 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sparse Nonparametric DAGs
Sep 29, 2019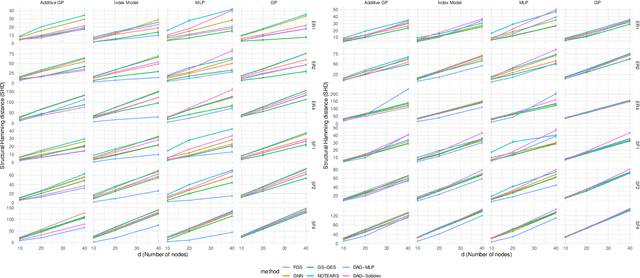

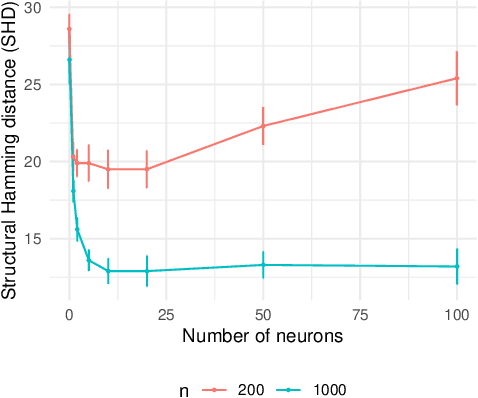

We develop a framework for learning sparse nonparametric directed acyclic graphs (DAGs) from data. Our approach is based on a recent algebraic characterization of DAGs that led to the first fully continuous optimization for score-based learning of DAG models parametrized by a linear structural equation model (SEM). We extend this algebraic characterization to nonparametric SEM by leveraging nonparametric sparsity based on partial derivatives, resulting in a continuous optimization problem that can be applied to a variety of nonparametric and semiparametric models including GLMs, additive noise models, and index models as special cases. We also explore the use of neural networks and orthogonal basis expansions to model nonlinearities for general nonparametric models. Extensive empirical study confirms the necessity of nonlinear dependency and the advantage of continuous optimization for score-based learning.
A Unified Approach to Robust Mean Estimation
Jul 01, 2019
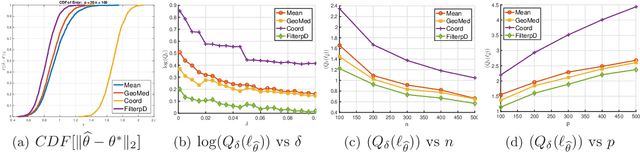
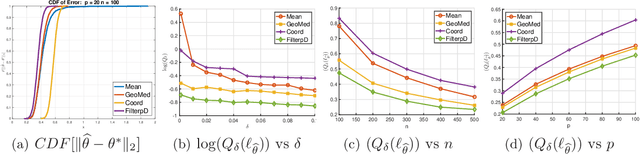
In this paper, we develop connections between two seemingly disparate, but central, models in robust statistics: Huber's epsilon-contamination model and the heavy-tailed noise model. We provide conditions under which this connection provides near-statistically-optimal estimators. Building on this connection, we provide a simple variant of recent computationally-efficient algorithms for mean estimation in Huber's model, which given our connection entails that the same efficient sample-pruning based estimators is simultaneously robust to heavy-tailed noise and Huber contamination. Furthermore, we complement our efficient algorithms with statistically-optimal albeit computationally intractable estimators, which are simultaneously optimally robust in both models. We study the empirical performance of our proposed estimators on synthetic datasets, and find that our methods convincingly outperform a variety of practical baselines.
Adaptive Hard Thresholding for Near-optimal Consistent Robust Regression
Mar 19, 2019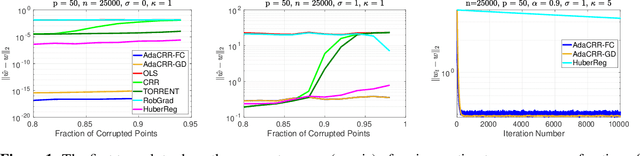

We study the problem of robust linear regression with response variable corruptions. We consider the oblivious adversary model, where the adversary corrupts a fraction of the responses in complete ignorance of the data. We provide a nearly linear time estimator which consistently estimates the true regression vector, even with $1-o(1)$ fraction of corruptions. Existing results in this setting either don't guarantee consistent estimates or can only handle a small fraction of corruptions. We also extend our estimator to robust sparse linear regression and show that similar guarantees hold in this setting. Finally, we apply our estimator to the problem of linear regression with heavy-tailed noise and show that our estimator consistently estimates the regression vector even when the noise has unbounded variance (e.g., Cauchy distribution), for which most existing results don't even apply. Our estimator is based on a novel variant of outlier removal via hard thresholding in which the threshold is chosen adaptively and crucially relies on randomness to escape bad fixed points of the non-convex hard thresholding operation.
How Sensitive are Sensitivity-Based Explanations?
Jan 27, 2019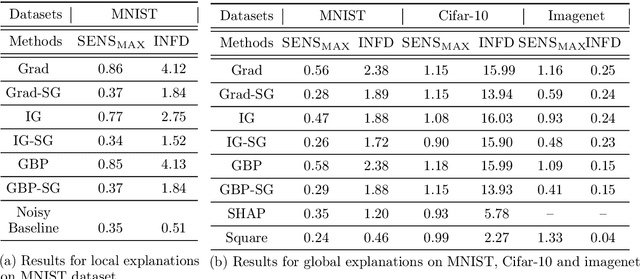
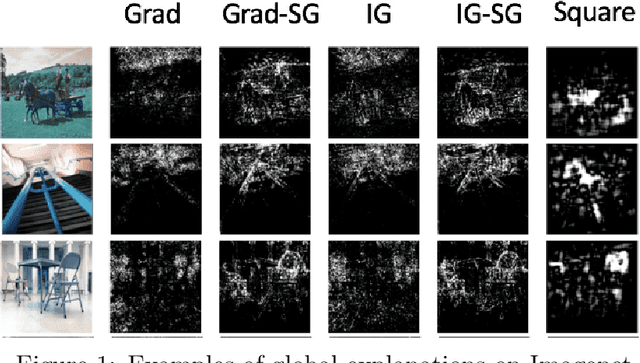
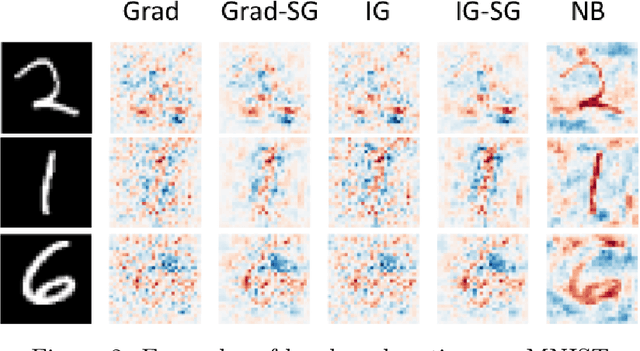
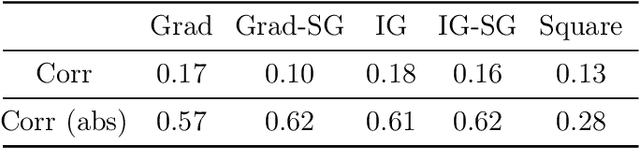
We propose a simple objective evaluation measure for explanations of a complex black-box machine learning model. While most such model explanations have largely been evaluated via qualitative measures, such as how humans might qualitatively perceive the explanations, it is vital to also consider objective measures such as the one we propose in this paper. Our evaluation measure that we naturally call sensitivity is simple: it characterizes how an explanation changes as we vary the test input, and depending on how we measure these changes, and how we vary the input, we arrive at different notions of sensitivity. We also provide a calculus for deriving sensitivity of complex explanations in terms of that for simpler explanations, which thus allows an easy computation of sensitivities for yet to be proposed explanations. One advantage of an objective evaluation measure is that we can optimize the explanation with respect to the measure: we show that (1) any given explanation can be simply modified to improve its sensitivity with just a modest deviation from the original explanation, and (2) gradient based explanations of an adversarially trained network are less sensitive. Perhaps surprisingly, our experiments show that explanations optimized to have lower sensitivity can be more faithful to the model predictions.
Towards Aggregating Weighted Feature Attributions
Jan 20, 2019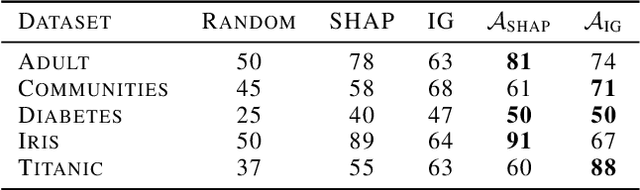
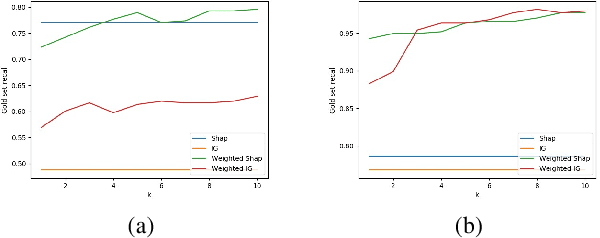
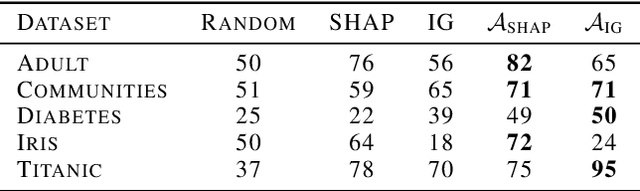
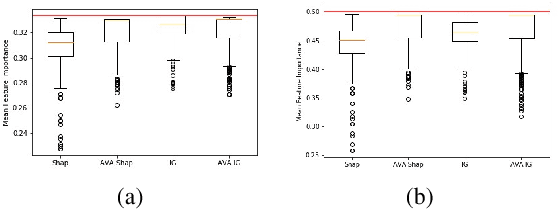
Current approaches for explaining machine learning models fall into two distinct classes: antecedent event influence and value attribution. The former leverages training instances to describe how much influence a training point exerts on a test point, while the latter attempts to attribute value to the features most pertinent to a given prediction. In this work, we discuss an algorithm, AVA: Aggregate Valuation of Antecedents, that fuses these two explanation classes to form a new approach to feature attribution that not only retrieves local explanations but also captures global patterns learned by a model. Our experimentation convincingly favors weighting and aggregating feature attributions via AVA.
Representer Point Selection for Explaining Deep Neural Networks
Nov 23, 2018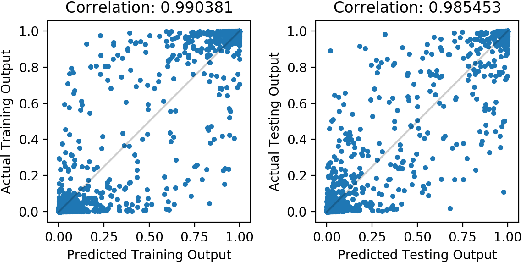

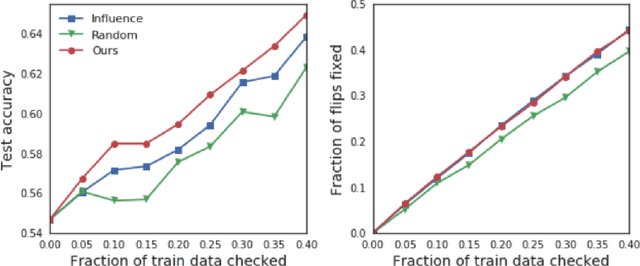

We propose to explain the predictions of a deep neural network, by pointing to the set of what we call representer points in the training set, for a given test point prediction. Specifically, we show that we can decompose the pre-activation prediction of a neural network into a linear combination of activations of training points, with the weights corresponding to what we call representer values, which thus capture the importance of that training point on the learned parameters of the network. But it provides a deeper understanding of the network than simply training point influence: with positive representer values corresponding to excitatory training points, and negative values corresponding to inhibitory points, which as we show provides considerably more insight. Our method is also much more scalable, allowing for real-time feedback in a manner not feasible with influence functions.
DAGs with NO TEARS: Continuous Optimization for Structure Learning
Nov 03, 2018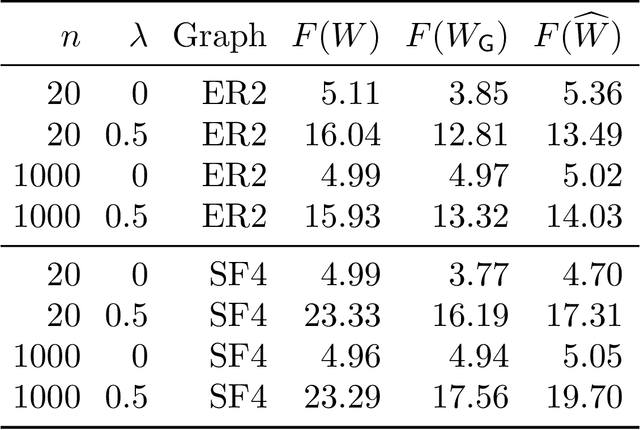
Estimating the structure of directed acyclic graphs (DAGs, also known as Bayesian networks) is a challenging problem since the search space of DAGs is combinatorial and scales superexponentially with the number of nodes. Existing approaches rely on various local heuristics for enforcing the acyclicity constraint. In this paper, we introduce a fundamentally different strategy: We formulate the structure learning problem as a purely \emph{continuous} optimization problem over real matrices that avoids this combinatorial constraint entirely. This is achieved by a novel characterization of acyclicity that is not only smooth but also exact. The resulting problem can be efficiently solved by standard numerical algorithms, which also makes implementation effortless. The proposed method outperforms existing ones, without imposing any structural assumptions on the graph such as bounded treewidth or in-degree. Code implementing the proposed algorithm is open-source and publicly available at https://github.com/xunzheng/notears.
Word Mover's Embedding: From Word2Vec to Document Embedding
Oct 30, 2018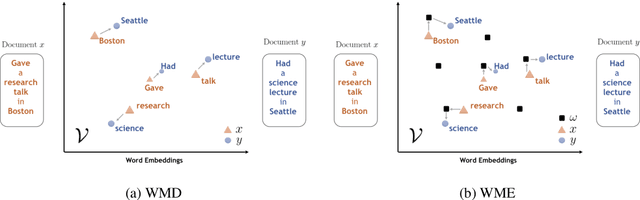
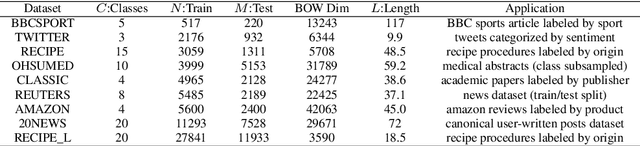
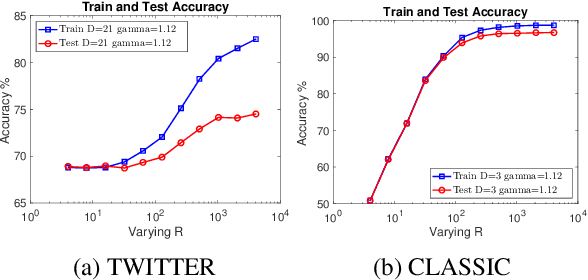
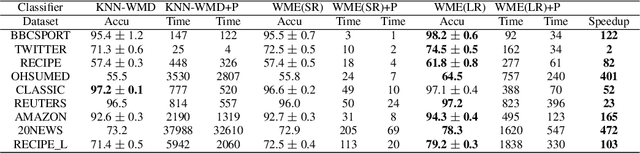
While the celebrated Word2Vec technique yields semantically rich representations for individual words, there has been relatively less success in extending to generate unsupervised sentences or documents embeddings. Recent work has demonstrated that a distance measure between documents called \emph{Word Mover's Distance} (WMD) that aligns semantically similar words, yields unprecedented KNN classification accuracy. However, WMD is expensive to compute, and it is hard to extend its use beyond a KNN classifier. In this paper, we propose the \emph{Word Mover's Embedding } (WME), a novel approach to building an unsupervised document (sentence) embedding from pre-trained word embeddings. In our experiments on 9 benchmark text classification datasets and 22 textual similarity tasks, the proposed technique consistently matches or outperforms state-of-the-art techniques, with significantly higher accuracy on problems of short length.
Learning Tensor Latent Features
Oct 10, 2018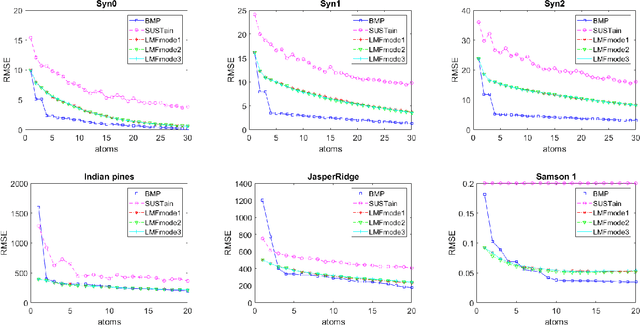

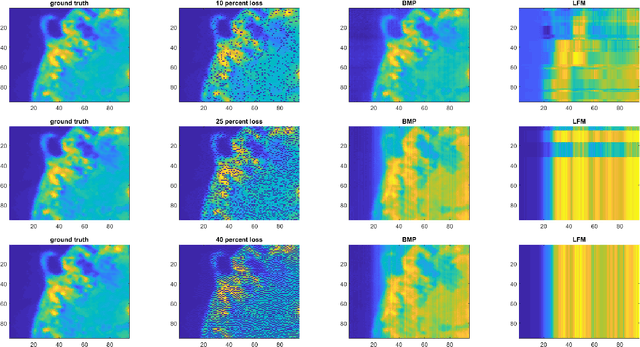
We study the problem of learning latent feature models (LFMs) for tensor data commonly observed in science and engineering such as hyperspectral imagery. However, the problem is challenging not only due to the non-convex formulation, the combinatorial nature of the constraints in LFMs, but also the high-order correlations in the data. In this work, we formulate a tensor latent feature learning problem by representing the data as a mixture of high-order latent features and binary codes, which are memory efficient and easy to interpret. To make the learning tractable, we propose a novel optimization procedure, Binary matching pursuit (BMP), that iteratively searches for binary bases via a MAXCUT-like boolean quadratic solver. Such a procedure is guaranteed to achieve an? suboptimal solution in O($1/\epsilon$) greedy steps, resulting in a trade-off between accuracy and sparsity. When evaluated on both synthetic and real datasets, our experiments show superior performance over baseline methods.
Sample Complexity of Nonparametric Semi-Supervised Learning
Sep 10, 2018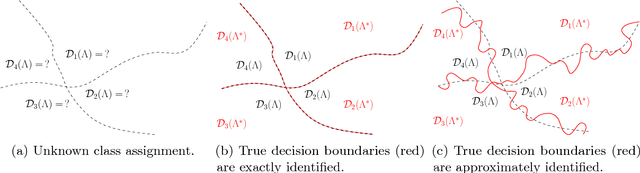
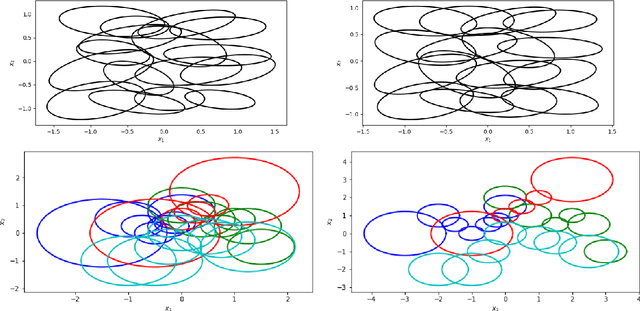
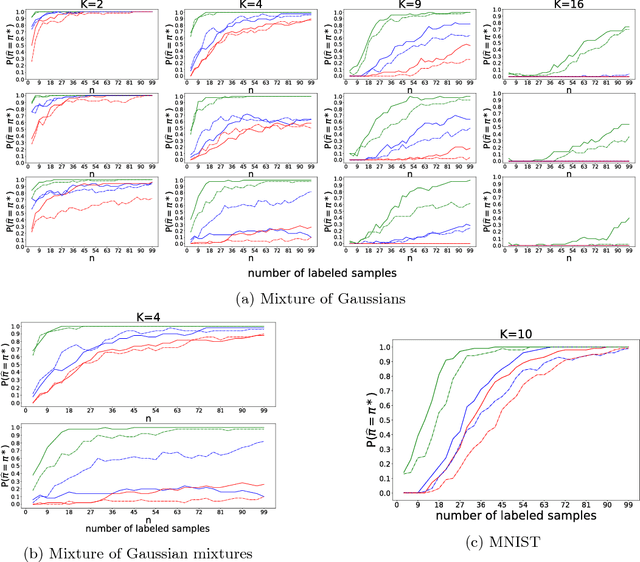
We study the sample complexity of semi-supervised learning (SSL) and introduce new assumptions based on the mismatch between a mixture model learned from unlabeled data and the true mixture model induced by the (unknown) class conditional distributions. Under these assumptions, we establish an $\Omega(K\log K)$ labeled sample complexity bound without imposing parametric assumptions, where $K$ is the number of classes. Our results suggest that even in nonparametric settings it is possible to learn a near-optimal classifier using only a few labeled samples. Unlike previous theoretical work which focuses on binary classification, we consider general multiclass classification ($K>2$), which requires solving a difficult permutation learning problem. This permutation defines a classifier whose classification error is controlled by the Wasserstein distance between mixing measures, and we provide finite-sample results characterizing the behaviour of the excess risk of this classifier. Finally, we describe three algorithms for computing these estimators based on a connection to bipartite graph matching, and perform experiments to illustrate the superiority of the MLE over the majority vote estimator.