 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerwise LQR for Geometry-Aware Optimization of Deep Networks
May 05, 2026Geometry-aware optimizers such as Newton and natural gradient can improve conditioning in deep learning, but scalable variants such as K-FAC, Shampoo, and related preconditioners usually impose structural approximations early, often discarding cross-layer interactions induced by the network computation. We introduce Layerwise LQR (LLQR), a framework for learning structured inverse preconditioners under a global layerwise optimal-control objective. The starting point is an exact equivalence: the steepest-descent step under a broad class of divergence-induced quadratic models--including Newton, Gauss-Newton, Fisher/natural-gradient, and intermediate-layer metrics--can be written as a finite-horizon Linear Quadratic Regulator (LQR) problem. This formulation serves as a reference that exposes the layerwise dynamics and cost matrices encoding the original dense geometry. We then derive a scalable relaxation that learns diagonal, (E-)Kronecker-factored, or other structured inverse preconditioners by minimizing the LQR objective and reusing them across iterations. The resulting optimizer wraps standard methods while retaining a principled connection to second-order geometry, without forming or inverting the global curvature matrix. Experiments on ResNets and Transformers show that LLQR improves optimization dynamics and often translates these gains into improved final test performance, while adding only modest wall-clock overhead. It establishes LLQR as a practical framework for geometry-aware second-order methods and a reference for evaluating scalable approximations.
Maxwell's Demon at Work: Efficient Pruning by Leveraging Saturation of Neurons
Mar 12, 2024



When training deep neural networks, the phenomenon of $\textit{dying neurons}$ $\unicode{x2013}$units that become inactive or saturated, output zero during training$\unicode{x2013}$ has traditionally been viewed as undesirable, linked with optimization challenges, and contributing to plasticity loss in continual learning scenarios. In this paper, we reassess this phenomenon, focusing on sparsity and pruning. By systematically exploring the impact of various hyperparameter configurations on dying neurons, we unveil their potential to facilitate simple yet effective structured pruning algorithms. We introduce $\textit{Demon Pruning}$ (DemP), a method that controls the proliferation of dead neurons, dynamically leading to network sparsity. Achieved through a combination of noise injection on active units and a one-cycled schedule regularization strategy, DemP stands out for its simplicity and broad applicability. Experiments on CIFAR10 and ImageNet datasets demonstrate that DemP surpasses existing structured pruning techniques, showcasing superior accuracy-sparsity tradeoffs and training speedups. These findings suggest a novel perspective on dying neurons as a valuable resource for efficient model compression and optimization.
Myriad: a real-world testbed to bridge trajectory optimization and deep learning
Feb 22, 2022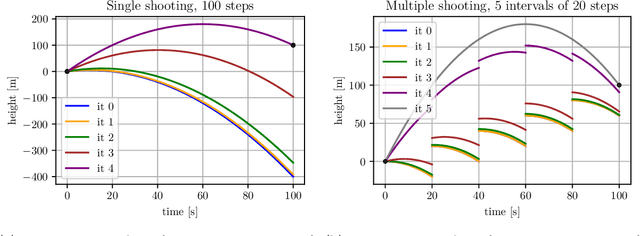
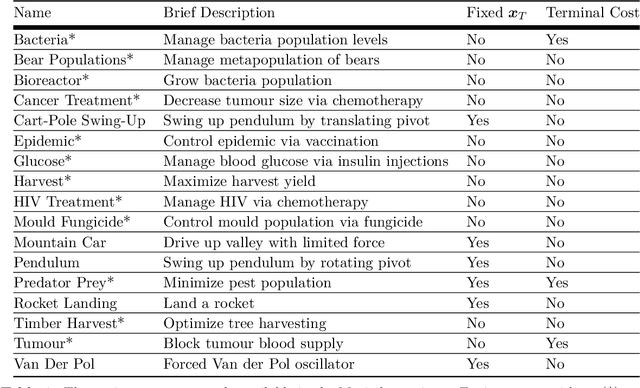
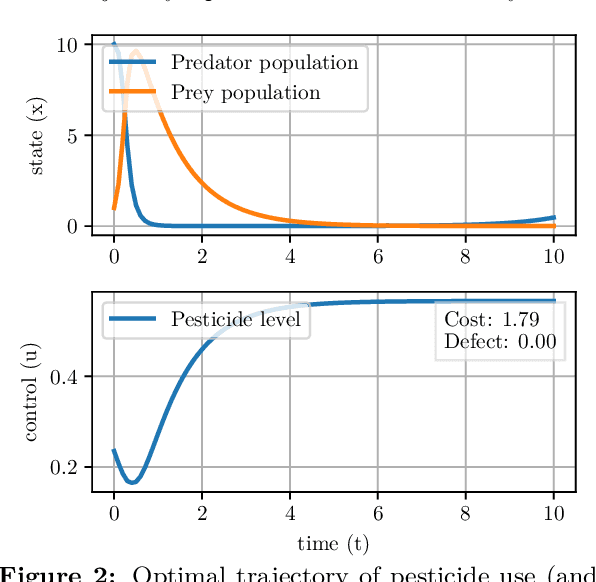

We present Myriad, a testbed written in JAX for learning and planning in real-world continuous environments. The primary contributions of Myriad are threefold. First, Myriad provides machine learning practitioners access to trajectory optimization techniques for application within a typical automatic differentiation workflow. Second, Myriad presents many real-world optimal control problems, ranging from biology to medicine to engineering, for use by the machine learning community. Formulated in continuous space and time, these environments retain some of the complexity of real-world systems often abstracted away by standard benchmarks. As such, Myriad strives to serve as a stepping stone towards application of modern machine learning techniques for impactful real-world tasks. Finally, we use the Myriad repository to showcase a novel approach for learning and control tasks. Trained in a fully end-to-end fashion, our model leverages an implicit planning module over neural ordinary differential equations, enabling simultaneous learning and planning with complex environment dynamics.