 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimSim: An open large-scale dataset for training high-resolution physics emulators in hybrid multi-scale climate simulators
Jun 16, 2023Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise prediction of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.
Generalizing to new calorimeter geometries with Geometry-Aware Autoregressive Models (GAAMs) for fast calorimeter simulation
May 19, 2023Generation of simulated detector response to collision products is crucial to data analysis in particle physics, but computationally very expensive. One subdetector, the calorimeter, dominates the computational time due to the high granularity of its cells and complexity of the interaction. Generative models can provide more rapid sample production, but currently require significant effort to optimize performance for specific detector geometries, often requiring many networks to describe the varying cell sizes and arrangements, which do not generalize to other geometries. We develop a {\it geometry-aware} autoregressive model, which learns how the calorimeter response varies with geometry, and is capable of generating simulated responses to unseen geometries without additional training. The geometry-aware model outperforms a baseline, unaware model by 50\% in metrics such as the Wasserstein distance between generated and true distributions of key quantities which summarize the simulated response. A single geometry-aware model could replace the hundreds of generative models currently designed for calorimeter simulation by physicists analyzing data collected at the Large Hadron Collider. For the study of future detectors, such a foundational model will be a crucial tool, dramatically reducing the large upfront investment usually needed to develop generative calorimeter models.
End-To-End Latent Variational Diffusion Models for Inverse Problems in High Energy Physics
May 17, 2023High-energy collisions at the Large Hadron Collider (LHC) provide valuable insights into open questions in particle physics. However, detector effects must be corrected before measurements can be compared to certain theoretical predictions or measurements from other detectors. Methods to solve this \textit{inverse problem} of mapping detector observations to theoretical quantities of the underlying collision are essential parts of many physics analyses at the LHC. We investigate and compare various generative deep learning methods to approximate this inverse mapping. We introduce a novel unified architecture, termed latent variation diffusion models, which combines the latent learning of cutting-edge generative art approaches with an end-to-end variational framework. We demonstrate the effectiveness of this approach for reconstructing global distributions of theoretical kinematic quantities, as well as for ensuring the adherence of the learned posterior distributions to known physics constraints. Our unified approach achieves a distribution-free distance to the truth of over 20 times less than non-latent state-of-the-art baseline and 3 times less than traditional latent diffusion models.
Language Models can Solve Computer Tasks
Mar 30, 2023



Agents capable of carrying out general tasks on a computer can improve efficiency and productivity by automating repetitive tasks and assisting in complex problem-solving. Ideally, such agents should be able to solve new computer tasks presented to them through natural language commands. However, previous approaches to this problem require large amounts of expert demonstrations and task-specific reward functions, both of which are impractical for new tasks. In this work, we show that a pre-trained large language model (LLM) agent can execute computer tasks guided by natural language using a simple prompting scheme where the agent recursively criticizes and improves its output (RCI). The RCI approach significantly outperforms existing LLM methods for automating computer tasks and surpasses supervised learning (SL) and reinforcement learning (RL) approaches on the MiniWoB++ benchmark. RCI is competitive with the state-of-the-art SL+RL method, using only a handful of demonstrations per task rather than tens of thousands, and without a task-specific reward function. Furthermore, we demonstrate RCI prompting's effectiveness in enhancing LLMs' reasoning abilities on a suite of natural language reasoning tasks, outperforming chain of thought (CoT) prompting. We find that RCI combined with CoT performs better than either separately.
Interpretable Joint Event-Particle Reconstruction for Neutrino Physics at NOvA with Sparse CNNs and Transformers
Mar 10, 2023



The complex events observed at the NOvA long-baseline neutrino oscillation experiment contain vital information for understanding the most elusive particles in the standard model. The NOvA detectors observe interactions of neutrinos from the NuMI beam at Fermilab. Associating the particles produced in these interaction events to their source particles, a process known as reconstruction, is critical for accurately measuring key parameters of the standard model. Events may contain several particles, each producing sparse high-dimensional spatial observations, and current methods are limited to evaluating individual particles. To accurately label these numerous, high-dimensional observations, we present a novel neural network architecture that combines the spatial learning enabled by convolutions with the contextual learning enabled by attention. This joint approach, TransformerCVN, simultaneously classifies each event and reconstructs every individual particle's identity. TransformerCVN classifies events with 90\% accuracy and improves the reconstruction of individual particles by 6\% over baseline methods which lack the integrated architecture of TransformerCVN. In addition, this architecture enables us to perform several interpretability studies which provide insights into the network's predictions and show that TransformerCVN discovers several fundamental principles that stem from the standard model.
Geometry-aware Autoregressive Models for Calorimeter Shower Simulations
Dec 16, 2022Calorimeter shower simulations are often the bottleneck in simulation time for particle physics detectors. A lot of effort is currently spent on optimizing generative architectures for specific detector geometries, which generalize poorly. We develop a geometry-aware autoregressive model on a range of calorimeter geometries such that the model learns to adapt its energy deposition depending on the size and position of the cells. This is a key proof-of-concept step towards building a model that can generalize to new unseen calorimeter geometries with little to no additional training. Such a model can replace the hundreds of generative models used for calorimeter simulation in a Large Hadron Collider experiment. For the study of future detectors, such a model will dramatically reduce the large upfront investment usually needed to generate simulations.
Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments
Jul 19, 2022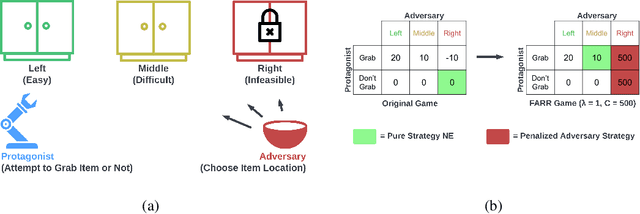

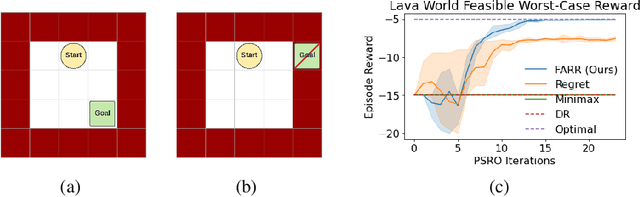

Robust reinforcement learning (RL) considers the problem of learning policies that perform well in the worst case among a set of possible environment parameter values. In real-world environments, choosing the set of possible values for robust RL can be a difficult task. When that set is specified too narrowly, the agent will be left vulnerable to reasonable parameter values unaccounted for. When specified too broadly, the agent will be too cautious. In this paper, we propose Feasible Adversarial Robust RL (FARR), a method for automatically determining the set of environment parameter values over which to be robust. FARR implicitly defines the set of feasible parameter values as those on which an agent could achieve a benchmark reward given enough training resources. By formulating this problem as a two-player zero-sum game, FARR jointly learns an adversarial distribution over parameter values with feasible support and a policy robust over this feasible parameter set. Using the PSRO algorithm to find an approximate Nash equilibrium in this FARR game, we show that an agent trained with FARR is more robust to feasible adversarial parameter selection than with existing minimax, domain-randomization, and regret objectives in a parameterized gridworld and three MuJoCo control environments.
Self-Play PSRO: Toward Optimal Populations in Two-Player Zero-Sum Games
Jul 13, 2022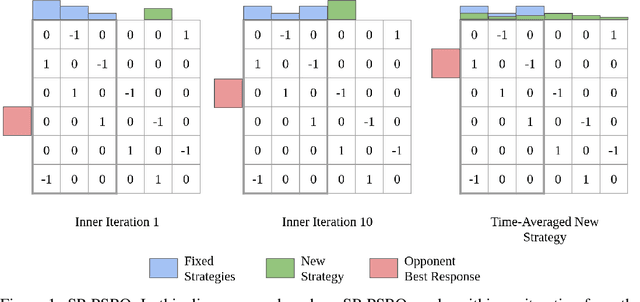
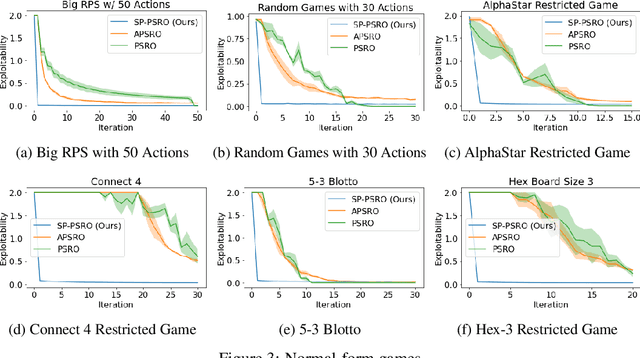

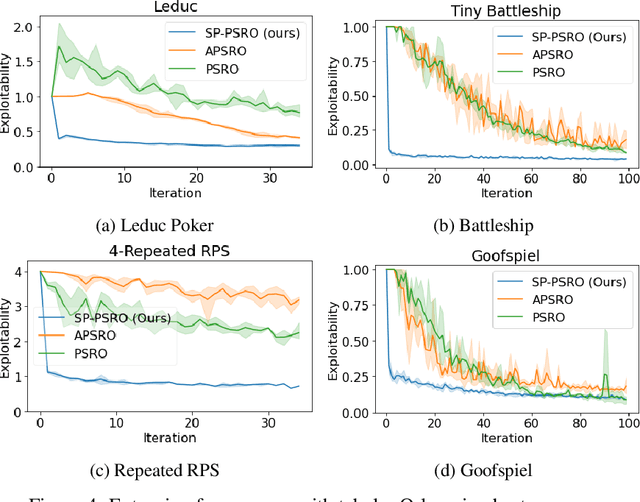
In competitive two-agent environments, deep reinforcement learning (RL) methods based on the \emph{Double Oracle (DO)} algorithm, such as \emph{Policy Space Response Oracles (PSRO)} and \emph{Anytime PSRO (APSRO)}, iteratively add RL best response policies to a population. Eventually, an optimal mixture of these population policies will approximate a Nash equilibrium. However, these methods might need to add all deterministic policies before converging. In this work, we introduce \emph{Self-Play PSRO (SP-PSRO)}, a method that adds an approximately optimal stochastic policy to the population in each iteration. Instead of adding only deterministic best responses to the opponent's least exploitable population mixture, SP-PSRO also learns an approximately optimal stochastic policy and adds it to the population as well. As a result, SP-PSRO empirically tends to converge much faster than APSRO and in many games converges in just a few iterations.
Deep Learning Models of the Discrete Component of the Galactic Interstellar Gamma-Ray Emission
Jun 06, 2022
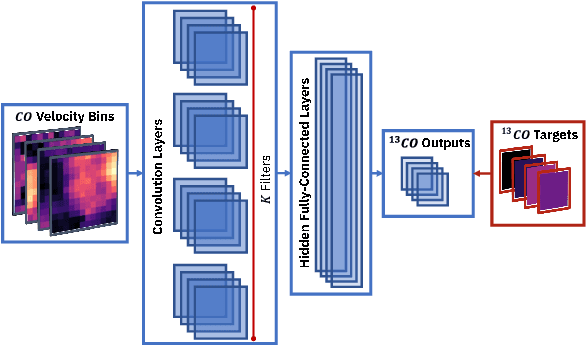

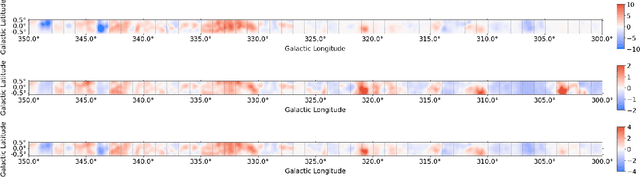
A significant point-like component from the small scale (or discrete) structure in the H2 interstellar gas might be present in the Fermi-LAT data, but modeling this emission relies on observations of rare gas tracers only available in limited regions of the sky. Identifying this contribution is important to discriminate gamma-ray point sources from interstellar gas, and to better characterize extended gamma-ray sources. We design and train convolutional neural networks to predict this emission where observations of these rare tracers do not exist and discuss the impact of this component on the analysis of the Fermi-LAT data. In particular, we evaluate prospects to exploit this methodology in the characterization of the Fermi-LAT Galactic center excess through accurate modeling of point-like structures in the data to help distinguish between a point-like or smooth nature for the excess. We show that deep learning may be effectively employed to model the gamma-ray emission traced by these rare H2 proxies within statistical significance in data-rich regions, supporting prospects to employ these methods in yet unobserved regions.
The Quarks of Attention
Feb 15, 2022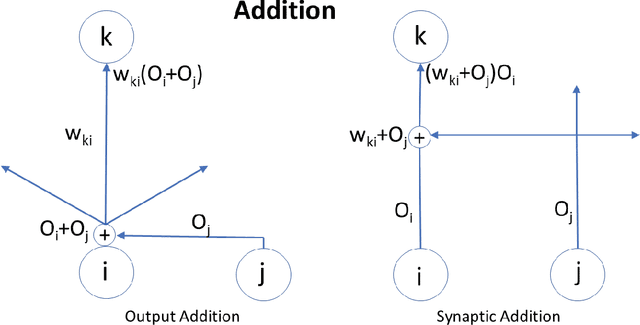

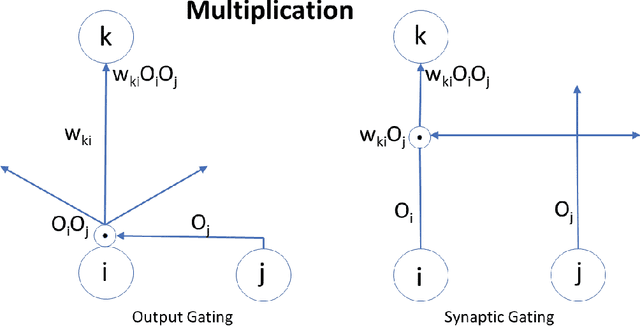
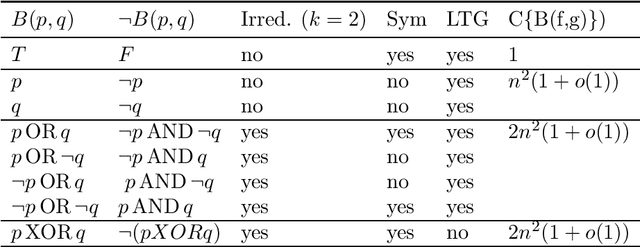
Attention plays a fundamental role in both natural and artificial intelligence systems. In deep learning, attention-based neural architectures, such as transformer architectures, are widely used to tackle problems in natural language processing and beyond. Here we investigate the fundamental building blocks of attention and their computational properties. Within the standard model of deep learning, we classify all possible fundamental building blocks of attention in terms of their source, target, and computational mechanism. We identify and study three most important mechanisms: additive activation attention, multiplicative output attention (output gating), and multiplicative synaptic attention (synaptic gating). The gating mechanisms correspond to multiplicative extensions of the standard model and are used across all current attention-based deep learning architectures. We study their functional properties and estimate the capacity of several attentional building blocks in the case of linear and polynomial threshold gates. Surprisingly, additive activation attention plays a central role in the proofs of the lower bounds. Attention mechanisms reduce the depth of certain basic circuits and leverage the power of quadratic activations without incurring their full cost.