 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSBMLtoODEjax: efficient simulation and optimization of ODE SBML models in JAX
Jul 17, 2023


Developing methods to explore, predict and control the dynamic behavior of biological systems, from protein pathways to complex cellular processes, is an essential frontier of research for bioengineering and biomedicine. Thus, significant effort has gone in computational inference and mathematical modeling of biological systems. This effort has resulted in the development of large collections of publicly-available models, typically stored and exchanged on online platforms (such as the BioModels Database) using the Systems Biology Markup Language (SBML), a standard format for representing mathematical models of biological systems. SBMLtoODEjax is a lightweight library that allows to automatically parse and convert SBML models into python models written end-to-end in JAX, a high-performance numerical computing library with automatic differentiation capabilities. SBMLtoODEjax is targeted at researchers that aim to incorporate SBML-specified ordinary differential equation (ODE) models into their python projects and machine learning pipelines, in order to perform efficient numerical simulation and optimization with only a few lines of code. SBMLtoODEjax is available at https://github.com/flowersteam/sbmltoodejax.
The SocialAI School: Insights from Developmental Psychology Towards Artificial Socio-Cultural Agents
Jul 15, 2023



Developmental psychologists have long-established the importance of socio-cognitive abilities in human intelligence. These abilities enable us to enter, participate and benefit from human culture. AI research on social interactive agents mostly concerns the emergence of culture in a multi-agent setting (often without a strong grounding in developmental psychology). We argue that AI research should be informed by psychology and study socio-cognitive abilities enabling to enter a culture too. We discuss the theories of Michael Tomasello and Jerome Bruner to introduce some of their concepts to AI and outline key concepts and socio-cognitive abilities. We present The SocialAI school - a tool including a customizable parameterized uite of procedurally generated environments, which simplifies conducting experiments regarding those concepts. We show examples of such experiments with RL agents and Large Language Models. The main motivation of this work is to engage the AI community around the problem of social intelligence informed by developmental psychology, and to provide a tool to simplify first steps in this direction. Refer to the project website for code and additional information: https://sites.google.com/view/socialai-school.
Large Language Models as Superpositions of Cultural Perspectives
Jul 15, 2023



Large Language Models (LLMs) are often misleadingly recognized as having a personality or a set of values. We argue that an LLM can be seen as a superposition of perspectives with different values and personality traits. LLMs exhibit context-dependent values and personality traits that change based on the induced perspective (as opposed to humans, who tend to have more coherent values and personality traits across contexts). We introduce the concept of perspective controllability, which refers to a model's affordance to adopt various perspectives with differing values and personality traits. In our experiments, we use questionnaires from psychology (PVQ, VSM, IPIP) to study how exhibited values and personality traits change based on different perspectives. Through qualitative experiments, we show that LLMs express different values when those are (implicitly or explicitly) implied in the prompt, and that LLMs express different values even when those are not obviously implied (demonstrating their context-dependent nature). We then conduct quantitative experiments to study the controllability of different models (GPT-4, GPT-3.5, OpenAssistant, StableVicuna, StableLM), the effectiveness of various methods for inducing perspectives, and the smoothness of the models' drivability. We conclude by examining the broader implications of our work and outline a variety of associated scientific questions. The project website is available at https://sites.google.com/view/llm-superpositions .
Augmenting Autotelic Agents with Large Language Models
May 21, 2023Humans learn to master open-ended repertoires of skills by imagining and practicing their own goals. This autotelic learning process, literally the pursuit of self-generated (auto) goals (telos), becomes more and more open-ended as the goals become more diverse, abstract and creative. The resulting exploration of the space of possible skills is supported by an inter-individual exploration: goal representations are culturally evolved and transmitted across individuals, in particular using language. Current artificial agents mostly rely on predefined goal representations corresponding to goal spaces that are either bounded (e.g. list of instructions), or unbounded (e.g. the space of possible visual inputs) but are rarely endowed with the ability to reshape their goal representations, to form new abstractions or to imagine creative goals. In this paper, we introduce a language model augmented autotelic agent (LMA3) that leverages a pretrained language model (LM) to support the representation, generation and learning of diverse, abstract, human-relevant goals. The LM is used as an imperfect model of human cultural transmission; an attempt to capture aspects of humans' common-sense, intuitive physics and overall interests. Specifically, it supports three key components of the autotelic architecture: 1)~a relabeler that describes the goals achieved in the agent's trajectories, 2)~a goal generator that suggests new high-level goals along with their decomposition into subgoals the agent already masters, and 3)~reward functions for each of these goals. Without relying on any hand-coded goal representations, reward functions or curriculum, we show that LMA3 agents learn to master a large diversity of skills in a task-agnostic text-based environment.
Supporting Qualitative Analysis with Large Language Models: Combining Codebook with GPT-3 for Deductive Coding
Apr 17, 2023Qualitative analysis of textual contents unpacks rich and valuable information by assigning labels to the data. However, this process is often labor-intensive, particularly when working with large datasets. While recent AI-based tools demonstrate utility, researchers may not have readily available AI resources and expertise, let alone be challenged by the limited generalizability of those task-specific models. In this study, we explored the use of large language models (LLMs) in supporting deductive coding, a major category of qualitative analysis where researchers use pre-determined codebooks to label the data into a fixed set of codes. Instead of training task-specific models, a pre-trained LLM could be used directly for various tasks without fine-tuning through prompt learning. Using a curiosity-driven questions coding task as a case study, we found, by combining GPT-3 with expert-drafted codebooks, our proposed approach achieved fair to substantial agreements with expert-coded results. We lay out challenges and opportunities in using LLMs to support qualitative coding and beyond.
A Song of Ice and Fire: Analyzing Textual Autotelic Agents in ScienceWorld
Feb 24, 2023



Building open-ended agents that can autonomously discover a diversity of behaviours is one of the long-standing goals of artificial intelligence. This challenge can be studied in the framework of autotelic RL agents, i.e. agents that learn by selecting and pursuing their own goals, self-organizing a learning curriculum. Recent work identified language as a key dimension of autotelic learning, in particular because it enables abstract goal sampling and guidance from social peers for hindsight relabelling. Within this perspective, we study the following open scientific questions: What is the impact of hindsight feedback from a social peer (e.g. selective vs. exhaustive)? How can the agent learn from very rare language goal examples in its experience replay? How can multiple forms of exploration be combined, and take advantage of easier goals as stepping stones to reach harder ones? To address these questions, we use ScienceWorld, a textual environment with rich abstract and combinatorial physics. We show the importance of selectivity from the social peer's feedback; that experience replay needs to over-sample examples of rare goals; and that following self-generated goal sequences where the agent's competence is intermediate leads to significant improvements in final performance.
Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning
Feb 06, 2023



Recent works successfully leveraged Large Language Models' (LLM) abilities to capture abstract knowledge about world's physics to solve decision-making problems. Yet, the alignment between LLMs' knowledge and the environment can be wrong and limit functional competence due to lack of grounding. In this paper, we study an approach to achieve this alignment through functional grounding: we consider an agent using an LLM as a policy that is progressively updated as the agent interacts with the environment, leveraging online Reinforcement Learning to improve its performance to solve goals. Using an interactive textual environment designed to study higher-level forms of functional grounding, and a set of spatial and navigation tasks, we study several scientific questions: 1) Can LLMs boost sample efficiency for online learning of various RL tasks? 2) How can it boost different forms of generalization? 3) What is the impact of online learning? We study these questions by functionally grounding several variants (size, architecture) of FLAN-T5.
Flow Lenia: Mass conservation for the study of virtual creatures in continuous cellular automata
Dec 14, 2022



Lenia is a family of cellular automata (CA) generalizing Conway's Game of Life to continuous space, time and states. Lenia has attracted a lot of attention because of the wide diversity of self-organizing patterns it can generate. Among those, some spatially localized patterns (SLPs) resemble life-like artificial creatures. However, those creatures are found in only a small subspace of the Lenia parameter space and are not trivial to discover, necessitating advanced search algorithms. We hypothesize that adding a mass conservation constraint could facilitate the emergence of SLPs. We propose here an extension of the Lenia model, called Flow Lenia, which enables mass conservation. We show a few observations demonstrating its effectiveness in generating SLPs with complex behaviors. Furthermore, we show how Flow Lenia enables the integration of the parameters of the CA update rules within the CA dynamics, making them dynamic and localized. This allows for multi-species simulations, with locally coherent update rules that define properties of the emerging creatures, and that can be mixed with neighbouring rules. We argue that this paves the way for the intrinsic evolution of self-organized artificial life forms within continuous CAs.
GPT-3-driven pedagogical agents for training children's curious question-asking skills
Dec 08, 2022Students' ability to ask curious questions is a crucial skill that improves their learning processes. To train this skill, previous research has used a conversational agent that propose specific cues to prompt children's curiosity during learning. Despite showing pedagogical efficiency, this method is still limited since it relies on generating the said prompts by hand for each educational resource, which can be a very long and costly process. In this context, we leverage the advances in the natural language processing field and explore using a large language model (GPT-3) to automate the generation of this agent's curiosity-prompting cues to help children ask more and deeper questions. We then used this study to investigate a different curiosity-prompting behavior for the agent. The study was conducted with 75 students aged between 9 and 10. They either interacted with a hand-crafted conversational agent that proposes "closed" manually-extracted cues leading to predefined questions, a GPT-3-driven one that proposes the same type of cues, or a GPT-3-driven one that proposes "open" cues that can lead to several possible questions. Results showed a similar question-asking performance between children who had the two "closed" agents, but a significantly better one for participants with the "open" agent. Our first results suggest the validity of using GPT-3 to facilitate the implementation of curiosity-stimulating learning technologies. In a second step, we also show that GPT-3 can be efficient in proposing the relevant open cues that leave children with more autonomy to express their curiosity.
Selecting Better Samples from Pre-trained LLMs: A Case Study on Question Generation
Sep 22, 2022
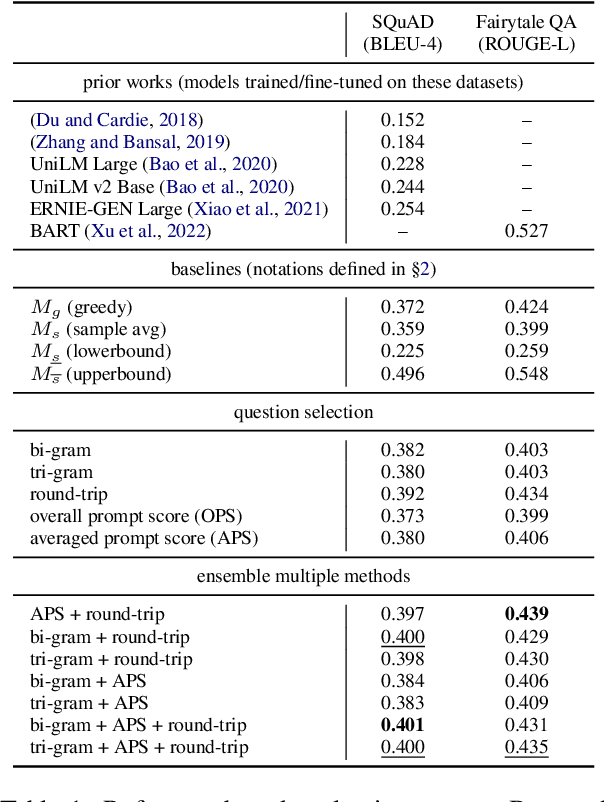
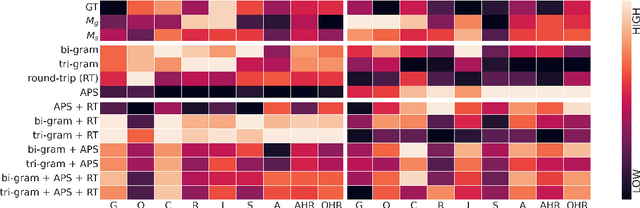
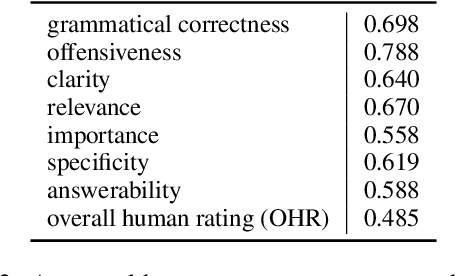
Large Language Models (LLMs) have in recent years demonstrated impressive prowess in natural language generation. A common practice to improve generation diversity is to sample multiple outputs from the model. However, there lacks a simple and robust way of selecting the best output from these stochastic samples. As a case study framed in the context of question generation, we propose two prompt-based approaches to selecting high-quality questions from a set of LLM-generated candidates. Our method works under the constraints of 1) a black-box (non-modifiable) question generation model and 2) lack of access to human-annotated references -- both of which are realistic limitations for real-world deployment of LLMs. With automatic as well as human evaluations, we empirically demonstrate that our approach can effectively select questions of higher qualities than greedy generation.