 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLearner-LLM: Balancing Logical Grounding and Fluency in Large Language Models via Hybrid Direct Preference Optimization
May 06, 2026Direct Preference Optimization (DPO), the efficient alternative to PPO-based RLHF, falls short on knowledge-intensive generation: standard preference signals from human annotators or LLM judges exhibit a systematic verbosity bias that rewards fluency over logical correctness. This blindspot leaves a logical alignment gap -- SFT models reach NLI entailment of only 0.05-0.22 despite producing fluent text. We propose RLearner-LLM with Hybrid-DPO: an automated preference pipeline that fuses a DeBERTa-v3 NLI signal with a verifier LLM score, removing human annotation while overcoming the "alignment tax" of single-signal optimization. Evaluated across five academic domains (Biology, Medicine, Law) with three base architectures (LLaMA-2-13B, Qwen3-8B, Gemma 4 E4B-it), RLearner-LLM yields up to 6x NLI improvement over SFT, with NLI gains in 11 of 15 cells and consistent answer-coverage gains. On Gemma 4 E4B-it (4.5B effective params), Hybrid-DPO lifts NLI in four of five domains (+11.9% to +2.4x) with faster inference across all five, scaling down to compact base models without losing the alignment-tax mitigation. Our Qwen3-8B RLearner-LLM wins 95% of pairwise comparisons against its own SFT baseline; GPT-4o-mini in turn wins 95% against our concise output -- alongside the 69% win the same judge gives a verbose SFT over our DPO model, this replicates verbosity bias on a frontier comparator and motivates logic-aware metrics (NLI, ACR) over LLM-as-a-judge for knowledge-intensive generation.
HealthSLM-Bench: Benchmarking Small Language Models for Mobile and Wearable Healthcare Monitoring
Sep 08, 2025Mobile and wearable healthcare monitoring play a vital role in facilitating timely interventions, managing chronic health conditions, and ultimately improving individuals' quality of life. Previous studies on large language models (LLMs) have highlighted their impressive generalization abilities and effectiveness in healthcare prediction tasks. However, most LLM-based healthcare solutions are cloud-based, which raises significant privacy concerns and results in increased memory usage and latency. To address these challenges, there is growing interest in compact models, Small Language Models (SLMs), which are lightweight and designed to run locally and efficiently on mobile and wearable devices. Nevertheless, how well these models perform in healthcare prediction remains largely unexplored. We systematically evaluated SLMs on health prediction tasks using zero-shot, few-shot, and instruction fine-tuning approaches, and deployed the best performing fine-tuned SLMs on mobile devices to evaluate their real-world efficiency and predictive performance in practical healthcare scenarios. Our results show that SLMs can achieve performance comparable to LLMs while offering substantial gains in efficiency and privacy. However, challenges remain, particularly in handling class imbalance and few-shot scenarios. These findings highlight SLMs, though imperfect in their current form, as a promising solution for next-generation, privacy-preserving healthcare monitoring.
Word Mover's Embedding: From Word2Vec to Document Embedding
Oct 30, 2018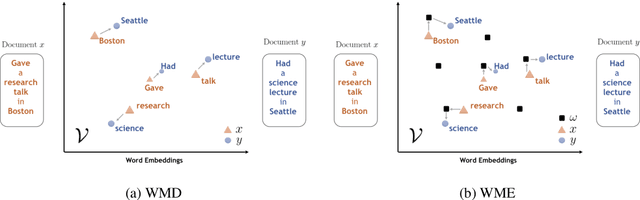
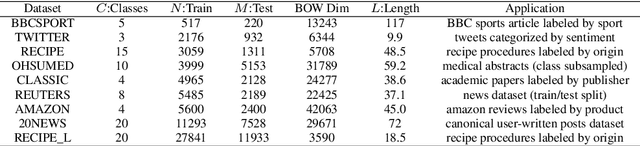
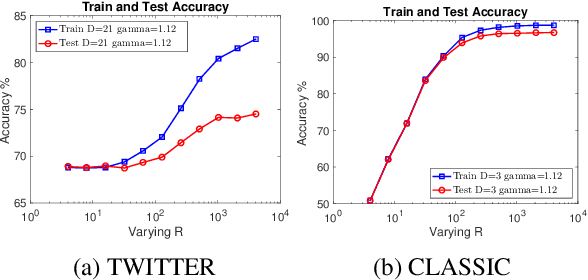
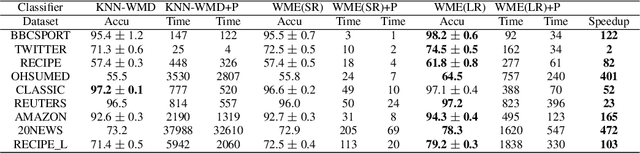
While the celebrated Word2Vec technique yields semantically rich representations for individual words, there has been relatively less success in extending to generate unsupervised sentences or documents embeddings. Recent work has demonstrated that a distance measure between documents called \emph{Word Mover's Distance} (WMD) that aligns semantically similar words, yields unprecedented KNN classification accuracy. However, WMD is expensive to compute, and it is hard to extend its use beyond a KNN classifier. In this paper, we propose the \emph{Word Mover's Embedding } (WME), a novel approach to building an unsupervised document (sentence) embedding from pre-trained word embeddings. In our experiments on 9 benchmark text classification datasets and 22 textual similarity tasks, the proposed technique consistently matches or outperforms state-of-the-art techniques, with significantly higher accuracy on problems of short length.