 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBACH-V: Bridging Abstract and Concrete Human-Values in Large Language Models
Jan 20, 2026Do large language models (LLMs) genuinely understand abstract concepts, or merely manipulate them as statistical patterns? We introduce an abstraction-grounding framework that decomposes conceptual understanding into three capacities: interpretation of abstract concepts (Abstract-Abstract, A-A), grounding of abstractions in concrete events (Abstract-Concrete, A-C), and application of abstract principles to regulate concrete decisions (Concrete-Concrete, C-C). Using human values as a testbed - given their semantic richness and centrality to alignment - we employ probing (detecting value traces in internal activations) and steering (modifying representations to shift behavior). Across six open-source LLMs and ten value dimensions, probing shows that diagnostic probes trained solely on abstract value descriptions reliably detect the same values in concrete event narratives and decision reasoning, demonstrating cross-level transfer. Steering reveals an asymmetry: intervening on value representations causally shifts concrete judgments and decisions (A-C, C-C), yet leaves abstract interpretations unchanged (A-A), suggesting that encoded abstract values function as stable anchors rather than malleable activations. These findings indicate LLMs maintain structured value representations that bridge abstraction and action, providing a mechanistic and operational foundation for building value-driven autonomous AI systems with more transparent, generalizable alignment and control.
Deeper Interpretability of Deep Networks
Nov 20, 2018
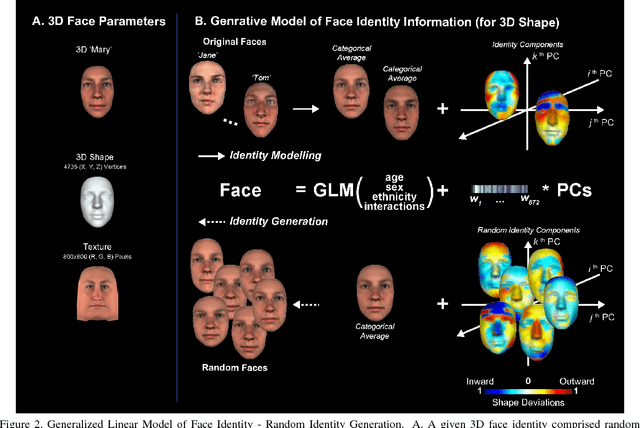
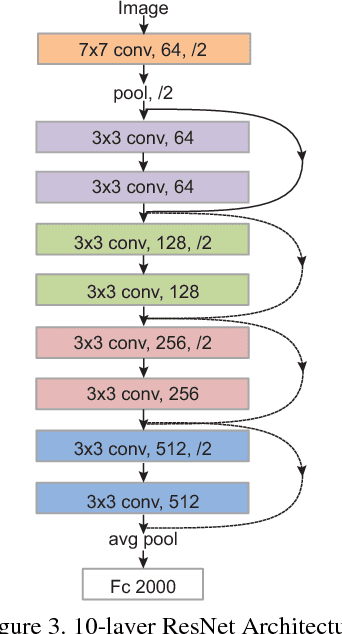
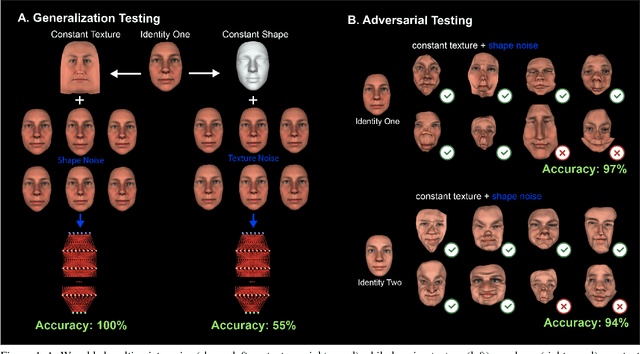
Deep Convolutional Neural Networks (CNNs) have been one of the most influential recent developments in computer vision, particularly for categorization. There is an increasing demand for explainable AI as these systems are deployed in the real world. However, understanding the information represented and processed in CNNs remains in most cases challenging. Within this paper, we explore the use of new information theoretic techniques developed in the field of neuroscience to enable novel understanding of how a CNN represents information. We trained a 10-layer ResNet architecture to identify 2,000 face identities from 26M images generated using a rigorously controlled 3D face rendering model that produced variations of intrinsic (i.e. face morphology, gender, age, expression and ethnicity) and extrinsic factors (i.e. 3D pose, illumination, scale and 2D translation). With our methodology, we demonstrate that unlike human's network overgeneralizes face identities even with extreme changes of face shape, but it is more sensitive to changes of texture. To understand the processing of information underlying these counterintuitive properties, we visualize the features of shape and texture that the network processes to identify faces. Then, we shed a light into the inner workings of the black box and reveal how hidden layers represent these features and whether the representations are invariant to pose. We hope that our methodology will provide an additional valuable tool for interpretability of CNNs.