 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Linear Model for Knowledge Graph Embeddings
Oct 30, 2017



This paper shows that a simple baseline based on a Bag-of-Words (BoW) representation learns surprisingly good knowledge graph embeddings. By casting knowledge base completion and question answering as supervised classification problems, we observe that modeling co-occurences of entities and relations leads to state-of-the-art performance with a training time of a few minutes using the open sourced library fastText.
Learning from Video and Text via Large-Scale Discriminative Clustering
Jul 27, 2017
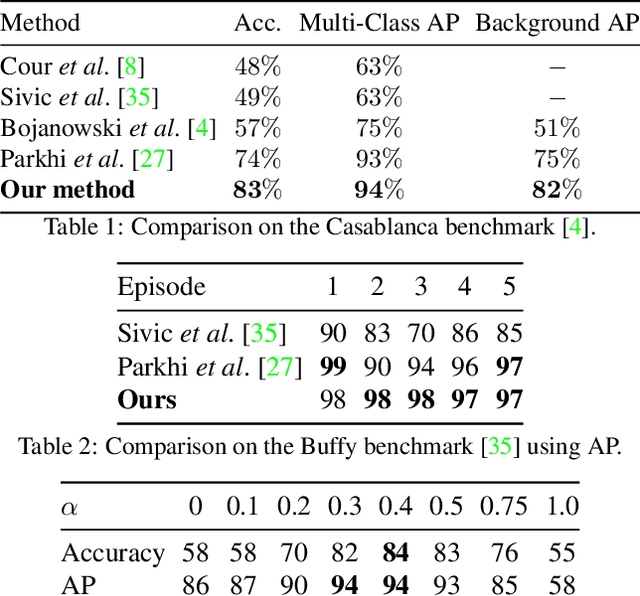
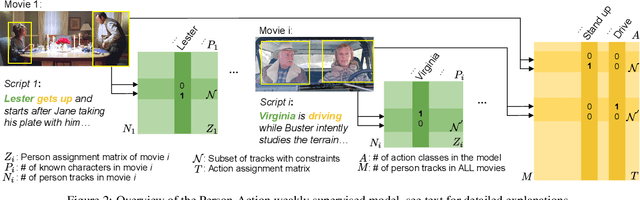
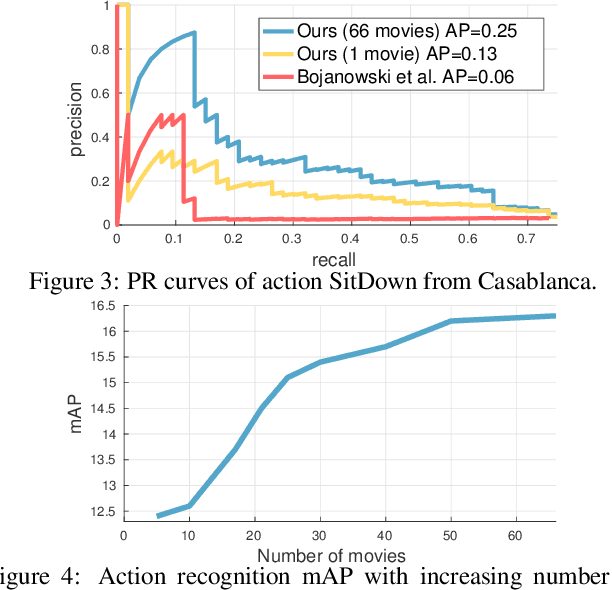
Discriminative clustering has been successfully applied to a number of weakly-supervised learning tasks. Such applications include person and action recognition, text-to-video alignment, object co-segmentation and colocalization in videos and images. One drawback of discriminative clustering, however, is its limited scalability. We address this issue and propose an online optimization algorithm based on the Block-Coordinate Frank-Wolfe algorithm. We apply the proposed method to the problem of weakly supervised learning of actions and actors from movies together with corresponding movie scripts. The scaling up of the learning problem to 66 feature length movies enables us to significantly improve weakly supervised action recognition.
Optimizing the Latent Space of Generative Networks
Jul 18, 2017
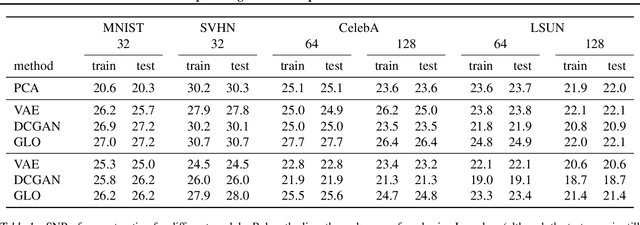


Generative Adversarial Networks (GANs) have been shown to be able to sample impressively realistic images. GAN training consists of a saddle point optimization problem that can be thought of as an adversarial game between a generator which produces the images, and a discriminator, which judges if the images are real. Both the generator and the discriminator are commonly parametrized as deep convolutional neural networks. The goal of this paper is to disentangle the contribution of the optimization procedure and the network parametrization to the success of GANs. To this end we introduce and study Generative Latent Optimization (GLO), a framework to train a generator without the need to learn a discriminator, thus avoiding challenging adversarial optimization problems. We show experimentally that GLO enjoys many of the desirable properties of GANs: learning from large data, synthesizing visually-appealing samples, interpolating meaningfully between samples, and performing linear arithmetic with noise vectors.
Enriching Word Vectors with Subword Information
Jun 19, 2017Continuous word representations, trained on large unlabeled corpora are useful for many natural language processing tasks. Popular models that learn such representations ignore the morphology of words, by assigning a distinct vector to each word. This is a limitation, especially for languages with large vocabularies and many rare words. In this paper, we propose a new approach based on the skipgram model, where each word is represented as a bag of character $n$-grams. A vector representation is associated to each character $n$-gram; words being represented as the sum of these representations. Our method is fast, allowing to train models on large corpora quickly and allows us to compute word representations for words that did not appear in the training data. We evaluate our word representations on nine different languages, both on word similarity and analogy tasks. By comparing to recently proposed morphological word representations, we show that our vectors achieve state-of-the-art performance on these tasks.
Parseval Networks: Improving Robustness to Adversarial Examples
May 02, 2017
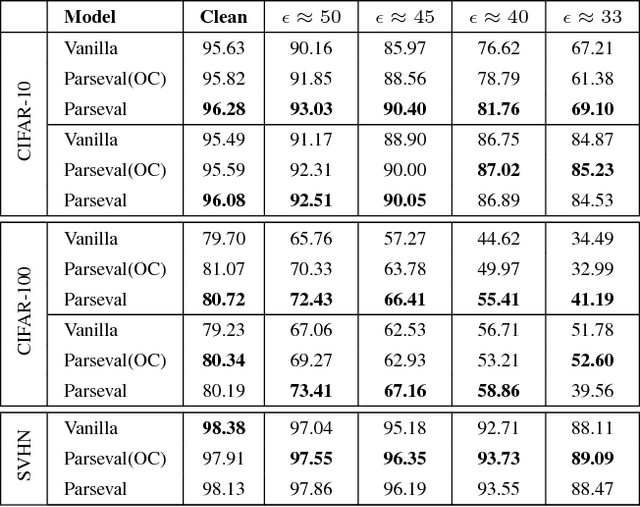
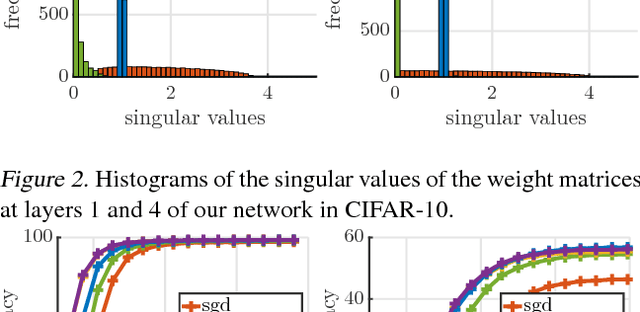
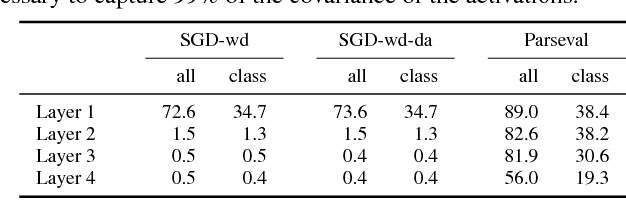
We introduce Parseval networks, a form of deep neural networks in which the Lipschitz constant of linear, convolutional and aggregation layers is constrained to be smaller than 1. Parseval networks are empirically and theoretically motivated by an analysis of the robustness of the predictions made by deep neural networks when their input is subject to an adversarial perturbation. The most important feature of Parseval networks is to maintain weight matrices of linear and convolutional layers to be (approximately) Parseval tight frames, which are extensions of orthogonal matrices to non-square matrices. We describe how these constraints can be maintained efficiently during SGD. We show that Parseval networks match the state-of-the-art in terms of accuracy on CIFAR-10/100 and Street View House Numbers (SVHN) while being more robust than their vanilla counterpart against adversarial examples. Incidentally, Parseval networks also tend to train faster and make a better usage of the full capacity of the networks.
Unsupervised Learning by Predicting Noise
Apr 18, 2017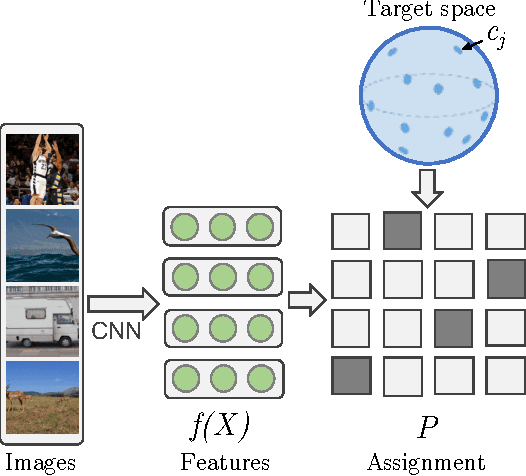

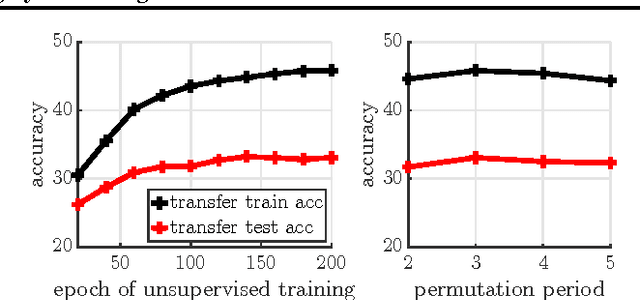
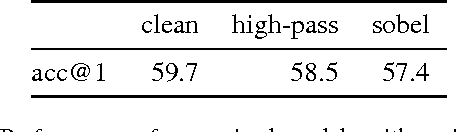
Convolutional neural networks provide visual features that perform remarkably well in many computer vision applications. However, training these networks requires significant amounts of supervision. This paper introduces a generic framework to train deep networks, end-to-end, with no supervision. We propose to fix a set of target representations, called Noise As Targets (NAT), and to constrain the deep features to align to them. This domain agnostic approach avoids the standard unsupervised learning issues of trivial solutions and collapsing of features. Thanks to a stochastic batch reassignment strategy and a separable square loss function, it scales to millions of images. The proposed approach produces representations that perform on par with state-of-the-art unsupervised methods on ImageNet and Pascal VOC.
FastText.zip: Compressing text classification models
Dec 12, 2016
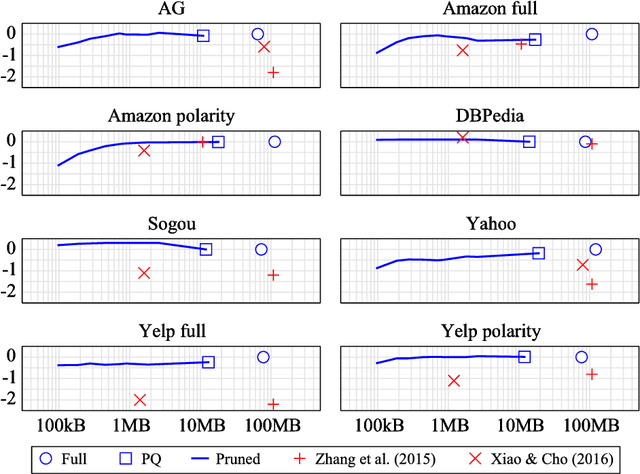
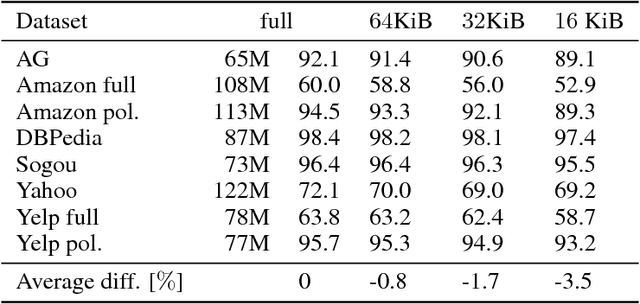
We consider the problem of producing compact architectures for text classification, such that the full model fits in a limited amount of memory. After considering different solutions inspired by the hashing literature, we propose a method built upon product quantization to store word embeddings. While the original technique leads to a loss in accuracy, we adapt this method to circumvent quantization artefacts. Our experiments carried out on several benchmarks show that our approach typically requires two orders of magnitude less memory than fastText while being only slightly inferior with respect to accuracy. As a result, it outperforms the state of the art by a good margin in terms of the compromise between memory usage and accuracy.
Bag of Tricks for Efficient Text Classification
Aug 09, 2016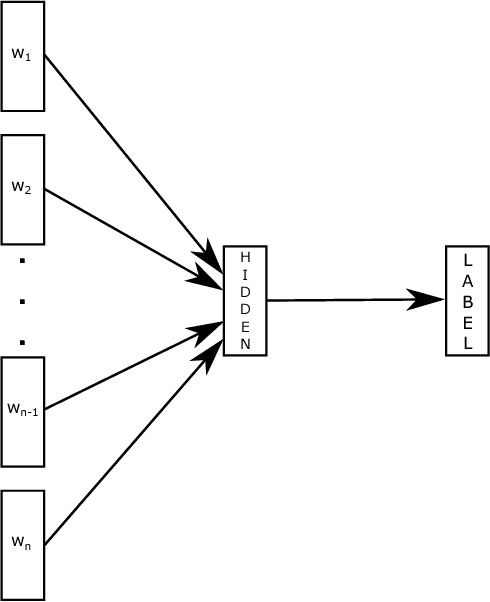
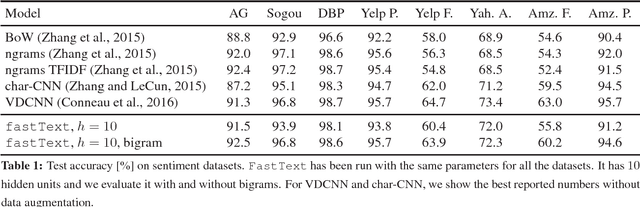
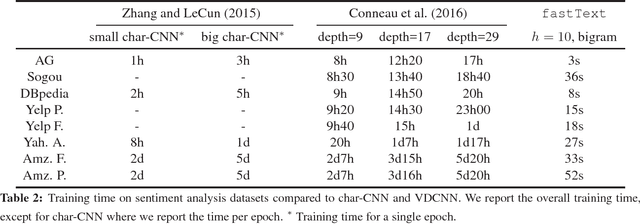
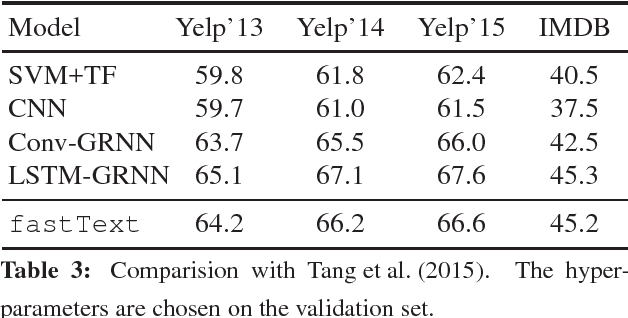
This paper explores a simple and efficient baseline for text classification. Our experiments show that our fast text classifier fastText is often on par with deep learning classifiers in terms of accuracy, and many orders of magnitude faster for training and evaluation. We can train fastText on more than one billion words in less than ten minutes using a standard multicore~CPU, and classify half a million sentences among~312K classes in less than a minute.
Unsupervised Learning from Narrated Instruction Videos
Jun 28, 2016


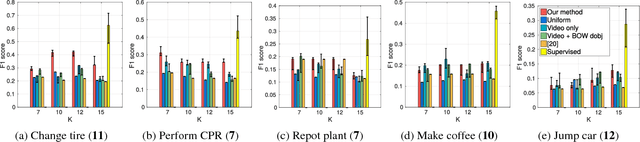
We address the problem of automatically learning the main steps to complete a certain task, such as changing a car tire, from a set of narrated instruction videos. The contributions of this paper are three-fold. First, we develop a new unsupervised learning approach that takes advantage of the complementary nature of the input video and the associated narration. The method solves two clustering problems, one in text and one in video, applied one after each other and linked by joint constraints to obtain a single coherent sequence of steps in both modalities. Second, we collect and annotate a new challenging dataset of real-world instruction videos from the Internet. The dataset contains about 800,000 frames for five different tasks that include complex interactions between people and objects, and are captured in a variety of indoor and outdoor settings. Third, we experimentally demonstrate that the proposed method can automatically discover, in an unsupervised manner, the main steps to achieve the task and locate the steps in the input videos.
Weakly-Supervised Alignment of Video With Text
Dec 21, 2015
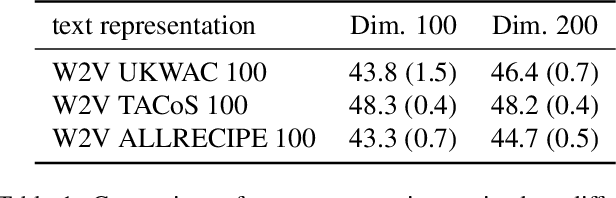
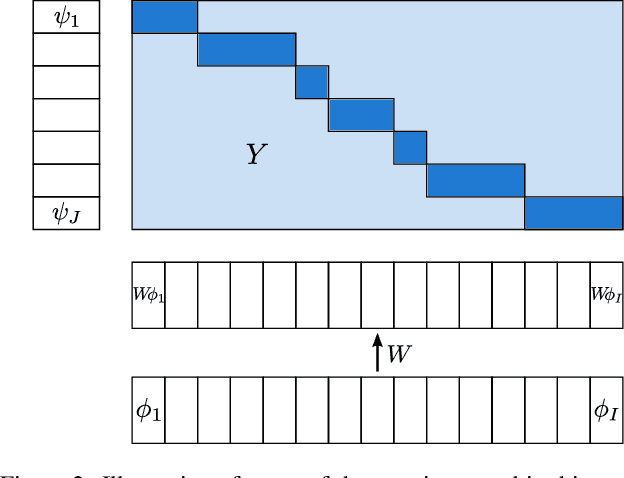
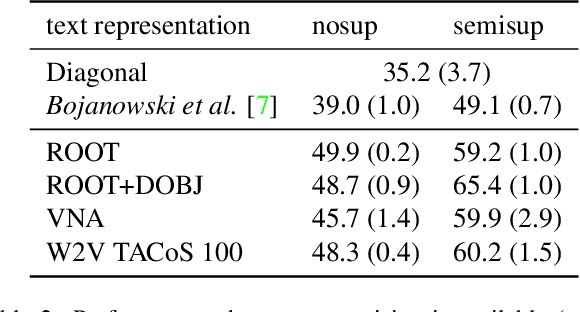
Suppose that we are given a set of videos, along with natural language descriptions in the form of multiple sentences (e.g., manual annotations, movie scripts, sport summaries etc.), and that these sentences appear in the same temporal order as their visual counterparts. We propose in this paper a method for aligning the two modalities, i.e., automatically providing a time stamp for every sentence. Given vectorial features for both video and text, we propose to cast this task as a temporal assignment problem, with an implicit linear mapping between the two feature modalities. We formulate this problem as an integer quadratic program, and solve its continuous convex relaxation using an efficient conditional gradient algorithm. Several rounding procedures are proposed to construct the final integer solution. After demonstrating significant improvements over the state of the art on the related task of aligning video with symbolic labels [7], we evaluate our method on a challenging dataset of videos with associated textual descriptions [36], using both bag-of-words and continuous representations for text.