 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Factual Grounding: The Case for Opinion-Aware Retrieval-Augmented Generation
Apr 13, 2026RAG systems have transformed how LLMs access external knowledge, but we find that current implementations exhibit a bias toward factual, objective content, as evidenced by existing benchmarks and datasets that prioritize objective retrieval. This factual bias - treating opinions and diverse perspectives as noise rather than information to be synthesized - limits RAG systems in real-world scenarios involving subjective content, from social media discussions to product reviews. Beyond technical limitations, this bias poses risks to transparent and accountable AI: echo chamber effects that amplify dominant viewpoints, systematic underrepresentation of minority voices, and potential opinion manipulation through biased information synthesis. We formalize this limitation through the lens of uncertainty: factual queries involve epistemic uncertainty reducible through evidence, while opinion queries involve aleatoric uncertainty reflecting genuine heterogeneity in human perspectives. This distinction implies that factual RAG should minimize posterior entropy, whereas opinion-aware RAG must preserve it. Building on this theoretical foundation, we present an Opinion-Aware RAG architecture featuring LLM-based opinion extraction, entity-linked opinion graphs, and opinion-enriched document indexing. We evaluate our approach on e-commerce seller forum data, comparing an Opinion-Enriched knowledge base against a traditional baseline. Experiments demonstrate substantial improvements in retrieval diversity: +26.8% sentiment diversity, +42.7% entity match rate, and +31.6% author demographic coverage on entity-matched documents. Our results provide empirical evidence that treating subjectivity as a first-class citizen yields measurably more representative retrieval-a first step toward opinion-aware RAG. Future work includes joint optimization of retrieval and generation for distributional fidelity.
Error Detection in Large-Scale Natural Language Understanding Systems Using Transformer Models
Sep 04, 2021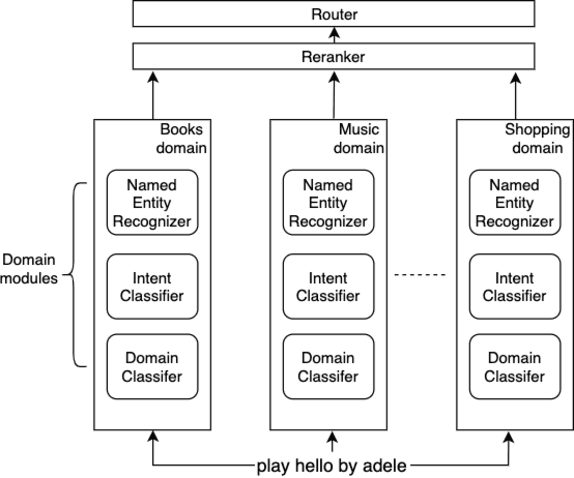
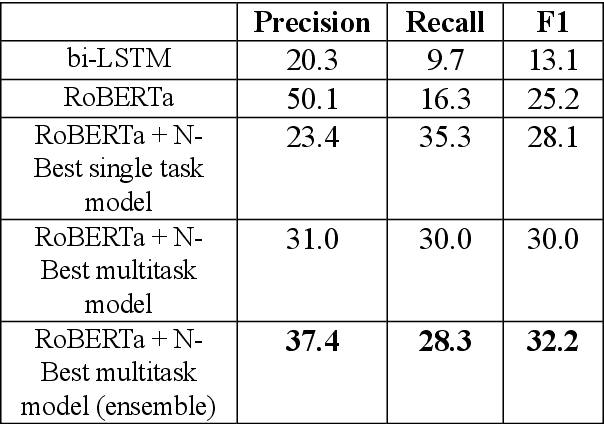
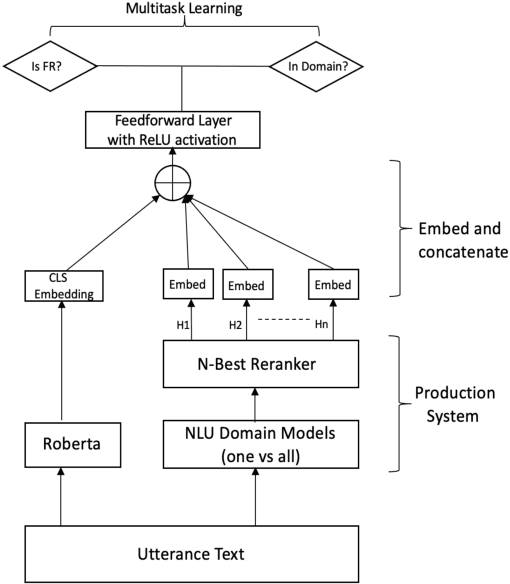
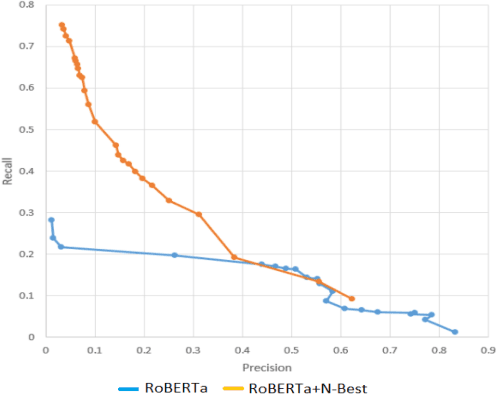
Large-scale conversational assistants like Alexa, Siri, Cortana and Google Assistant process every utterance using multiple models for domain, intent and named entity recognition. Given the decoupled nature of model development and large traffic volumes, it is extremely difficult to identify utterances processed erroneously by such systems. We address this challenge to detect domain classification errors using offline Transformer models. We combine utterance encodings from a RoBERTa model with the Nbest hypothesis produced by the production system. We then fine-tune end-to-end in a multitask setting using a small dataset of humanannotated utterances with domain classification errors. We tested our approach for detecting misclassifications from one domain that accounts for <0.5% of the traffic in a large-scale conversational AI system. Our approach achieves an F1 score of 30% outperforming a bi- LSTM baseline by 16.9% and a standalone RoBERTa model by 4.8%. We improve this further by 2.2% to 32.2% by ensembling multiple models.