 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfieAvatar: Real-time Head Avatar reenactment from a Selfie Video
Jan 26, 2026Head avatar reenactment focuses on creating animatable personal avatars from monocular videos, serving as a foundational element for applications like social signal understanding, gaming, human-machine interaction, and computer vision. Recent advances in 3D Morphable Model (3DMM)-based facial reconstruction methods have achieved remarkable high-fidelity face estimation. However, on the one hand, they struggle to capture the entire head, including non-facial regions and background details in real time, which is an essential aspect for producing realistic, high-fidelity head avatars. On the other hand, recent approaches leveraging generative adversarial networks (GANs) for head avatar generation from videos can achieve high-quality reenactments but encounter limitations in reproducing fine-grained head details, such as wrinkles and hair textures. In addition, existing methods generally rely on a large amount of training data, and rarely focus on using only a simple selfie video to achieve avatar reenactment. To address these challenges, this study introduces a method for detailed head avatar reenactment using a selfie video. The approach combines 3DMMs with a StyleGAN-based generator. A detailed reconstruction model is proposed, incorporating mixed loss functions for foreground reconstruction and avatar image generation during adversarial training to recover high-frequency details. Qualitative and quantitative evaluations on self-reenactment and cross-reenactment tasks demonstrate that the proposed method achieves superior head avatar reconstruction with rich and intricate textures compared to existing approaches.
Deeper Interpretability of Deep Networks
Nov 20, 2018
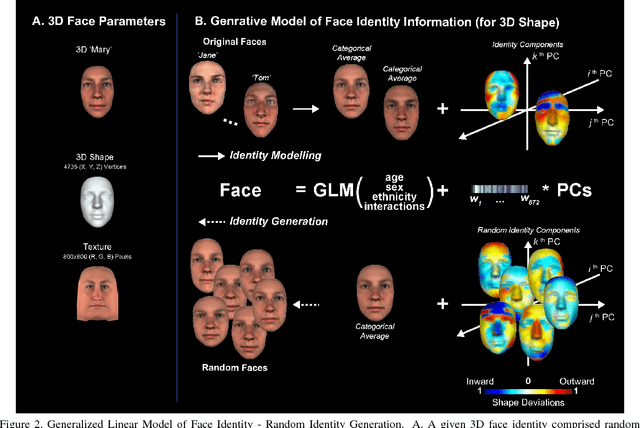
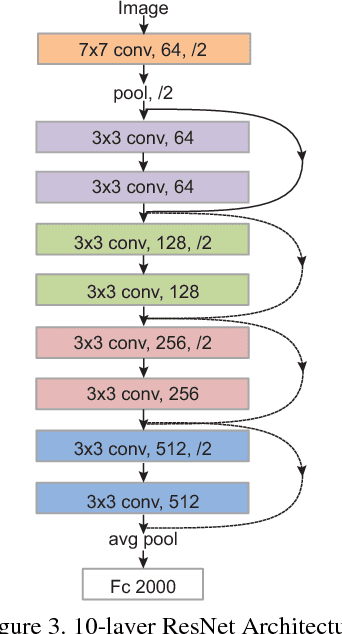
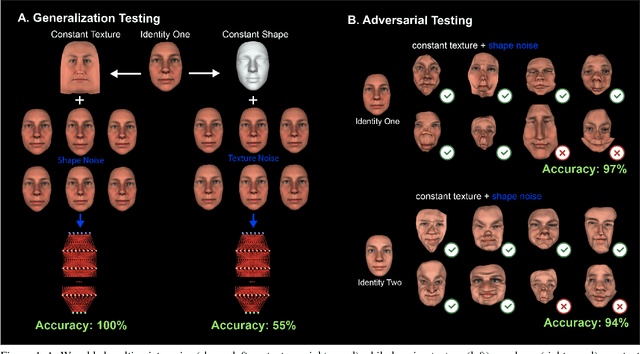
Deep Convolutional Neural Networks (CNNs) have been one of the most influential recent developments in computer vision, particularly for categorization. There is an increasing demand for explainable AI as these systems are deployed in the real world. However, understanding the information represented and processed in CNNs remains in most cases challenging. Within this paper, we explore the use of new information theoretic techniques developed in the field of neuroscience to enable novel understanding of how a CNN represents information. We trained a 10-layer ResNet architecture to identify 2,000 face identities from 26M images generated using a rigorously controlled 3D face rendering model that produced variations of intrinsic (i.e. face morphology, gender, age, expression and ethnicity) and extrinsic factors (i.e. 3D pose, illumination, scale and 2D translation). With our methodology, we demonstrate that unlike human's network overgeneralizes face identities even with extreme changes of face shape, but it is more sensitive to changes of texture. To understand the processing of information underlying these counterintuitive properties, we visualize the features of shape and texture that the network processes to identify faces. Then, we shed a light into the inner workings of the black box and reveal how hidden layers represent these features and whether the representations are invariant to pose. We hope that our methodology will provide an additional valuable tool for interpretability of CNNs.