 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Biological Sequences via Meta-Reinforcement Learning and Bayesian Optimization
Sep 13, 2022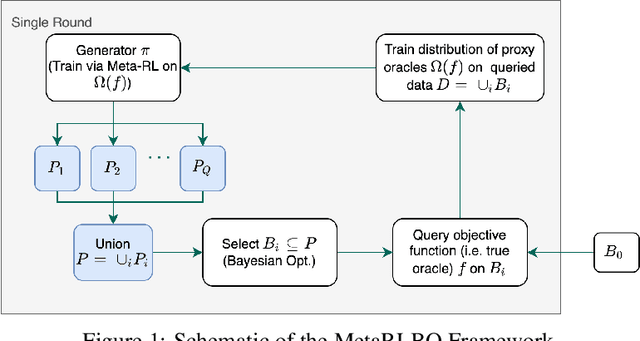
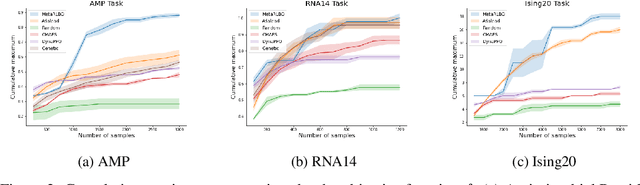
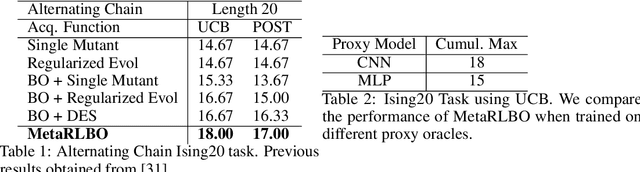
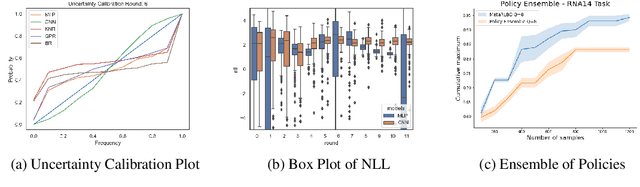
The ability to accelerate the design of biological sequences can have a substantial impact on the progress of the medical field. The problem can be framed as a global optimization problem where the objective is an expensive black-box function such that we can query large batches restricted with a limitation of a low number of rounds. Bayesian Optimization is a principled method for tackling this problem. However, the astronomically large state space of biological sequences renders brute-force iterating over all possible sequences infeasible. In this paper, we propose MetaRLBO where we train an autoregressive generative model via Meta-Reinforcement Learning to propose promising sequences for selection via Bayesian Optimization. We pose this problem as that of finding an optimal policy over a distribution of MDPs induced by sampling subsets of the data acquired in the previous rounds. Our in-silico experiments show that meta-learning over such ensembles provides robustness against reward misspecification and achieves competitive results compared to existing strong baselines.
The Primacy Bias in Deep Reinforcement Learning
May 16, 2022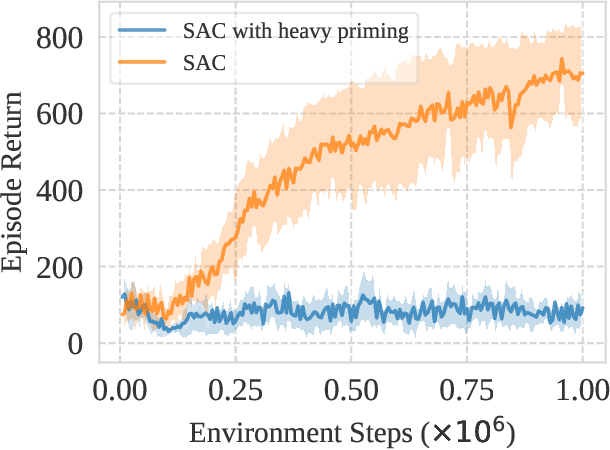
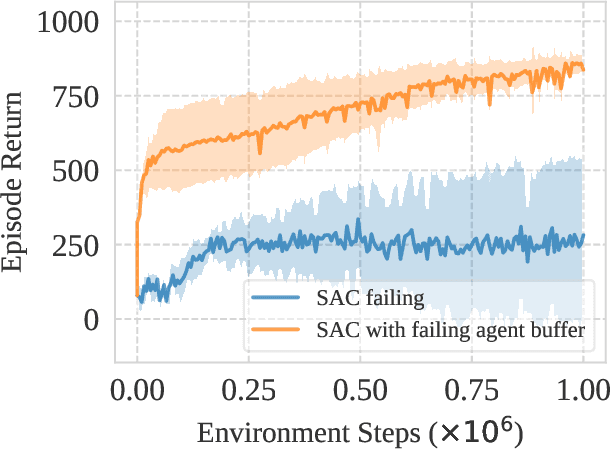
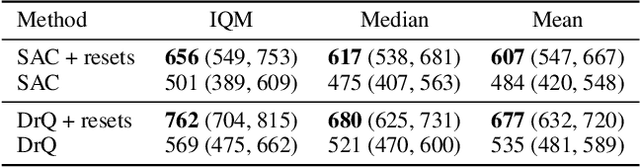

This work identifies a common flaw of deep reinforcement learning (RL) algorithms: a tendency to rely on early interactions and ignore useful evidence encountered later. Because of training on progressively growing datasets, deep RL agents incur a risk of overfitting to earlier experiences, negatively affecting the rest of the learning process. Inspired by cognitive science, we refer to this effect as the primacy bias. Through a series of experiments, we dissect the algorithmic aspects of deep RL that exacerbate this bias. We then propose a simple yet generally-applicable mechanism that tackles the primacy bias by periodically resetting a part of the agent. We apply this mechanism to algorithms in both discrete (Atari 100k) and continuous action (DeepMind Control Suite) domains, consistently improving their performance.
Continuous-Time Meta-Learning with Forward Mode Differentiation
Mar 02, 2022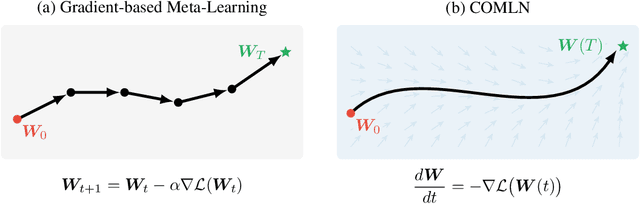
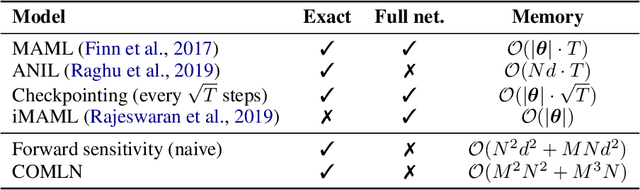
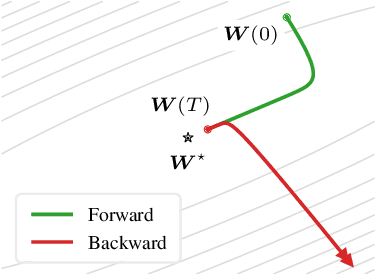
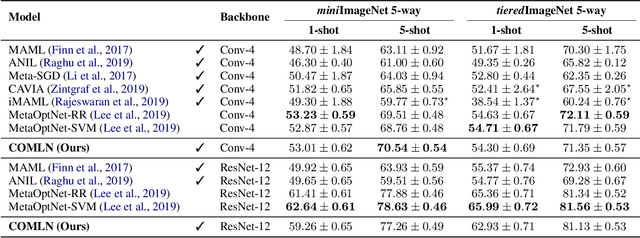
Drawing inspiration from gradient-based meta-learning methods with infinitely small gradient steps, we introduce Continuous-Time Meta-Learning (COMLN), a meta-learning algorithm where adaptation follows the dynamics of a gradient vector field. Specifically, representations of the inputs are meta-learned such that a task-specific linear classifier is obtained as a solution of an ordinary differential equation (ODE). Treating the learning process as an ODE offers the notable advantage that the length of the trajectory is now continuous, as opposed to a fixed and discrete number of gradient steps. As a consequence, we can optimize the amount of adaptation necessary to solve a new task using stochastic gradient descent, in addition to learning the initial conditions as is standard practice in gradient-based meta-learning. Importantly, in order to compute the exact meta-gradients required for the outer-loop updates, we devise an efficient algorithm based on forward mode differentiation, whose memory requirements do not scale with the length of the learning trajectory, thus allowing longer adaptation in constant memory. We provide analytical guarantees for the stability of COMLN, we show empirically its efficiency in terms of runtime and memory usage, and we illustrate its effectiveness on a range of few-shot image classification problems.
Myriad: a real-world testbed to bridge trajectory optimization and deep learning
Feb 22, 2022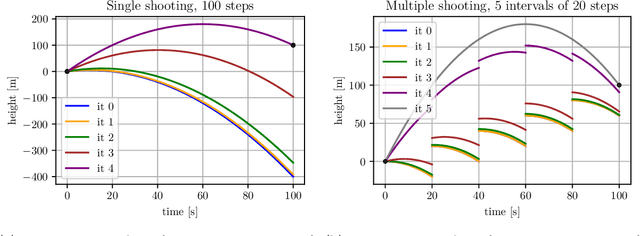
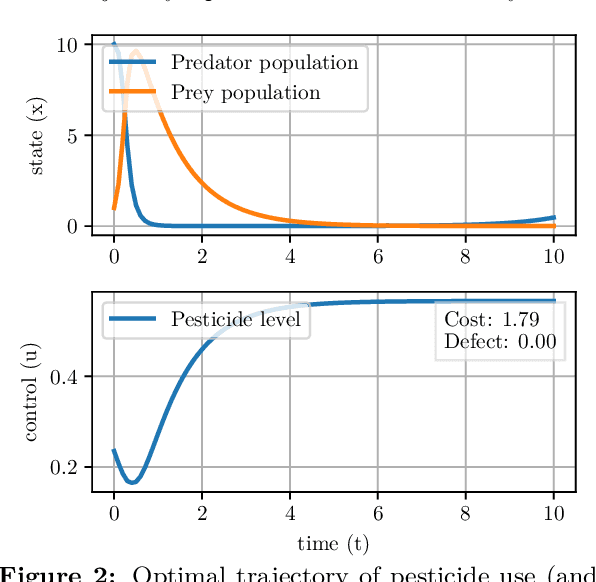

We present Myriad, a testbed written in JAX for learning and planning in real-world continuous environments. The primary contributions of Myriad are threefold. First, Myriad provides machine learning practitioners access to trajectory optimization techniques for application within a typical automatic differentiation workflow. Second, Myriad presents many real-world optimal control problems, ranging from biology to medicine to engineering, for use by the machine learning community. Formulated in continuous space and time, these environments retain some of the complexity of real-world systems often abstracted away by standard benchmarks. As such, Myriad strives to serve as a stepping stone towards application of modern machine learning techniques for impactful real-world tasks. Finally, we use the Myriad repository to showcase a novel approach for learning and control tasks. Trained in a fully end-to-end fashion, our model leverages an implicit planning module over neural ordinary differential equations, enabling simultaneous learning and planning with complex environment dynamics.
Direct Behavior Specification via Constrained Reinforcement Learning
Jan 19, 2022
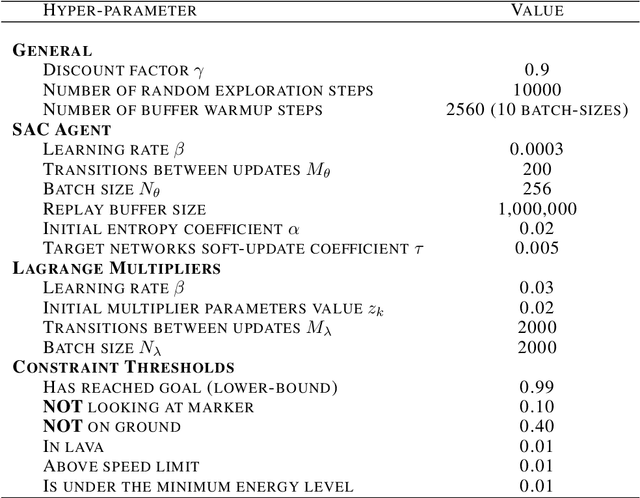
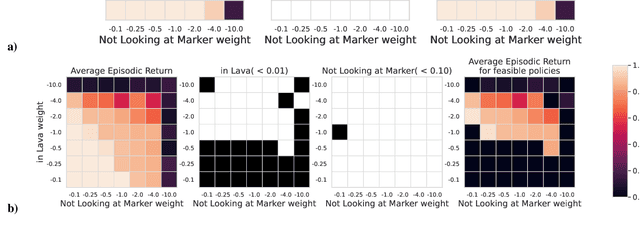

The standard formulation of Reinforcement Learning lacks a practical way of specifying what are admissible and forbidden behaviors. Most often, practitioners go about the task of behavior specification by manually engineering the reward function, a counter-intuitive process that requires several iterations and is prone to reward hacking by the agent. In this work, we argue that constrained RL, which has almost exclusively been used for safe RL, also has the potential to significantly reduce the amount of work spent for reward specification in applied RL projects. To this end, we propose to specify behavioral preferences in the CMDP framework and to use Lagrangian methods to automatically weigh each of these behavioral constraints. Specifically, we investigate how CMDPs can be adapted to solve goal-based tasks while adhering to several constraints simultaneously. We evaluate this framework on a set of continuous control tasks relevant to the application of Reinforcement Learning for NPC design in video games.
Neural Algorithmic Reasoners are Implicit Planners
Oct 11, 2021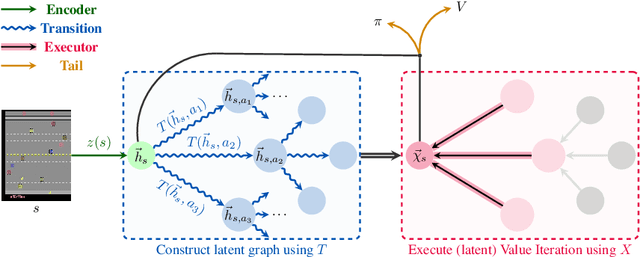
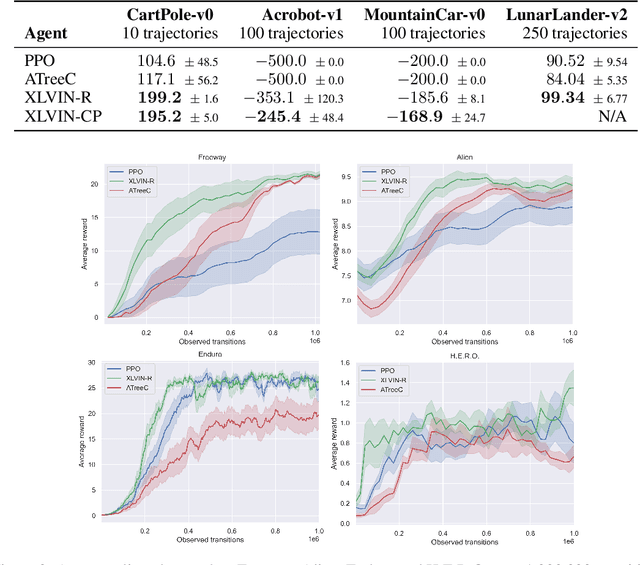

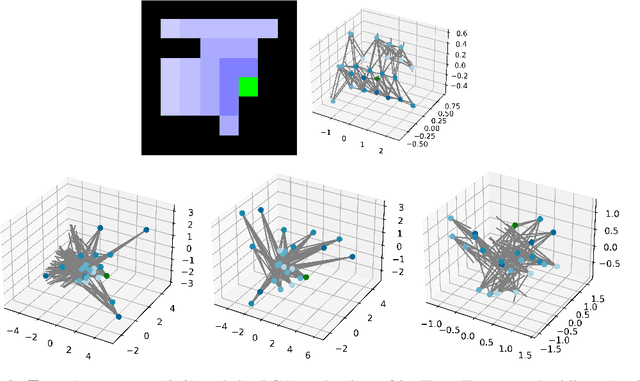
Implicit planning has emerged as an elegant technique for combining learned models of the world with end-to-end model-free reinforcement learning. We study the class of implicit planners inspired by value iteration, an algorithm that is guaranteed to yield perfect policies in fully-specified tabular environments. We find that prior approaches either assume that the environment is provided in such a tabular form -- which is highly restrictive -- or infer "local neighbourhoods" of states to run value iteration over -- for which we discover an algorithmic bottleneck effect. This effect is caused by explicitly running the planning algorithm based on scalar predictions in every state, which can be harmful to data efficiency if such scalars are improperly predicted. We propose eXecuted Latent Value Iteration Networks (XLVINs), which alleviate the above limitations. Our method performs all planning computations in a high-dimensional latent space, breaking the algorithmic bottleneck. It maintains alignment with value iteration by carefully leveraging neural graph-algorithmic reasoning and contrastive self-supervised learning. Across eight low-data settings -- including classical control, navigation and Atari -- XLVINs provide significant improvements to data efficiency against value iteration-based implicit planners, as well as relevant model-free baselines. Lastly, we empirically verify that XLVINs can closely align with value iteration.
Control-Oriented Model-Based Reinforcement Learning with Implicit Differentiation
Jun 06, 2021
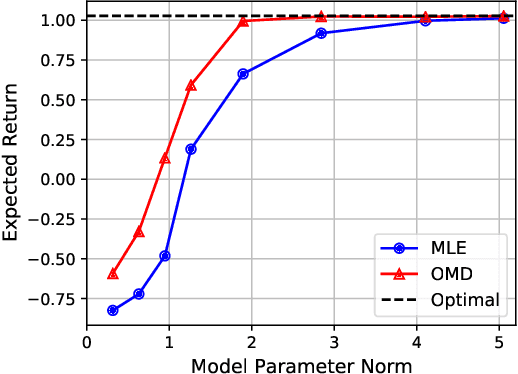
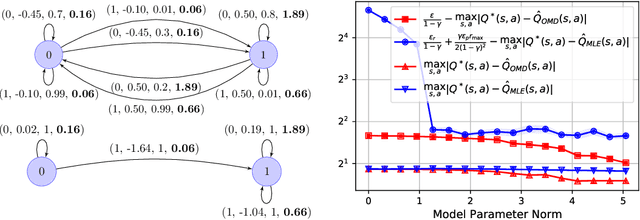
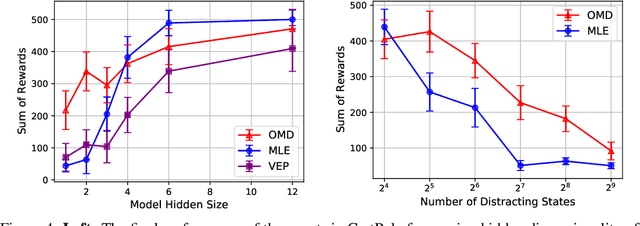
The shortcomings of maximum likelihood estimation in the context of model-based reinforcement learning have been highlighted by an increasing number of papers. When the model class is misspecified or has a limited representational capacity, model parameters with high likelihood might not necessarily result in high performance of the agent on a downstream control task. To alleviate this problem, we propose an end-to-end approach for model learning which directly optimizes the expected returns using implicit differentiation. We treat a value function that satisfies the Bellman optimality operator induced by the model as an implicit function of model parameters and show how to differentiate the function. We provide theoretical and empirical evidence highlighting the benefits of our approach in the model misspecification regime compared to likelihood-based methods.
An Information-Theoretic Perspective on Credit Assignment in Reinforcement Learning
Mar 10, 2021How do we formalize the challenge of credit assignment in reinforcement learning? Common intuition would draw attention to reward sparsity as a key contributor to difficult credit assignment and traditional heuristics would look to temporal recency for the solution, calling upon the classic eligibility trace. We posit that it is not the sparsity of the reward itself that causes difficulty in credit assignment, but rather the \emph{information sparsity}. We propose to use information theory to define this notion, which we then use to characterize when credit assignment is an obstacle to efficient learning. With this perspective, we outline several information-theoretic mechanisms for measuring credit under a fixed behavior policy, highlighting the potential of information theory as a key tool towards provably-efficient credit assignment.
XLVIN: eXecuted Latent Value Iteration Nets
Oct 25, 2020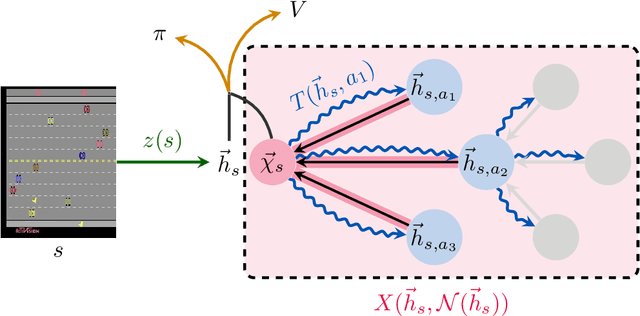

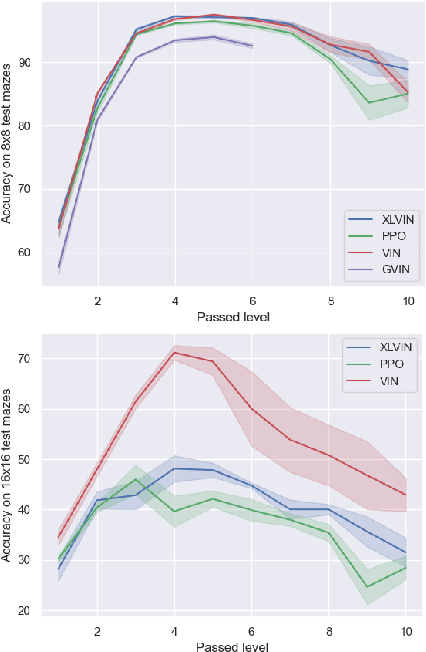
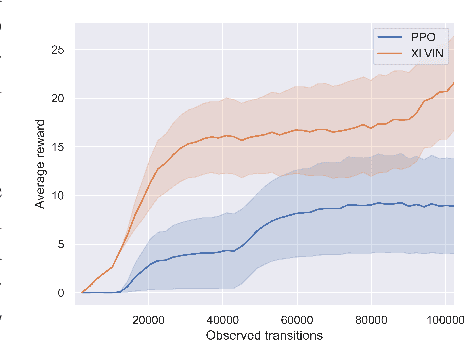
Value Iteration Networks (VINs) have emerged as a popular method to incorporate planning algorithms within deep reinforcement learning, enabling performance improvements on tasks requiring long-range reasoning and understanding of environment dynamics. This came with several limitations, however: the model is not incentivised in any way to perform meaningful planning computations, the underlying state space is assumed to be discrete, and the Markov decision process (MDP) is assumed fixed and known. We propose eXecuted Latent Value Iteration Networks (XLVINs), which combine recent developments across contrastive self-supervised learning, graph representation learning and neural algorithmic reasoning to alleviate all of the above limitations, successfully deploying VIN-style models on generic environments. XLVINs match the performance of VIN-like models when the underlying MDP is discrete, fixed and known, and provides significant improvements to model-free baselines across three general MDP setups.
Graph neural induction of value iteration
Sep 26, 2020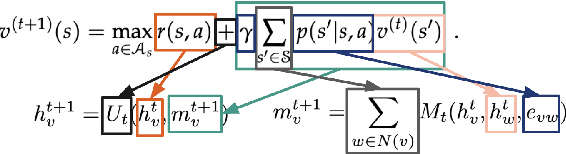
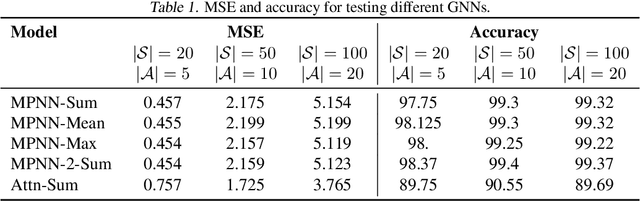
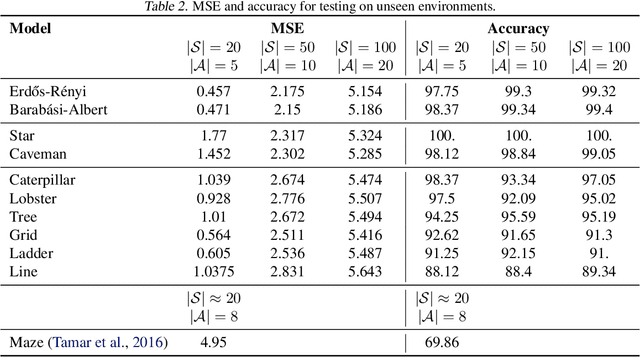
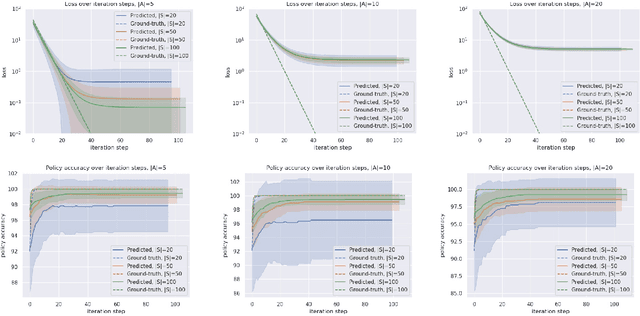
Many reinforcement learning tasks can benefit from explicit planning based on an internal model of the environment. Previously, such planning components have been incorporated through a neural network that partially aligns with the computational graph of value iteration. Such network have so far been focused on restrictive environments (e.g. grid-worlds), and modelled the planning procedure only indirectly. We relax these constraints, proposing a graph neural network (GNN) that executes the value iteration (VI) algorithm, across arbitrary environment models, with direct supervision on the intermediate steps of VI. The results indicate that GNNs are able to model value iteration accurately, recovering favourable metrics and policies across a variety of out-of-distribution tests. This suggests that GNN executors with strong supervision are a viable component within deep reinforcement learning systems.