes of set functions along with a choice of ground set are a bedrock to determine and develop corresponding variants of greedy algorithms to obtain efficient solutions for combinatorial optimization problems. The class of approximate constrained submodular optimization has seen huge advances at the intersection of good computational efficiency, versatility and approximation guarantees while exact solutions for unconstrained submodular optimization are NP-hard. What is an alternative to situations when submodularity does not hold? Can efficient and globally exact solutions be obtained? We introduce one such new frontier: The class of quasi-concave set functions induced as a dual class to monotone linkage functions. We provide a parallel algorithm with a time complexity over $n$ processors of $\mathcal{O}(n^2g) +\mathcal{O}(\log{\log{n}})$ where $n$ is the cardinality of the ground set and $g$ is the complexity to compute the monotone linkage function that induces a corresponding quasi-concave set function via a duality. The complexity reduces to $\mathcal{O}(gn\log(n))$ on $n^2$ processors and to $\mathcal{O}(gn)$ on $n^3$ processors. Our algorithm provides a globally optimal solution to a maxi-min problem as opposed to submodular optimization which is approximate. We show a potential for widespread applications via an example of diverse feature subset selection with exact global maxi-min guarantees upon showing that a statistical dependency measure called distance correlation can be used to induce a quasi-concave set function.
AirMixML: Over-the-Air Data Mixup for Inherently Privacy-Preserving Edge Machine Learning
May 02, 2021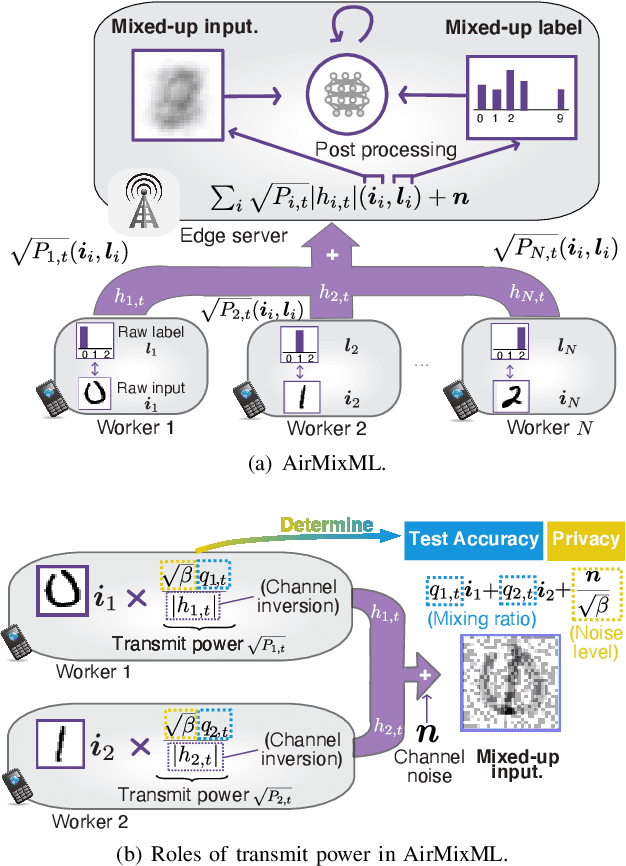
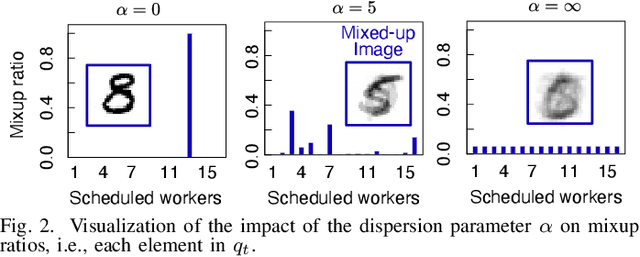
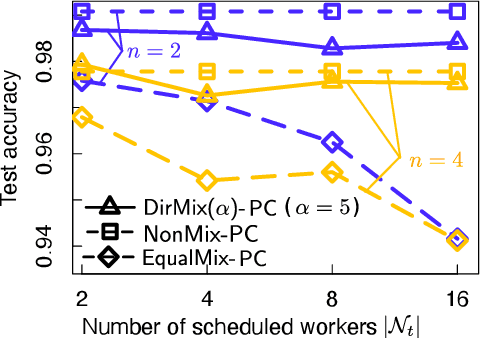
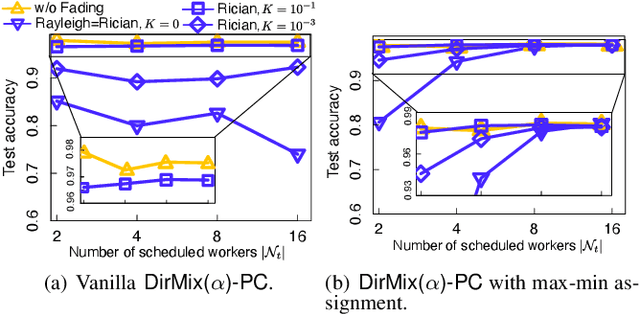
Wireless channels can be inherently privacy-preserving by distorting the received signals due to channel noise, and superpositioning multiple signals over-the-air. By harnessing these natural distortions and superpositions by wireless channels, we propose a novel privacy-preserving machine learning (ML) framework at the network edge, coined over-the-air mixup ML (AirMixML). In AirMixML, multiple workers transmit analog-modulated signals of their private data samples to an edge server who trains an ML model using the received noisy-and superpositioned samples. AirMixML coincides with model training using mixup data augmentation achieving comparable accuracy to that with raw data samples. From a privacy perspective, AirMixML is a differentially private (DP) mechanism limiting the disclosure of each worker's private sample information at the server, while the worker's transmit power determines the privacy disclosure level. To this end, we develop a fractional channel-inversion power control (PC) method, {\alpha}-Dirichlet mixup PC (DirMix({\alpha})-PC), wherein for a given global power scaling factor after channel inversion, each worker's local power contribution to the superpositioned signal is controlled by the Dirichlet dispersion ratio {\alpha}. Mathematically, we derive a closed-form expression clarifying the relationship between the local and global PC factors to guarantee a target DP level. By simulations, we provide DirMix({\alpha})-PC design guidelines to improve accuracy, privacy, and energy-efficiency. Finally, AirMixML with DirMix({\alpha})-PC is shown to achieve reasonable accuracy compared to a privacy-violating baseline with neither superposition nor PC.
Differentially Private Supervised Manifold Learning with Applications like Private Image Retrieval
Feb 22, 2021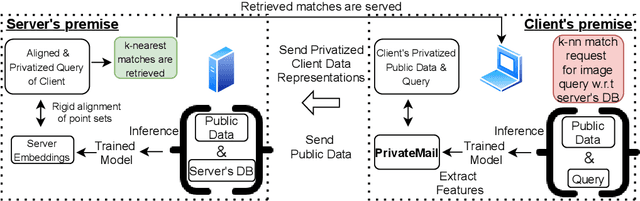
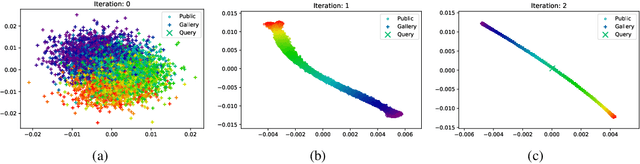

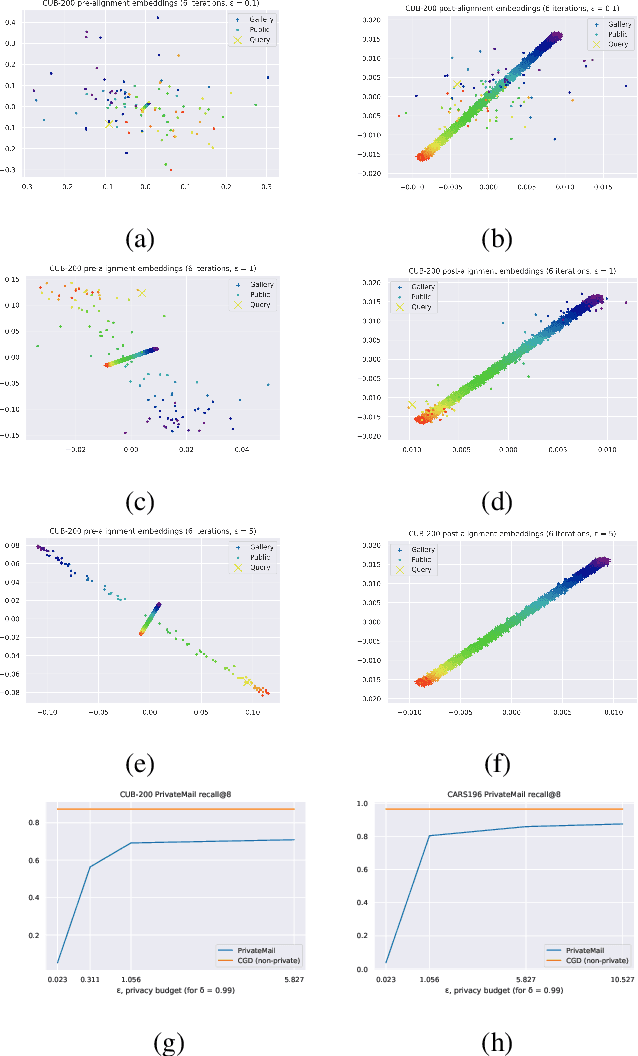
Differential Privacy offers strong guarantees such as immutable privacy under post processing. Thus it is often looked to as a solution to learning on scattered and isolated data. This work focuses on supervised manifold learning, a paradigm that can generate fine-tuned manifolds for a target use case. Our contributions are two fold. 1) We present a novel differentially private method \textit{PrivateMail} for supervised manifold learning, the first of its kind to our knowledge. 2) We provide a novel private geometric embedding scheme for our experimental use case. We experiment on private "content based image retrieval" - embedding and querying the nearest neighbors of images in a private manner - and show extensive privacy-utility tradeoff results, as well as the computational efficiency and practicality of our methods.
DISCO: Dynamic and Invariant Sensitive Channel Obfuscation for deep neural networks
Dec 20, 2020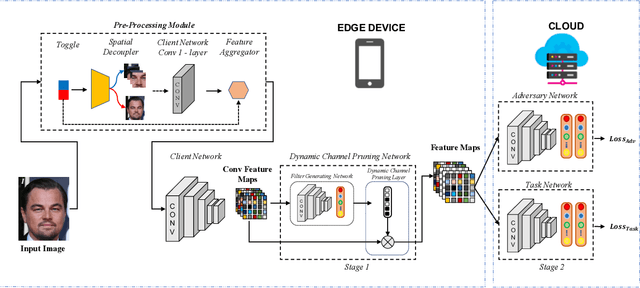
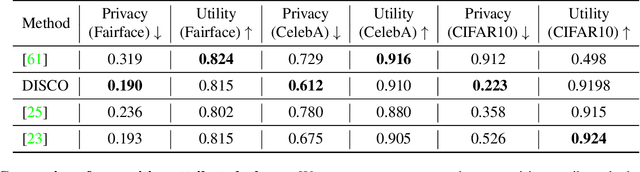

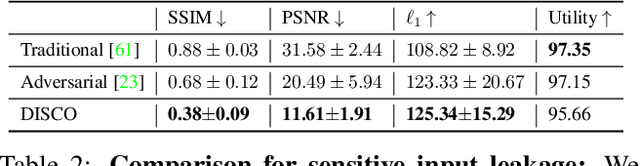
Recent deep learning models have shown remarkable performance in image classification. While these deep learning systems are getting closer to practical deployment, the common assumption made about data is that it does not carry any sensitive information. This assumption may not hold for many practical cases, especially in the domain where an individual's personal information is involved, like healthcare and facial recognition systems. We posit that selectively removing features in this latent space can protect the sensitive information and provide a better privacy-utility trade-off. Consequently, we propose DISCO which learns a dynamic and data driven pruning filter to selectively obfuscate sensitive information in the feature space. We propose diverse attack schemes for sensitive inputs \& attributes and demonstrate the effectiveness of DISCO against state-of-the-art methods through quantitative and qualitative evaluation. Finally, we also release an evaluation benchmark dataset of 1 million sensitive representations to encourage rigorous exploration of novel attack schemes.
NoPeek: Information leakage reduction to share activations in distributed deep learning
Aug 20, 2020
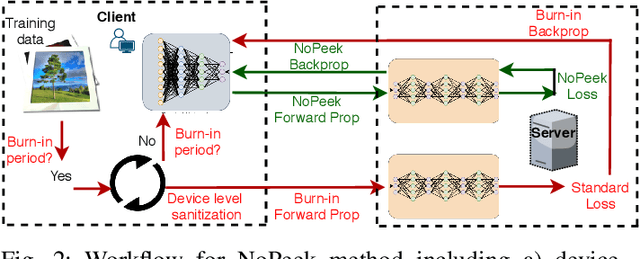
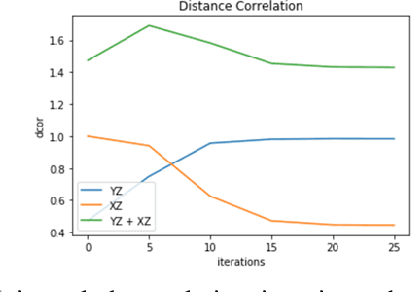
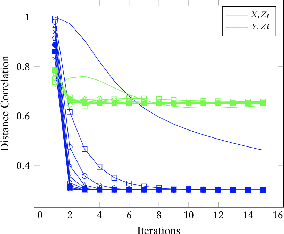
For distributed machine learning with sensitive data, we demonstrate how minimizing distance correlation between raw data and intermediary representations reduces leakage of sensitive raw data patterns across client communications while maintaining model accuracy. Leakage (measured using distance correlation between input and intermediate representations) is the risk associated with the invertibility of raw data from intermediary representations. This can prevent client entities that hold sensitive data from using distributed deep learning services. We demonstrate that our method is resilient to such reconstruction attacks and is based on reduction of distance correlation between raw data and learned representations during training and inference with image datasets. We prevent such reconstruction of raw data while maintaining information required to sustain good classification accuracies.
SplitNN-driven Vertical Partitioning
Aug 07, 2020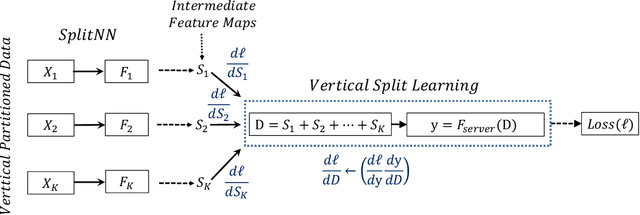
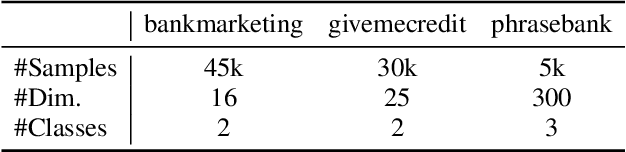
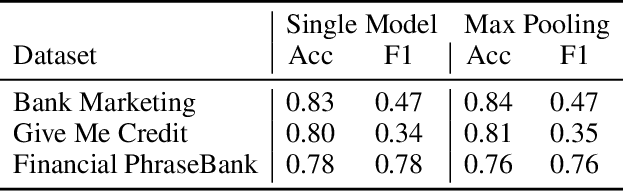
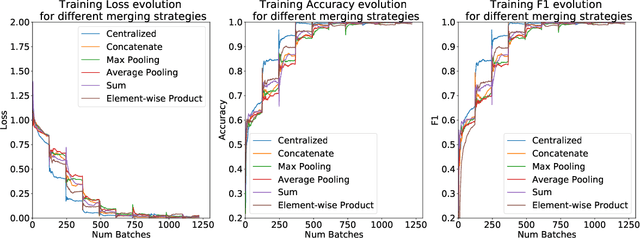
In this work, we introduce SplitNN-driven Vertical Partitioning, a configuration of a distributed deep learning method called SplitNN to facilitate learning from vertically distributed features. SplitNN does not share raw data or model details with collaborating institutions. The proposed configuration allows training among institutions holding diverse sources of data without the need of complex encryption algorithms or secure computation protocols. We evaluate several configurations to merge the outputs of the split models, and compare performance and resource efficiency. The method is flexible and allows many different configurations to tackle the specific challenges posed by vertically split datasets.
FedML: A Research Library and Benchmark for Federated Machine Learning
Jul 27, 2020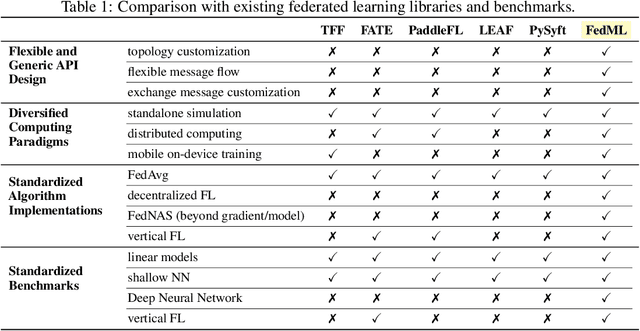
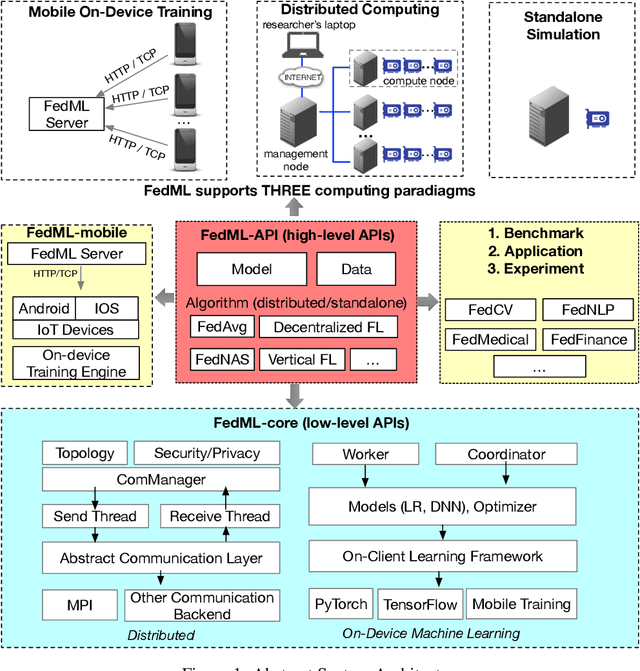


Federated learning is a rapidly growing research field in the machine learning domain. Although considerable research efforts have been made, existing libraries cannot adequately support diverse algorithmic development (e.g., diverse topology and flexible message exchange), and inconsistent dataset and model usage in experiments make fair comparisons difficult. In this work, we introduce FedML, an open research library and benchmark that facilitates the development of new federated learning algorithms and fair performance comparisons. FedML supports three computing paradigms (distributed training, mobile on-device training, and standalone simulation) for users to conduct experiments in different system environments. FedML also promotes diverse algorithmic research with flexible and generic API design and reference baseline implementations. A curated and comprehensive benchmark dataset for the non-I.I.D setting aims at making a fair comparison. We believe FedML can provide an efficient and reproducible means of developing and evaluating algorithms for the federated learning research community. We maintain the source code, documents, and user community at https://FedML.ai.
Splintering with distributions: A stochastic decoy scheme for private computation
Jul 07, 2020

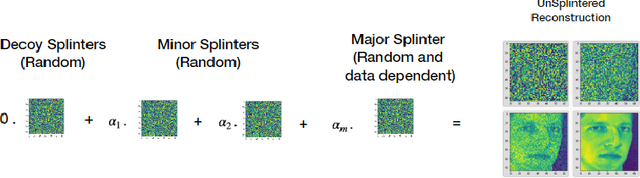
Performing computations while maintaining privacy is an important problem in todays distributed machine learning solutions. Consider the following two set ups between a client and a server, where in setup i) the client has a public data vector $\mathbf{x}$, the server has a large private database of data vectors $\mathcal{B}$ and the client wants to find the inner products $\langle \mathbf{x,y_k} \rangle, \forall \mathbf{y_k} \in \mathcal{B}$. The client does not want the server to learn $\mathbf{x}$ while the server does not want the client to learn the records in its database. This is in contrast to another setup ii) where the client would like to perform an operation solely on its data, such as computation of a matrix inverse on its data matrix $\mathbf{M}$, but would like to use the superior computing ability of the server to do so without having to leak $\mathbf{M}$ to the server. \par We present a stochastic scheme for splitting the client data into privatized shares that are transmitted to the server in such settings. The server performs the requested operations on these shares instead of on the raw client data at the server. The obtained intermediate results are sent back to the client where they are assembled by the client to obtain the final result.