 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow the Perturbed Leader: Optimism and Fast Parallel Algorithms for Smooth Minimax Games
Jun 13, 2020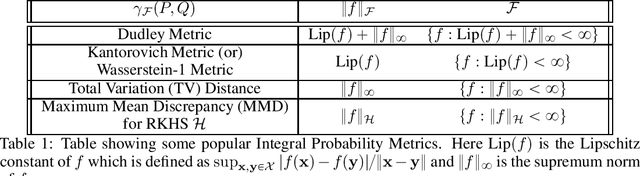

We consider the problem of online learning and its application to solving minimax games. For the online learning problem, Follow the Perturbed Leader (FTPL) is a widely studied algorithm which enjoys the optimal $O(T^{1/2})$ worst-case regret guarantee for both convex and nonconvex losses. In this work, we show that when the sequence of loss functions is predictable, a simple modification of FTPL which incorporates optimism can achieve better regret guarantees, while retaining the optimal worst-case regret guarantee for unpredictable sequences. A key challenge in obtaining these tighter regret bounds is the stochasticity and optimism in the algorithm, which requires different analysis techniques than those commonly used in the analysis of FTPL. The key ingredient we utilize in our analysis is the dual view of perturbation as regularization. While our algorithm has several applications, we consider the specific application of minimax games. For solving smooth convex-concave games, our algorithm only requires access to a linear optimization oracle. For Lipschitz and smooth nonconvex-nonconcave games, our algorithm requires access to an optimization oracle which computes the perturbed best response. In both these settings, our algorithm solves the game up to an accuracy of $O(T^{-1/2})$ using $T$ calls to the optimization oracle. An important feature of our algorithm is that it is highly parallelizable and requires only $O(T^{1/2})$ iterations, with each iteration making $O(T^{1/2})$ parallel calls to the optimization oracle.
P-SIF: Document Embeddings Using Partition Averaging
May 18, 2020


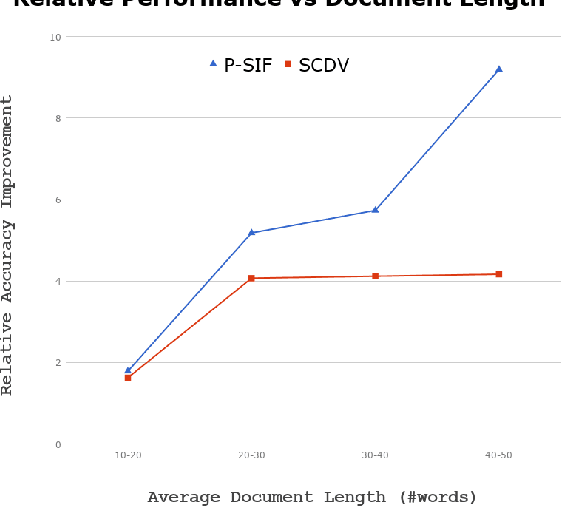
Simple weighted averaging of word vectors often yields effective representations for sentences which outperform sophisticated seq2seq neural models in many tasks. While it is desirable to use the same method to represent documents as well, unfortunately, the effectiveness is lost when representing long documents involving multiple sentences. One of the key reasons is that a longer document is likely to contain words from many different topics; hence, creating a single vector while ignoring all the topical structure is unlikely to yield an effective document representation. This problem is less acute in single sentences and other short text fragments where the presence of a single topic is most likely. To alleviate this problem, we present P-SIF, a partitioned word averaging model to represent long documents. P-SIF retains the simplicity of simple weighted word averaging while taking a document's topical structure into account. In particular, P-SIF learns topic-specific vectors from a document and finally concatenates them all to represent the overall document. We provide theoretical justifications on the correctness of P-SIF. Through a comprehensive set of experiments, we demonstrate P-SIF's effectiveness compared to simple weighted averaging and many other baselines.
MOReL : Model-Based Offline Reinforcement Learning
May 12, 2020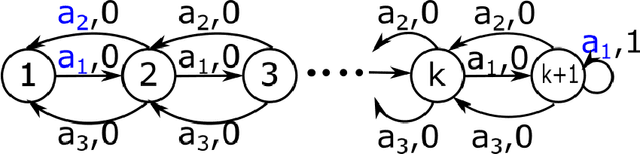
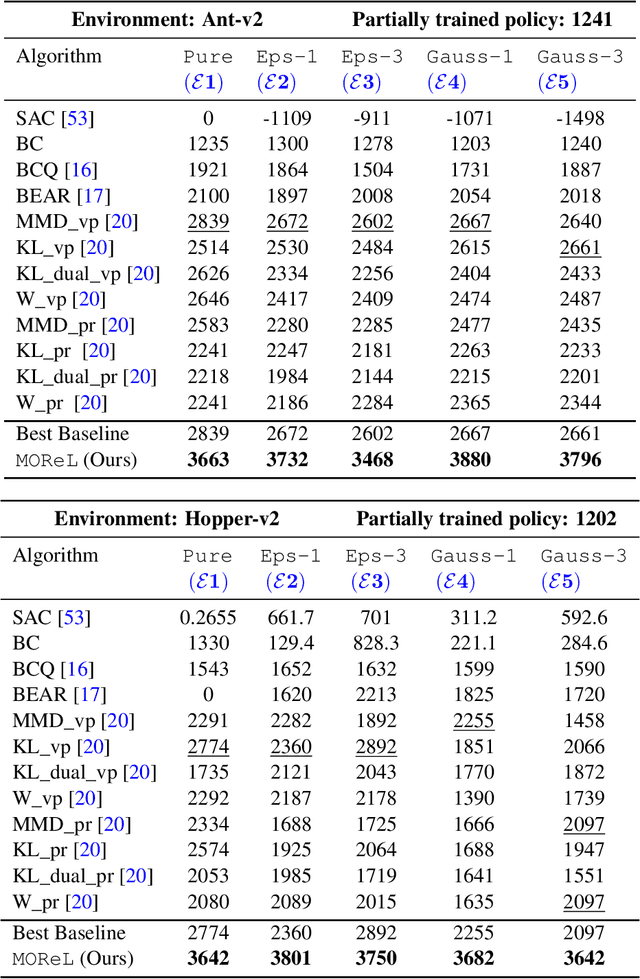
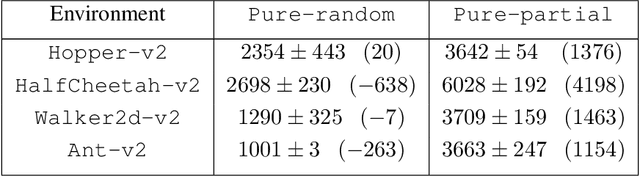
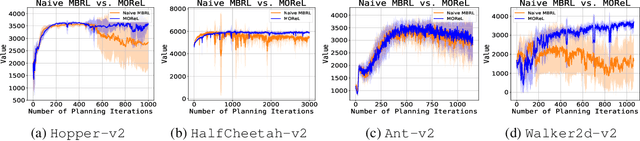
In offline reinforcement learning (RL), the goal is to learn a successful policy using only a dataset of historical interactions with the environment, without any additional online interactions. This serves as an extreme test for an agent's ability to effectively use historical data, which is critical for efficient RL. Prior work in offline RL has been confined almost exclusively to model-free RL approaches. In this work, we present MOReL, an algorithmic framework for model-based RL in the offline setting. This framework consists of two steps: (a) learning a pessimistic MDP model using the offline dataset; (b) learning a near-optimal policy in the learned pessimistic MDP. The construction of the pessimistic MDP is such that for any policy, the performance in the real environment is lower bounded by the performance in the pessimistic MDP. This enables the pessimistic MDP to serve as a good surrogate for the purposes of policy evaluation and learning. Overall, MOReL is amenable to detailed theoretical analysis, enables easy and transparent design of practical algorithms, and leads to state-of-the-art results on widely studied offline RL benchmark tasks.
Efficient Domain Generalization via Common-Specific Low-Rank Decomposition
Apr 07, 2020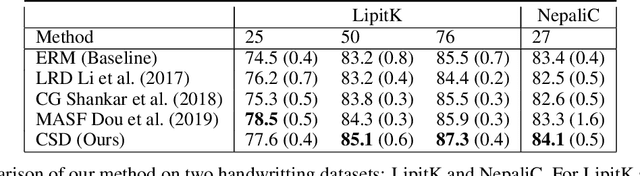
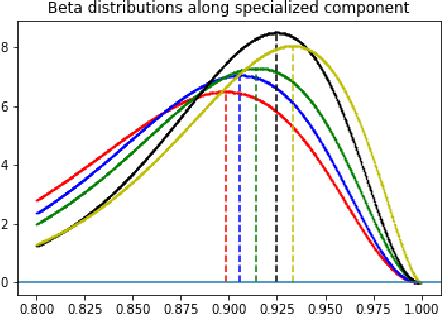


Domain generalization refers to the task of training a model which generalizes to new domains that are not seen during training. We present CSD (Common Specific Decomposition), for this setting,which jointly learns a common component (which generalizes to new domains) and a domain specific component (which overfits on training domains). The domain specific components are discarded after training and only the common component is retained. The algorithm is extremely simple and involves only modifying the final linear classification layer of any given neural network architecture. We present a principled analysis to understand existing approaches, provide identifiability results of CSD,and study effect of low-rank on domain generalization. We show that CSD either matches or beats state of the art approaches for domain generalization based on domain erasure, domain perturbed data augmentation, and meta-learning. Further diagnostics on rotated MNIST, where domains are interpretable, confirm the hypothesis that CSD successfully disentangles common and domain specific components and hence leads to better domain generalization.
Non-Gaussianity of Stochastic Gradient Noise
Oct 25, 2019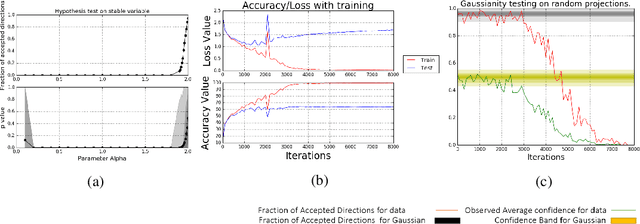
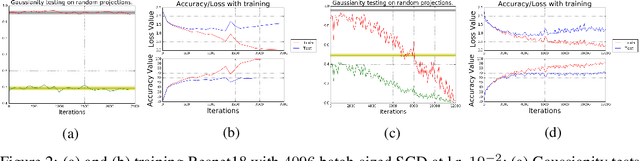
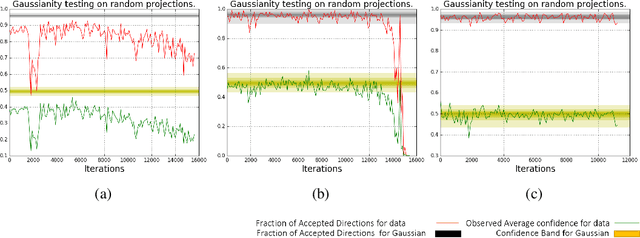
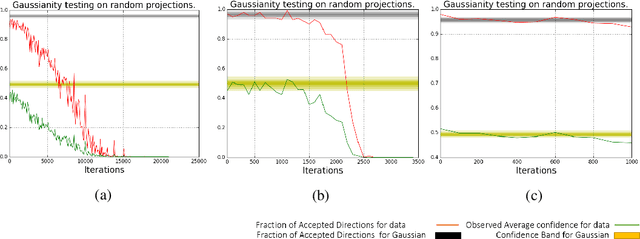
What enables Stochastic Gradient Descent (SGD) to achieve better generalization than Gradient Descent (GD) in Neural Network training? This question has attracted much attention. In this paper, we study the distribution of the Stochastic Gradient Noise (SGN) vectors during the training. We observe that for batch sizes 256 and above, the distribution is best described as Gaussian at-least in the early phases of training. This holds across data-sets, architectures, and other choices.
Efficient Algorithms for Smooth Minimax Optimization
Jul 02, 2019
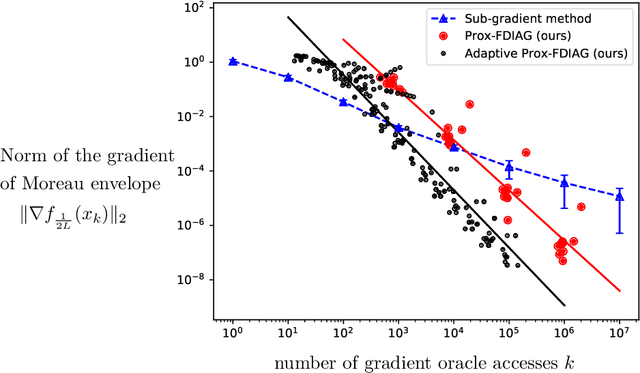
This paper studies first order methods for solving smooth minimax optimization problems $\min_x \max_y g(x,y)$ where $g(\cdot,\cdot)$ is smooth and $g(x,\cdot)$ is concave for each $x$. In terms of $g(\cdot,y)$, we consider two settings -- strongly convex and nonconvex -- and improve upon the best known rates in both. For strongly-convex $g(\cdot, y),\ \forall y$, we propose a new algorithm combining Mirror-Prox and Nesterov's AGD, and show that it can find global optimum in $\tilde{O}(1/k^2)$ iterations, improving over current state-of-the-art rate of $O(1/k)$. We use this result along with an inexact proximal point method to provide $\tilde{O}(1/k^{1/3})$ rate for finding stationary points in the nonconvex setting where $g(\cdot, y)$ can be nonconvex. This improves over current best-known rate of $O(1/k^{1/5})$. Finally, we instantiate our result for finite nonconvex minimax problems, i.e., $\min_x \max_{1\leq i\leq m} f_i(x)$, with nonconvex $f_i(\cdot)$, to obtain convergence rate of $O(m(\log m)^{3/2}/k^{1/3})$ total gradient evaluations for finding a stationary point.
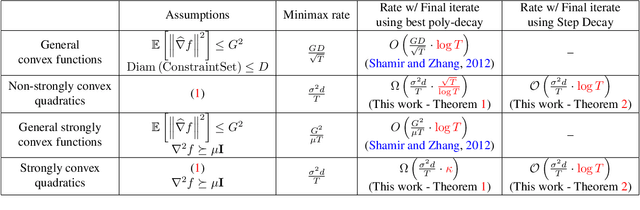
Making the Last Iterate of SGD Information Theoretically Optimal
May 29, 2019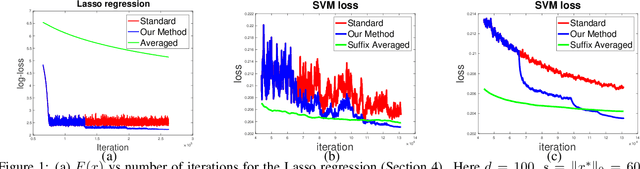
Stochastic gradient descent (SGD) is one of the most widely used algorithms for large scale optimization problems. While classical theoretical analysis of SGD for convex problems studies (suffix) \emph{averages} of iterates and obtains information theoretically optimal bounds on suboptimality, the \emph{last point} of SGD is, by far, the most preferred choice in practice. The best known results for last point of SGD \cite{shamir2013stochastic} however, are suboptimal compared to information theoretic lower bounds by a $\log T$ factor, where $T$ is the number of iterations. \cite{harvey2018tight} shows that in fact, this additional $\log T$ factor is tight for standard step size sequences of $\OTheta{\frac{1}{\sqrt{t}}}$ and $\OTheta{\frac{1}{t}}$ for non-strongly convex and strongly convex settings, respectively. Similarly, even for subgradient descent (GD) when applied to non-smooth, convex functions, the best known step-size sequences still lead to $O(\log T)$-suboptimal convergence rates (on the final iterate). The main contribution of this work is to design new step size sequences that enjoy information theoretically optimal bounds on the suboptimality of \emph{last point} of SGD as well as GD. We achieve this by designing a modification scheme, that converts one sequence of step sizes to another so that the last point of SGD/GD with modified sequence has the same suboptimality guarantees as the average of SGD/GD with original sequence. We also show that our result holds with high-probability. We validate our results through simulations which demonstrate that the new step size sequence indeed improves the final iterate significantly compared to the standard step size sequences.
The Step Decay Schedule: A Near Optimal, Geometrically Decaying Learning Rate Procedure
Apr 29, 2019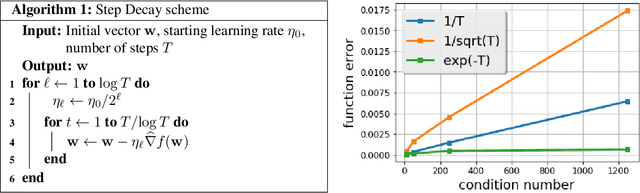

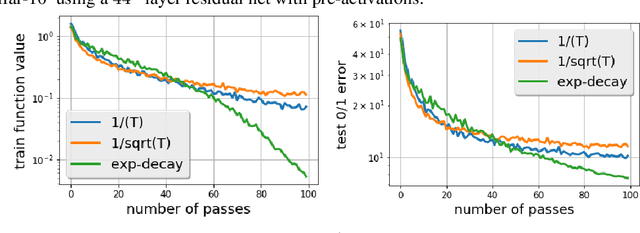
There is a stark disparity between the step size schedules used in practical large scale machine learning and those that are considered optimal by the theory of stochastic approximation. In theory, most results utilize polynomially decaying learning rate schedules, while, in practice, the "Step Decay" schedule is among the most popular schedules, where the learning rate is cut every constant number of epochs (i.e. this is a geometrically decaying schedule). This work examines the step-decay schedule for the stochastic optimization problem of streaming least squares regression (both in the non-strongly convex and strongly convex case), where we show that a sharp theoretical characterization of an optimal learning rate schedule is far more nuanced than suggested by previous work. We focus specifically on the rate that is achievable when using the final iterate of stochastic gradient descent, as is commonly done in practice. Our main result provably shows that a properly tuned geometrically decaying learning rate schedule provides an exponential improvement (in terms of the condition number) over any polynomially decaying learning rate schedule. We also provide experimental support for wider applicability of these results, including for training modern deep neural networks.
Online Non-Convex Learning: Following the Perturbed Leader is Optimal
Mar 19, 2019We study the problem of online learning with non-convex losses, where the learner has access to an offline optimization oracle. We show that the classical Follow the Perturbed Leader (FTPL) algorithm achieves optimal regret rate of $O(T^{-1/2})$ in this setting. This improves upon the previous best-known regret rate of $O(T^{-1/3})$ for FTPL. We further show that an optimistic variant of FTPL achieves better regret bounds when the sequence of losses encountered by the learner is `predictable'.
SGD without Replacement: Sharper Rates for General Smooth Convex Functions
Mar 04, 2019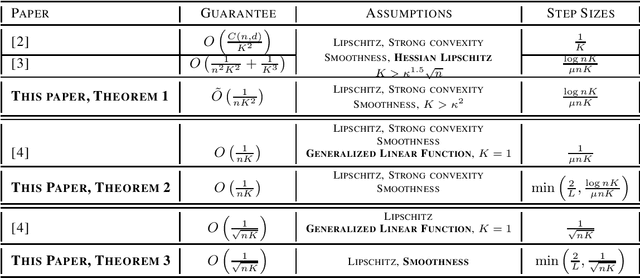
We study stochastic gradient descent {\em without replacement} (\sgdwor) for smooth convex functions. \sgdwor is widely observed to converge faster than true \sgd where each sample is drawn independently {\em with replacement}~\cite{bottou2009curiously} and hence, is more popular in practice. But it's convergence properties are not well understood as sampling without replacement leads to coupling between iterates and gradients. By using method of exchangeable pairs to bound Wasserstein distance, we provide the first non-asymptotic results for \sgdwor when applied to {\em general smooth, strongly-convex} functions. In particular, we show that \sgdwor converges at a rate of $O(1/K^2)$ while \sgd~is known to converge at $O(1/K)$ rate, where $K$ denotes the number of passes over data and is required to be {\em large enough}. Existing results for \sgdwor in this setting require additional {\em Hessian Lipschitz assumption}~\cite{gurbuzbalaban2015random,haochen2018random}. For {\em small} $K$, we show \sgdwor can achieve same convergence rate as \sgd for {\em general smooth strongly-convex} functions. Existing results in this setting require $K=1$ and hold only for generalized linear models \cite{shamir2016without}. In addition, by careful analysis of the coupling, for both large and small $K$, we obtain better dependence on problem dependent parameters like condition number.