 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinancial Bond Similarity Search Using Representation Learning
Feb 02, 2026Finding similar bonds remains challenging in fixed-income analytics, as numerical financial attributes often overshadow categorical non-financial ones such as issuer sector and domicile. This paper shows that these categorical attributes dominate the predictability of spread curves and proposes embedding models to capture their semantic similarities, outperforming one-hot and many other baselines. Evaluated via sparse-issuer augmentation, the approach improves risk modeling and curve construction.
Unsupervised Learning from Narrated Instruction Videos
Jun 28, 2016


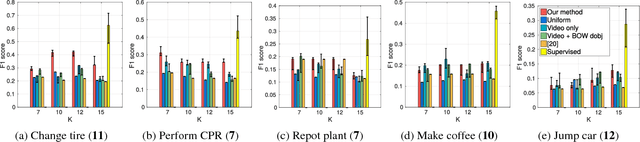
We address the problem of automatically learning the main steps to complete a certain task, such as changing a car tire, from a set of narrated instruction videos. The contributions of this paper are three-fold. First, we develop a new unsupervised learning approach that takes advantage of the complementary nature of the input video and the associated narration. The method solves two clustering problems, one in text and one in video, applied one after each other and linked by joint constraints to obtain a single coherent sequence of steps in both modalities. Second, we collect and annotate a new challenging dataset of real-world instruction videos from the Internet. The dataset contains about 800,000 frames for five different tasks that include complex interactions between people and objects, and are captured in a variety of indoor and outdoor settings. Third, we experimentally demonstrate that the proposed method can automatically discover, in an unsupervised manner, the main steps to achieve the task and locate the steps in the input videos.