 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDORO: Distributional and Outlier Robust Optimization
Jun 11, 2021



Many machine learning tasks involve subpopulation shift where the testing data distribution is a subpopulation of the training distribution. For such settings, a line of recent work has proposed the use of a variant of empirical risk minimization(ERM) known as distributionally robust optimization (DRO). In this work, we apply DRO to real, large-scale tasks with subpopulation shift, and observe that DRO performs relatively poorly, and moreover has severe instability. We identify one direct cause of this phenomenon: sensitivity of DRO to outliers in the datasets. To resolve this issue, we propose the framework of DORO, for Distributional and Outlier Robust Optimization. At the core of this approach is a refined risk function which prevents DRO from overfitting to potential outliers. We instantiate DORO for the Cressie-Read family of R\'enyi divergence, and delve into two specific instances of this family: CVaR and $\chi^2$-DRO. We theoretically prove the effectiveness of the proposed method, and empirically show that DORO improves the performance and stability of DRO with experiments on large modern datasets, thereby positively addressing the open question raised by Hashimoto et al., 2018.
Iterative Barycenter Flows
Apr 15, 2021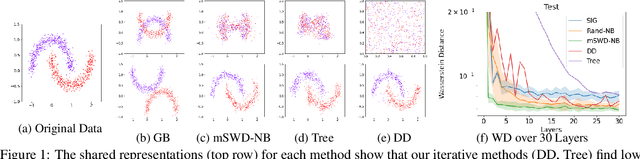
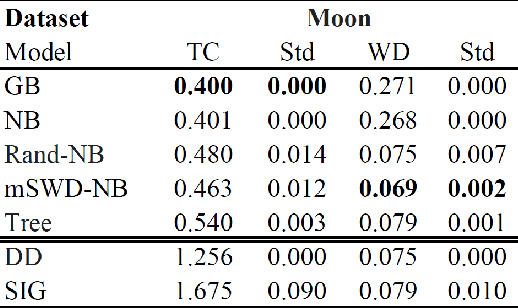

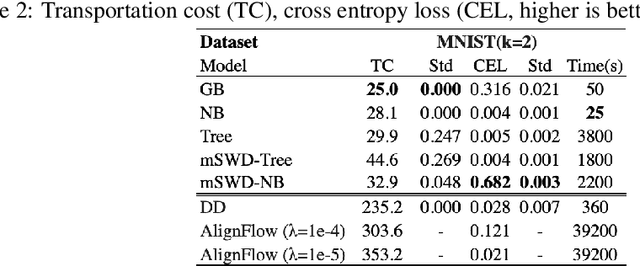
The task of mapping two or more distributions to a shared representation has many applications including fair representations, batch effect mitigation, and unsupervised domain adaptation. However, most existing formulations only consider the setting of two distributions, and moreover, do not have an identifiable, unique shared latent representation. We use optimal transport theory to consider a natural multiple distribution extension of the Monge assignment problem we call the symmetric Monge map problem and show that it is equivalent to the Wasserstein barycenter problem. Yet, the maps to the barycenter are challenging to estimate. Prior methods often ignore transportation cost, rely on adversarial methods, or only work for discrete distributions. Therefore, our goal is to estimate invertible maps between two or more distributions and their corresponding barycenter via a simple iterative flow method. Our method decouples each iteration into two subproblems: 1) estimate simple distributions and 2) estimate the invertible maps to the barycenter via known closed-form OT results. Our empirical results give evidence that this iterative algorithm approximates the maps to the barycenter.
Contrastive learning of strong-mixing continuous-time stochastic processes
Mar 03, 2021Contrastive learning is a family of self-supervised methods where a model is trained to solve a classification task constructed from unlabeled data. It has recently emerged as one of the leading learning paradigms in the absence of labels across many different domains (e.g. brain imaging, text, images). However, theoretical understanding of many aspects of training, both statistical and algorithmic, remain fairly elusive. In this work, we study the setting of time series -- more precisely, when we get data from a strong-mixing continuous-time stochastic process. We show that a properly constructed contrastive learning task can be used to estimate the transition kernel for small-to-mid-range intervals in the diffusion case. Moreover, we give sample complexity bounds for solving this task and quantitatively characterize what the value of the contrastive loss implies for distributional closeness of the learned kernel. As a byproduct, we illuminate the appropriate settings for the contrastive distribution, as well as other hyperparameters in this setup.
An Online Learning Approach to Interpolation and Extrapolation in Domain Generalization
Feb 25, 2021A popular assumption for out-of-distribution generalization is that the training data comprises sub-datasets, each drawn from a distinct distribution; the goal is then to "interpolate" these distributions and "extrapolate" beyond them -- this objective is broadly known as domain generalization. A common belief is that ERM can interpolate but not extrapolate and that the latter is considerably more difficult, but these claims are vague and lack formal justification. In this work, we recast generalization over sub-groups as an online game between a player minimizing risk and an adversary presenting new test distributions. Under an existing notion of inter- and extrapolation based on reweighting of sub-group likelihoods, we rigorously demonstrate that extrapolation is computationally much harder than interpolation, though their statistical complexity is not significantly different. Furthermore, we show that ERM -- or a noisy variant -- is provably minimax-optimal for both tasks. Our framework presents a new avenue for the formal analysis of domain generalization algorithms which may be of independent interest.
On Proximal Policy Optimization's Heavy-tailed Gradients
Feb 20, 2021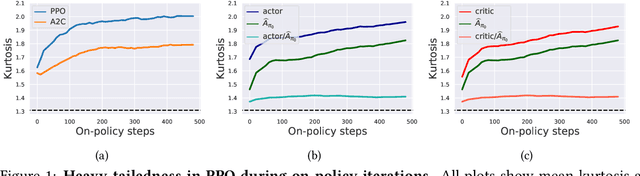
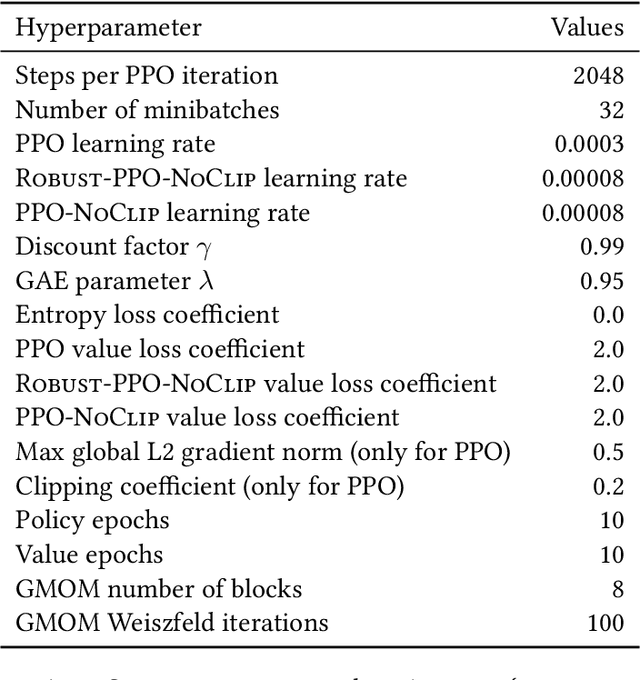
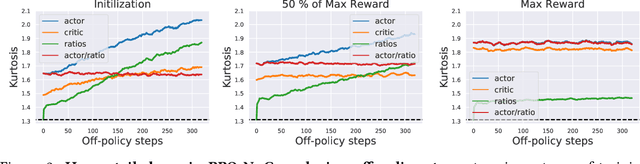
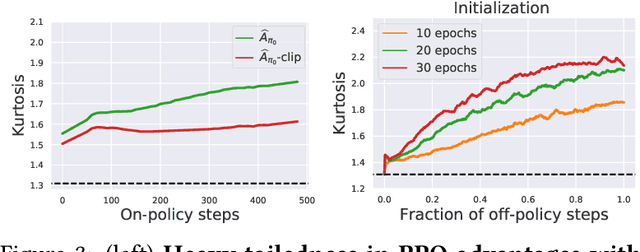
Modern policy gradient algorithms, notably Proximal Policy Optimization (PPO), rely on an arsenal of heuristics, including loss clipping and gradient clipping, to ensure successful learning. These heuristics are reminiscent of techniques from robust statistics, commonly used for estimation in outlier-rich ("heavy-tailed") regimes. In this paper, we present a detailed empirical study to characterize the heavy-tailed nature of the gradients of the PPO surrogate reward function. We demonstrate that the gradients, especially for the actor network, exhibit pronounced heavy-tailedness and that it increases as the agent's policy diverges from the behavioral policy (i.e., as the agent goes further off policy). Further examination implicates the likelihood ratios and advantages in the surrogate reward as the main sources of the observed heavy-tailedness. We then highlight issues arising due to the heavy-tailed nature of the gradients. In this light, we study the effects of the standard PPO clipping heuristics, demonstrating that these tricks primarily serve to offset heavy-tailedness in gradients. Thus motivated, we propose incorporating GMOM, a high-dimensional robust estimator, into PPO as a substitute for three clipping tricks. Despite requiring less hyperparameter tuning, our method matches the performance of PPO (with all heuristics enabled) on a battery of MuJoCo continuous control tasks.
When Is Generalizable Reinforcement Learning Tractable?
Jan 01, 2021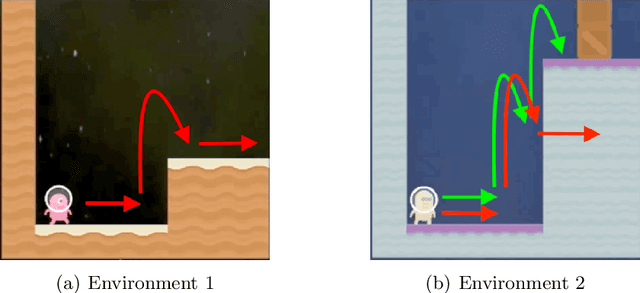
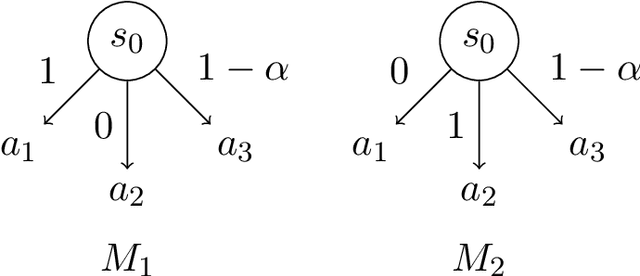
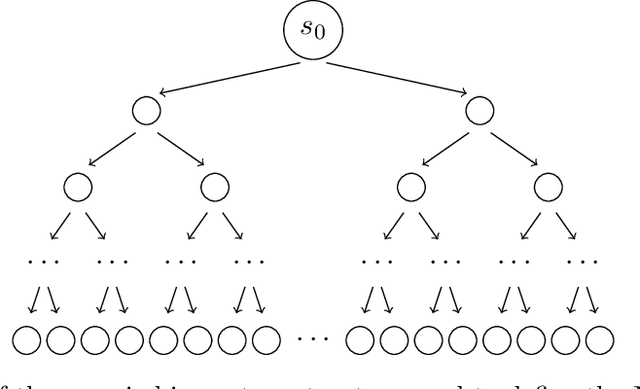
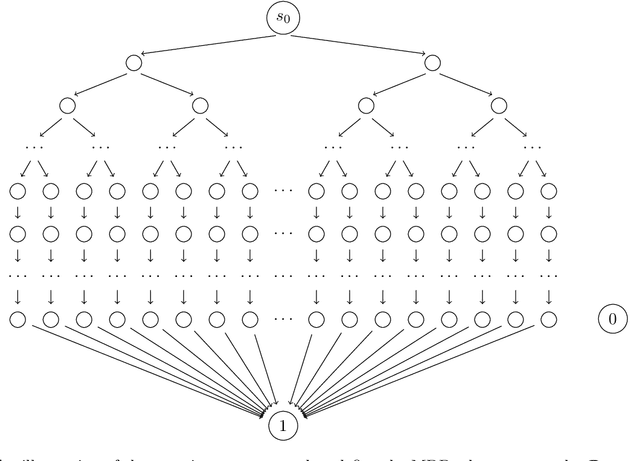
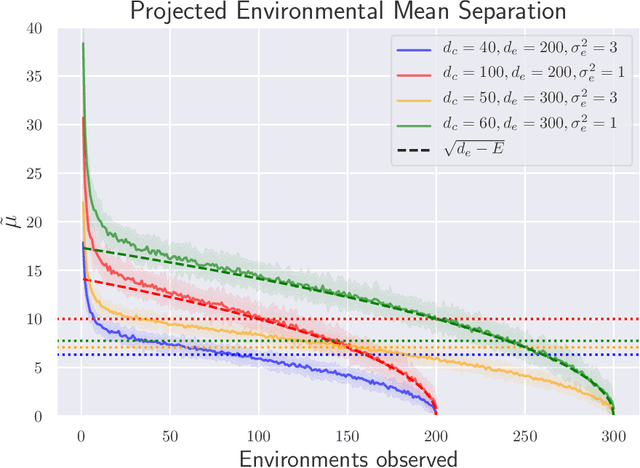
Agents trained by reinforcement learning (RL) often fail to generalize beyond the environment they were trained in, even when presented with new scenarios that seem very similar to the training environment. We study the query complexity required to train RL agents that can generalize to multiple environments. Intuitively, tractable generalization is only possible when the environments are similar or close in some sense. To capture this, we introduce Strong Proximity, a structural condition which precisely characterizes the relative closeness of different environments. We provide an algorithm which exploits Strong Proximity to provably and efficiently generalize. We also show that under a natural weakening of this condition, which we call Weak Proximity, RL can require query complexity that is exponential in the horizon to generalize. A key consequence of our theory is that even when the environments share optimal trajectories, and have highly similar reward and transition functions (as measured by classical metrics), tractable generalization is impossible.
Fundamental Limits and Tradeoffs in Invariant Representation Learning
Dec 19, 2020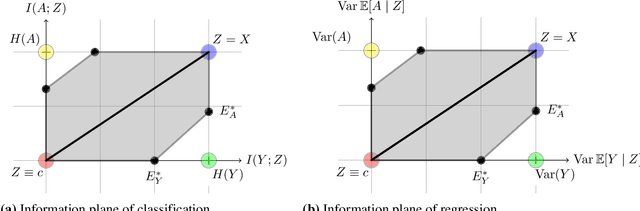
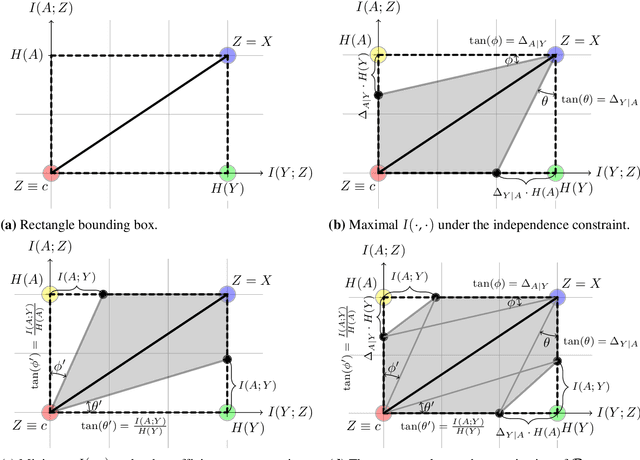
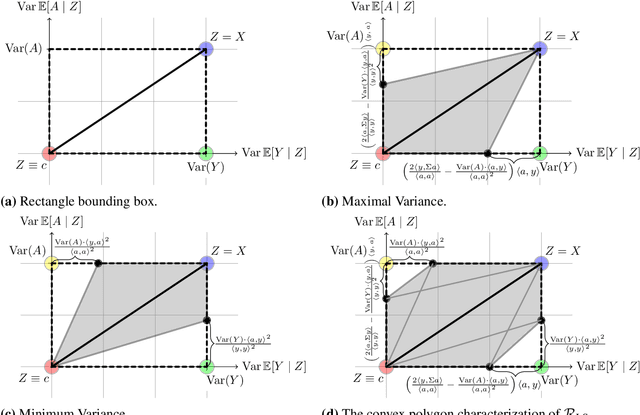
Many machine learning applications involve learning representations that achieve two competing goals: To maximize information or accuracy with respect to a subset of features (e.g.\ for prediction) while simultaneously maximizing invariance or independence with respect to another, potentially overlapping, subset of features (e.g.\ for fairness, privacy, etc). Typical examples include privacy-preserving learning, domain adaptation, and algorithmic fairness, just to name a few. In fact, all of the above problems admit a common minimax game-theoretic formulation, whose equilibrium represents a fundamental tradeoff between accuracy and invariance. Despite its abundant applications in the aforementioned domains, theoretical understanding on the limits and tradeoffs of invariant representations is severely lacking. In this paper, we provide an information-theoretic analysis of this general and important problem under both classification and regression settings. In both cases, we analyze the inherent tradeoffs between accuracy and invariance by providing a geometric characterization of the feasible region in the information plane, where we connect the geometric properties of this feasible region to the fundamental limitations of the tradeoff problem. In the regression setting, we also derive a tight lower bound on the Lagrangian objective that quantifies the tradeoff between accuracy and invariance. This lower bound leads to a better understanding of the tradeoff via the spectral properties of the joint distribution. In both cases, our results shed new light on this fundamental problem by providing insights on the interplay between accuracy and invariance. These results deepen our understanding of this fundamental problem and may be useful in guiding the design of adversarial representation learning algorithms.
The Risks of Invariant Risk Minimization
Oct 12, 2020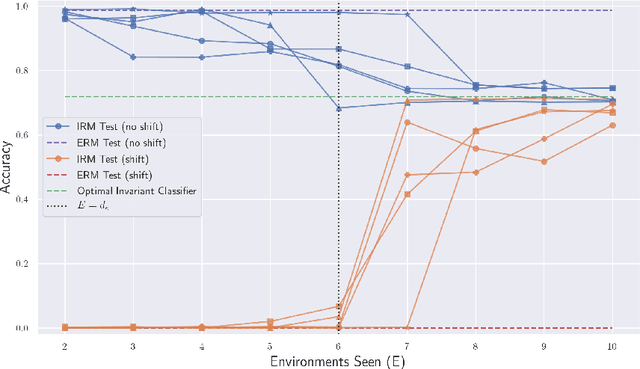
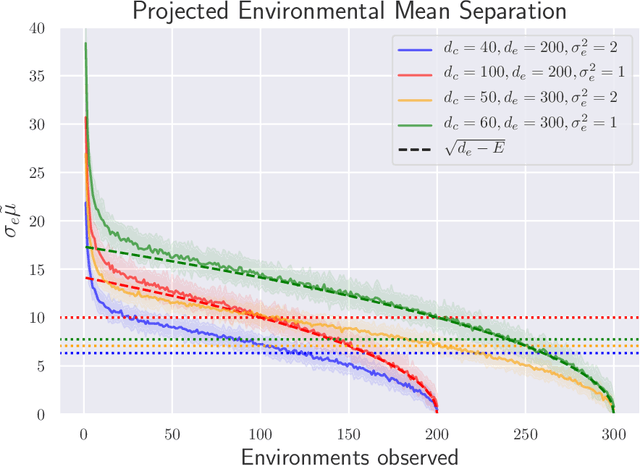
Invariant Causal Prediction (Peters et al., 2016) is a technique for out-of-distribution generalization which assumes that some aspects of the data distribution vary across the training set but that the underlying causal mechanisms remain constant. Recently, Arjovsky et al. (2019) proposed Invariant Risk Minimization (IRM), an objective based on this idea for learning deep, invariant features of data which are a complex function of latent variables; many alternatives have subsequently been suggested. However, formal guarantees for all of these works are severely lacking. In this paper, we present the first analysis of classification under the IRM objective$-$as well as these recently proposed alternatives$-$under a fairly natural and general model. In the linear case, we show simple conditions under which the optimal solution succeeds or, more often, fails to recover the optimal invariant predictor. We furthermore present the very first results in the non-linear regime: we demonstrate that IRM can fail catastrophically unless the test data are sufficiently similar to the training distribution$-$this is precisely the issue that it was intended to solve. Thus, in this setting we find that IRM and its alternatives fundamentally do not improve over standard Empirical Risk Minimization.
Sharp Statistical Guarantees for Adversarially Robust Gaussian Classification
Jun 29, 2020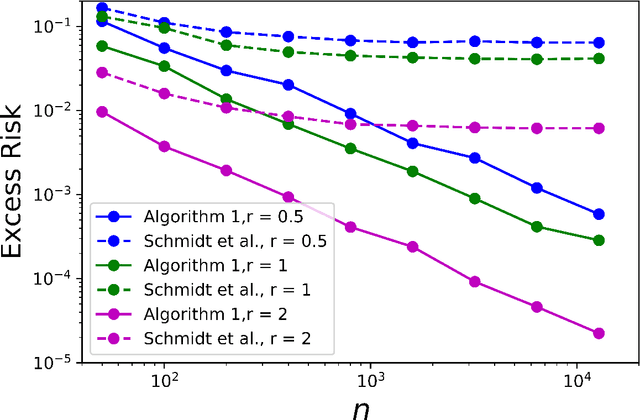
Adversarial robustness has become a fundamental requirement in modern machine learning applications. Yet, there has been surprisingly little statistical understanding so far. In this paper, we provide the first result of the optimal minimax guarantees for the excess risk for adversarially robust classification, under Gaussian mixture model proposed by \cite{schmidt2018adversarially}. The results are stated in terms of the Adversarial Signal-to-Noise Ratio (AdvSNR), which generalizes a similar notion for standard linear classification to the adversarial setting. For the Gaussian mixtures with AdvSNR value of $r$, we establish an excess risk lower bound of order $\Theta(e^{-(\frac{1}{8}+o(1)) r^2} \frac{d}{n})$ and design a computationally efficient estimator that achieves this optimal rate. Our results built upon minimal set of assumptions while cover a wide spectrum of adversarial perturbations including $\ell_p$ balls for any $p \ge 1$.
Sub-Seasonal Climate Forecasting via Machine Learning: Challenges, Analysis, and Advances
Jun 24, 2020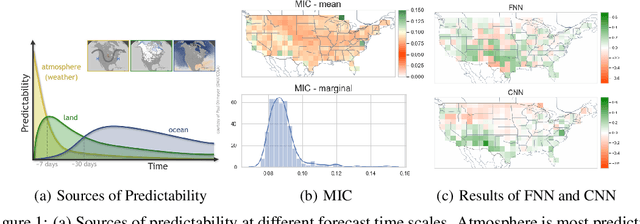
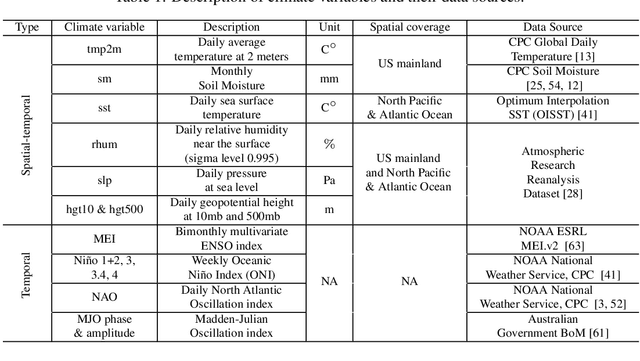
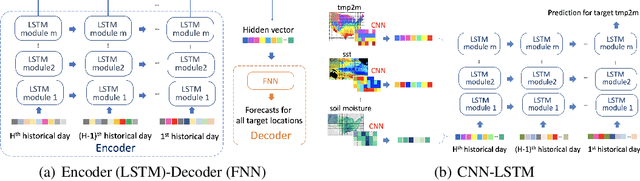
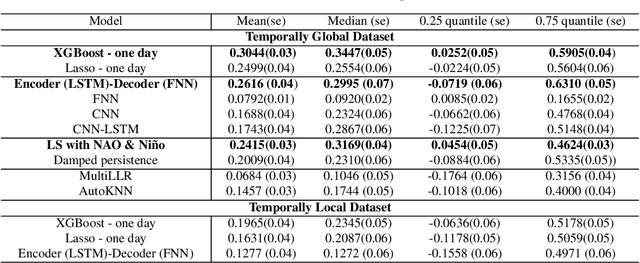
Sub-seasonal climate forecasting (SSF) focuses on predicting key climate variables such as temperature and precipitation in the 2-week to 2-month time scales. Skillful SSF would have immense societal value, in areas such as agricultural productivity, water resource management, transportation and aviation systems, and emergency planning for extreme weather events. However, SSF is considered more challenging than either weather prediction or even seasonal prediction. In this paper, we carefully study a variety of machine learning (ML) approaches for SSF over the US mainland. While atmosphere-land-ocean couplings and the limited amount of good quality data makes it hard to apply black-box ML naively, we show that with carefully constructed feature representations, even linear regression models, e.g., Lasso, can be made to perform well. Among a broad suite of 10 ML approaches considered, gradient boosting performs the best, and deep learning (DL) methods show some promise with careful architecture choices. Overall, suitable ML methods are able to outperform the climatological baseline, i.e., predictions based on the 30-year average at a given location and time. Further, based on studying feature importance, ocean (especially indices based on climatic oscillations such as El Nino) and land (soil moisture) covariates are found to be predictive, whereas atmospheric covariates are not considered helpful.