 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashionNTM: Multi-turn Fashion Image Retrieval via Cascaded Memory
Aug 20, 2023



Multi-turn textual feedback-based fashion image retrieval focuses on a real-world setting, where users can iteratively provide information to refine retrieval results until they find an item that fits all their requirements. In this work, we present a novel memory-based method, called FashionNTM, for such a multi-turn system. Our framework incorporates a new Cascaded Memory Neural Turing Machine (CM-NTM) approach for implicit state management, thereby learning to integrate information across all past turns to retrieve new images, for a given turn. Unlike vanilla Neural Turing Machine (NTM), our CM-NTM operates on multiple inputs, which interact with their respective memories via individual read and write heads, to learn complex relationships. Extensive evaluation results show that our proposed method outperforms the previous state-of-the-art algorithm by 50.5%, on Multi-turn FashionIQ -- the only existing multi-turn fashion dataset currently, in addition to having a relative improvement of 12.6% on Multi-turn Shoes -- an extension of the single-turn Shoes dataset that we created in this work. Further analysis of the model in a real-world interactive setting demonstrates two important capabilities of our model -- memory retention across turns, and agnosticity to turn order for non-contradictory feedback. Finally, user study results show that images retrieved by FashionNTM were favored by 83.1% over other multi-turn models. Project page: https://sites.google.com/eng.ucsd.edu/fashionntm
MoMo: A shared encoder Model for text, image and multi-Modal representations
Apr 11, 2023



We propose a self-supervised shared encoder model that achieves strong results on several visual, language and multimodal benchmarks while being data, memory and run-time efficient. We make three key contributions. First, in contrast to most existing works, we use a single transformer with all the encoder layers processing both the text and the image modalities. Second, we propose a stage-wise training strategy where the model is first trained on images, then jointly with unimodal text and image datasets and finally jointly with text and text-image datasets. Third, to preserve information across both the modalities, we propose a training pipeline that learns simultaneously from gradient updates of different modalities at each training update step. The results on downstream text-only, image-only and multimodal tasks show that our model is competitive with several strong models while using fewer parameters and lesser pre-training data. For example, MoMo performs competitively with FLAVA on multimodal (+3.1), image-only (+1.1) and text-only (-0.1) tasks despite having 2/5th the number of parameters and using 1/3rd the image-text training pairs. Finally, we ablate various design choices and further show that increasing model size produces significant performance gains indicating potential for substantial improvements with larger models using our approach.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022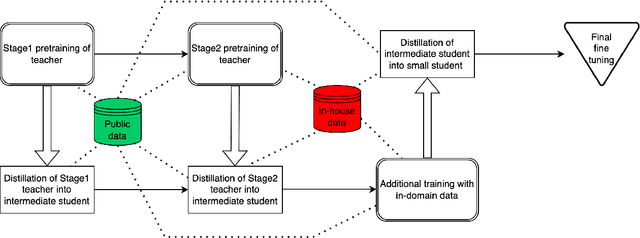
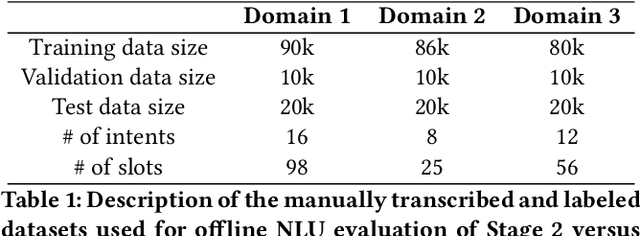
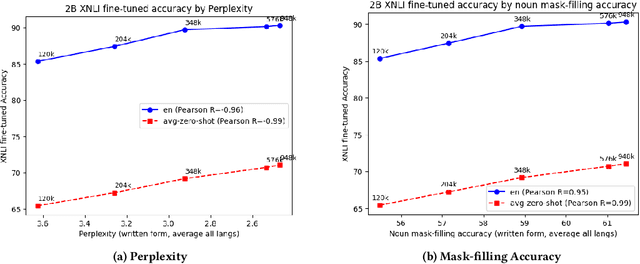
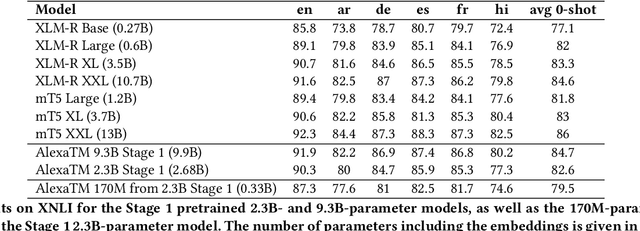
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
FewshotQA: A simple framework for few-shot learning of question answering tasks using pre-trained text-to-text models
Sep 10, 2021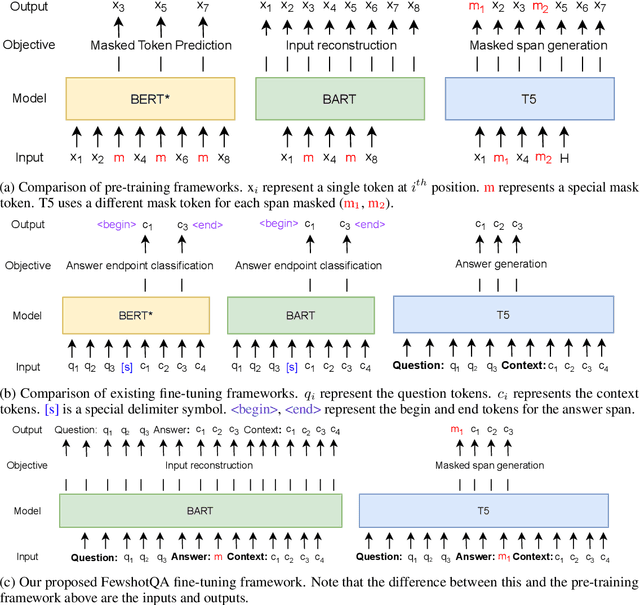
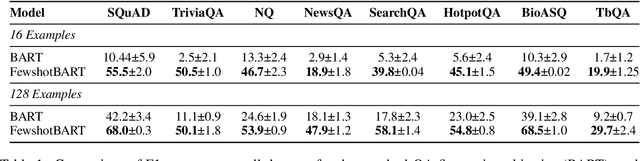

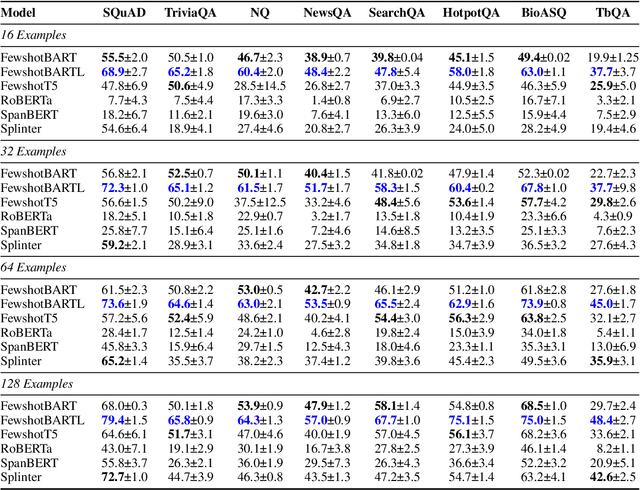
The task of learning from only a few examples (called a few-shot setting) is of key importance and relevance to a real-world setting. For question answering (QA), the current state-of-the-art pre-trained models typically need fine-tuning on tens of thousands of examples to obtain good results. Their performance degrades significantly in a few-shot setting (< 100 examples). To address this, we propose a simple fine-tuning framework that leverages pre-trained text-to-text models and is directly aligned with their pre-training framework. Specifically, we construct the input as a concatenation of the question, a mask token representing the answer span and a context. Given this input, the model is fine-tuned using the same objective as that of its pre-training objective. Through experimental studies on various few-shot configurations, we show that this formulation leads to significant gains on multiple QA benchmarks (an absolute gain of 34.2 F1 points on average when there are only 16 training examples). The gains extend further when used with larger models (Eg:- 72.3 F1 on SQuAD using BART-large with only 32 examples) and translate well to a multilingual setting . On the multilingual TydiQA benchmark, our model outperforms the XLM-Roberta-large by an absolute margin of upto 40 F1 points and an average of 33 F1 points in a few-shot setting (<= 64 training examples). We conduct detailed ablation studies to analyze factors contributing to these gains.
Error Detection in Large-Scale Natural Language Understanding Systems Using Transformer Models
Sep 04, 2021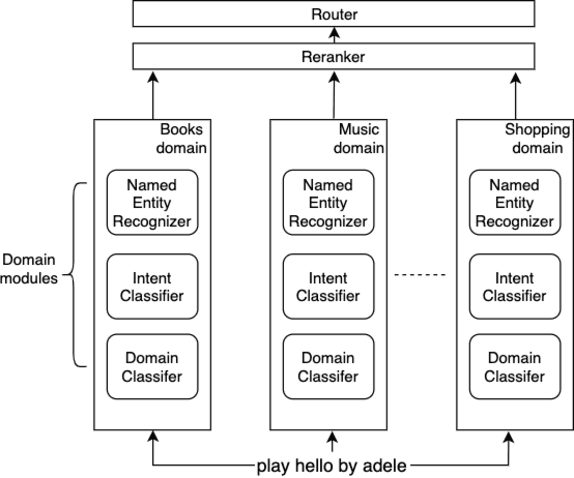
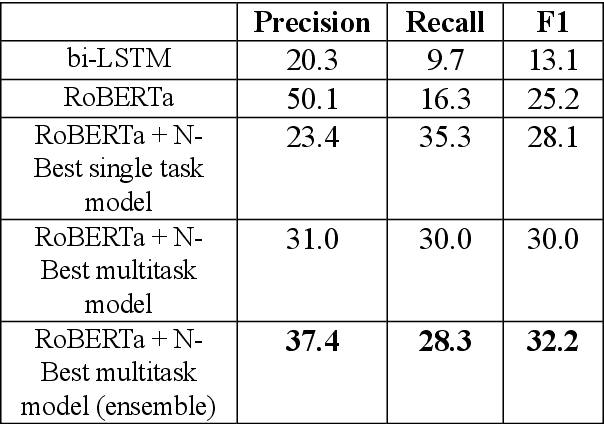
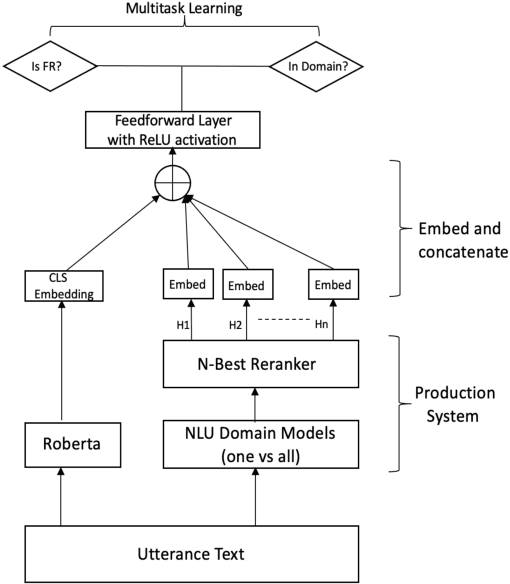
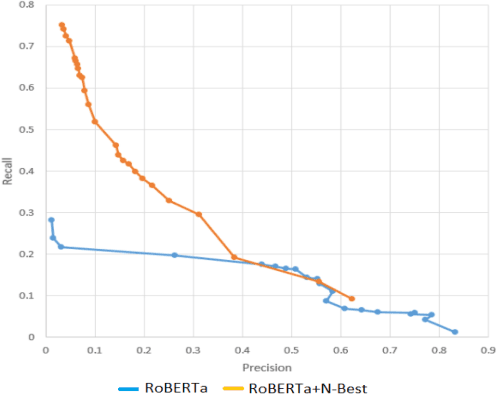
Large-scale conversational assistants like Alexa, Siri, Cortana and Google Assistant process every utterance using multiple models for domain, intent and named entity recognition. Given the decoupled nature of model development and large traffic volumes, it is extremely difficult to identify utterances processed erroneously by such systems. We address this challenge to detect domain classification errors using offline Transformer models. We combine utterance encodings from a RoBERTa model with the Nbest hypothesis produced by the production system. We then fine-tune end-to-end in a multitask setting using a small dataset of humanannotated utterances with domain classification errors. We tested our approach for detecting misclassifications from one domain that accounts for <0.5% of the traffic in a large-scale conversational AI system. Our approach achieves an F1 score of 30% outperforming a bi- LSTM baseline by 16.9% and a standalone RoBERTa model by 4.8%. We improve this further by 2.2% to 32.2% by ensembling multiple models.
Style-Aware Normalized Loss for Improving Arbitrary Style Transfer
Apr 18, 2021
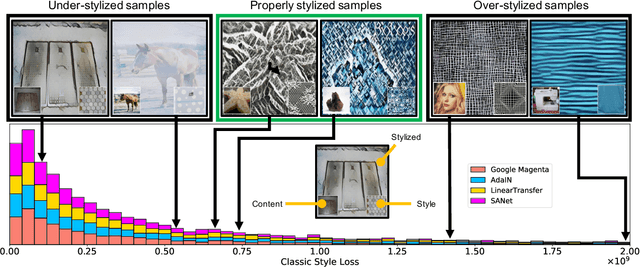
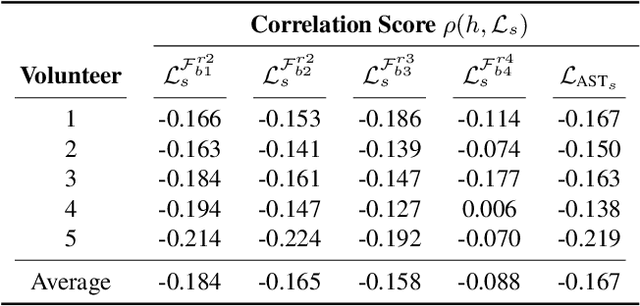
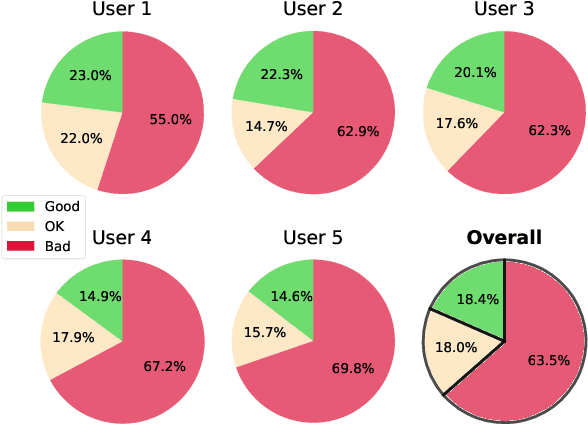
Neural Style Transfer (NST) has quickly evolved from single-style to infinite-style models, also known as Arbitrary Style Transfer (AST). Although appealing results have been widely reported in literature, our empirical studies on four well-known AST approaches (GoogleMagenta, AdaIN, LinearTransfer, and SANet) show that more than 50% of the time, AST stylized images are not acceptable to human users, typically due to under- or over-stylization. We systematically study the cause of this imbalanced style transferability (IST) and propose a simple yet effective solution to mitigate this issue. Our studies show that the IST issue is related to the conventional AST style loss, and reveal that the root cause is the equal weightage of training samples irrespective of the properties of their corresponding style images, which biases the model towards certain styles. Through investigation of the theoretical bounds of the AST style loss, we propose a new loss that largely overcomes IST. Theoretical analysis and experimental results validate the effectiveness of our loss, with over 80% relative improvement in style deception rate and 98% relatively higher preference in human evaluation.
Class-agnostic Object Detection
Nov 28, 2020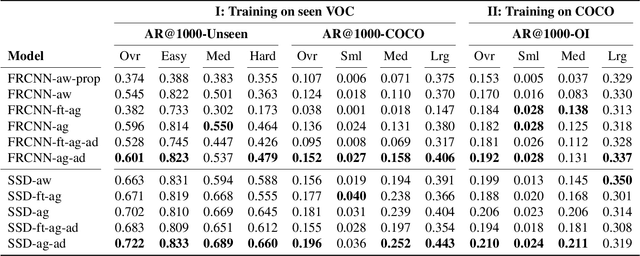
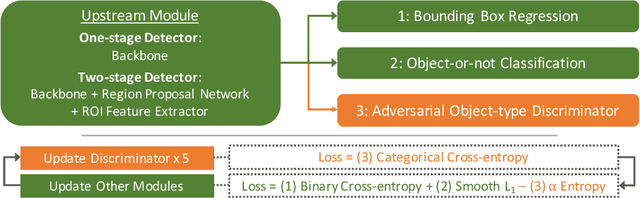
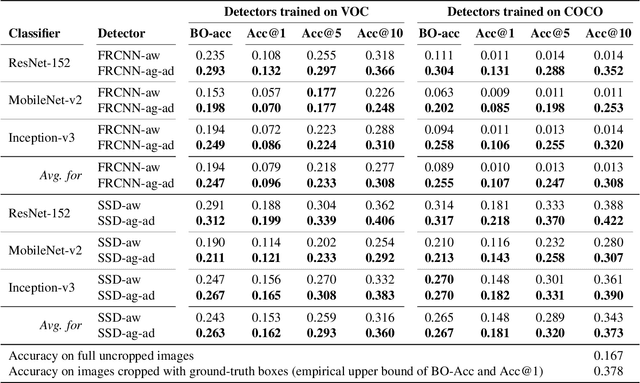
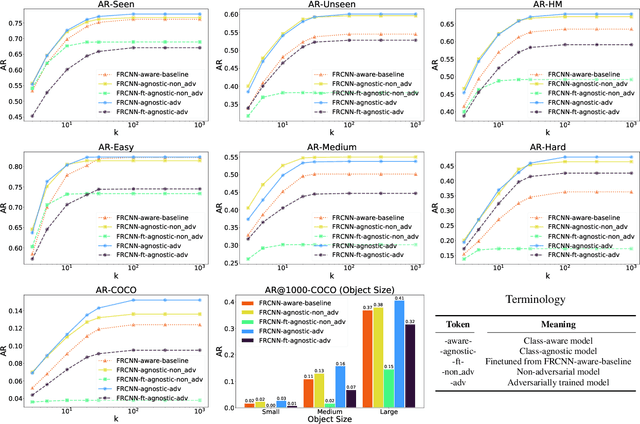
Object detection models perform well at localizing and classifying objects that they are shown during training. However, due to the difficulty and cost associated with creating and annotating detection datasets, trained models detect a limited number of object types with unknown objects treated as background content. This hinders the adoption of conventional detectors in real-world applications like large-scale object matching, visual grounding, visual relation prediction, obstacle detection (where it is more important to determine the presence and location of objects than to find specific types), etc. We propose class-agnostic object detection as a new problem that focuses on detecting objects irrespective of their object-classes. Specifically, the goal is to predict bounding boxes for all objects in an image but not their object-classes. The predicted boxes can then be consumed by another system to perform application-specific classification, retrieval, etc. We propose training and evaluation protocols for benchmarking class-agnostic detectors to advance future research in this domain. Finally, we propose (1) baseline methods and (2) a new adversarial learning framework for class-agnostic detection that forces the model to exclude class-specific information from features used for predictions. Experimental results show that adversarial learning improves class-agnostic detection efficacy.