 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization using Parallel Gradient Evaluations on Multiple Parameters
Feb 06, 2023We propose a first-order method for convex optimization, where instead of being restricted to the gradient from a single parameter, gradients from multiple parameters can be used during each step of gradient descent. This setup is particularly useful when a few processors are available that can be used in parallel for optimization. Our method uses gradients from multiple parameters in synergy to update these parameters together towards the optima. While doing so, it is ensured that the computational and memory complexity is of the same order as that of gradient descent. Empirical results demonstrate that even using gradients from as low as \textit{two} parameters, our method can often obtain significant acceleration and provide robustness to hyper-parameter settings. We remark that the primary goal of this work is less theoretical, and is instead aimed at exploring the understudied case of using multiple gradients during each step of optimization.
Off-Policy Evaluation for Action-Dependent Non-Stationary Environments
Jan 24, 2023Methods for sequential decision-making are often built upon a foundational assumption that the underlying decision process is stationary. This limits the application of such methods because real-world problems are often subject to changes due to external factors (passive non-stationarity), changes induced by interactions with the system itself (active non-stationarity), or both (hybrid non-stationarity). In this work, we take the first steps towards the fundamental challenge of on-policy and off-policy evaluation amidst structured changes due to active, passive, or hybrid non-stationarity. Towards this goal, we make a higher-order stationarity assumption such that non-stationarity results in changes over time, but the way changes happen is fixed. We propose, OPEN, an algorithm that uses a double application of counterfactual reasoning and a novel importance-weighted instrument-variable regression to obtain both a lower bias and a lower variance estimate of the structure in the changes of a policy's past performances. Finally, we show promising results on how OPEN can be used to predict future performances for several domains inspired by real-world applications that exhibit non-stationarity.
Enforcing Delayed-Impact Fairness Guarantees
Aug 24, 2022



Recent research has shown that seemingly fair machine learning models, when used to inform decisions that have an impact on peoples' lives or well-being (e.g., applications involving education, employment, and lending), can inadvertently increase social inequality in the long term. This is because prior fairness-aware algorithms only consider static fairness constraints, such as equal opportunity or demographic parity. However, enforcing constraints of this type may result in models that have negative long-term impact on disadvantaged individuals and communities. We introduce ELF (Enforcing Long-term Fairness), the first classification algorithm that provides high-confidence fairness guarantees in terms of long-term, or delayed, impact. We prove that the probability that ELF returns an unfair solution is less than a user-specified tolerance and that (under mild assumptions), given sufficient training data, ELF is able to find and return a fair solution if one exists. We show experimentally that our algorithm can successfully mitigate long-term unfairness.
Adaptive Rollout Length for Model-Based RL Using Model-Free Deep RL
Jun 07, 2022
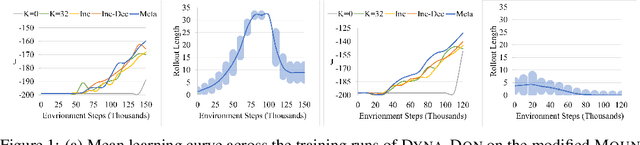
Model-based reinforcement learning promises to learn an optimal policy from fewer interactions with the environment compared to model-free reinforcement learning by learning an intermediate model of the environment in order to predict future interactions. When predicting a sequence of interactions, the rollout length, which limits the prediction horizon, is a critical hyperparameter as accuracy of the predictions diminishes in the regions that are further away from real experience. As a result, with a longer rollout length, an overall worse policy is learned in the long run. Thus, the hyperparameter provides a trade-off between quality and efficiency. In this work, we frame the problem of tuning the rollout length as a meta-level sequential decision-making problem that optimizes the final policy learned by model-based reinforcement learning given a fixed budget of environment interactions by adapting the hyperparameter dynamically based on feedback from the learning process, such as accuracy of the model and the remaining budget of interactions. We use model-free deep reinforcement learning to solve the meta-level decision problem and demonstrate that our approach outperforms common heuristic baselines on two well-known reinforcement learning environments.
Edge-Compatible Reinforcement Learning for Recommendations
Dec 10, 2021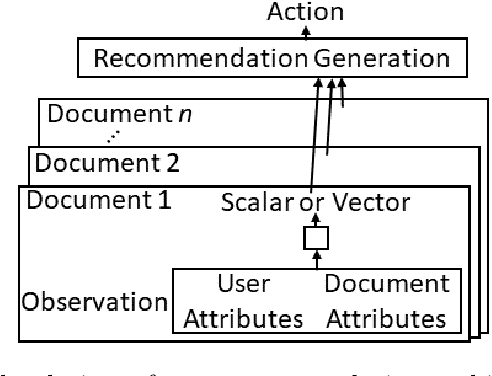
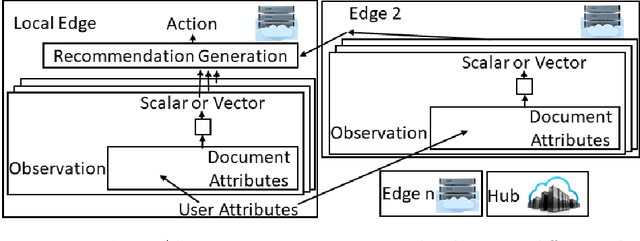
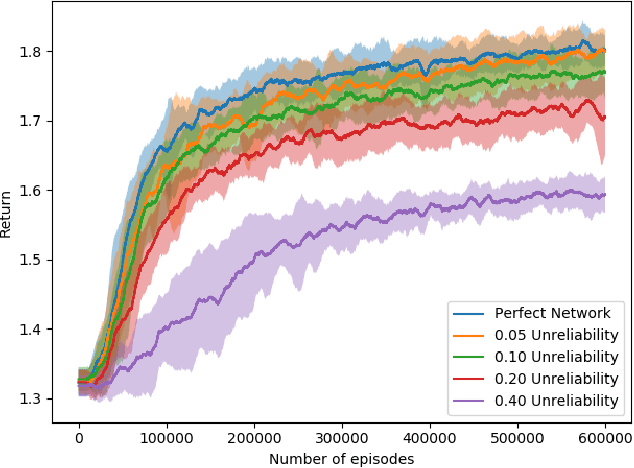
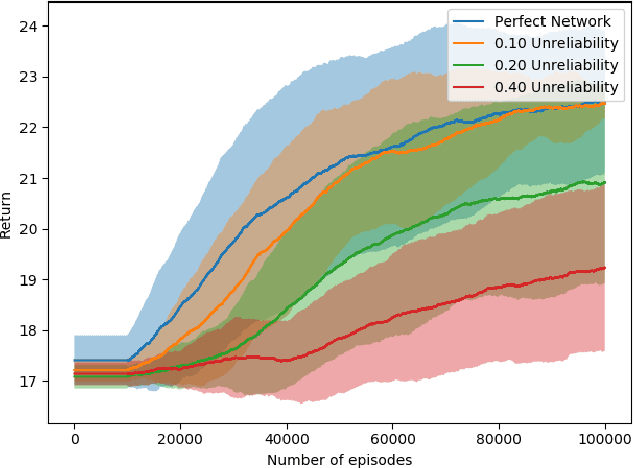
Most reinforcement learning (RL) recommendation systems designed for edge computing must either synchronize during recommendation selection or depend on an unprincipled patchwork collection of algorithms. In this work, we build on asynchronous coagent policy gradient algorithms \citep{kostas2020asynchronous} to propose a principled solution to this problem. The class of algorithms that we propose can be distributed over the internet and run asynchronously and in real-time. When a given edge fails to respond to a request for data with sufficient speed, this is not a problem; the algorithm is designed to function and learn in the edge setting, and network issues are part of this setting. The result is a principled, theoretically grounded RL algorithm designed to be distributed in and learn in this asynchronous environment. In this work, we describe this algorithm and a proposed class of architectures in detail, and demonstrate that they work well in practice in the asynchronous setting, even as the network quality degrades.
SOPE: Spectrum of Off-Policy Estimators
Dec 02, 2021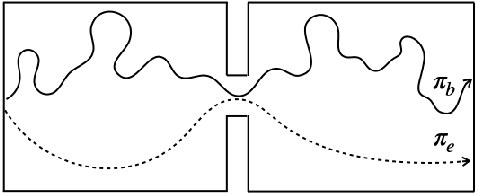

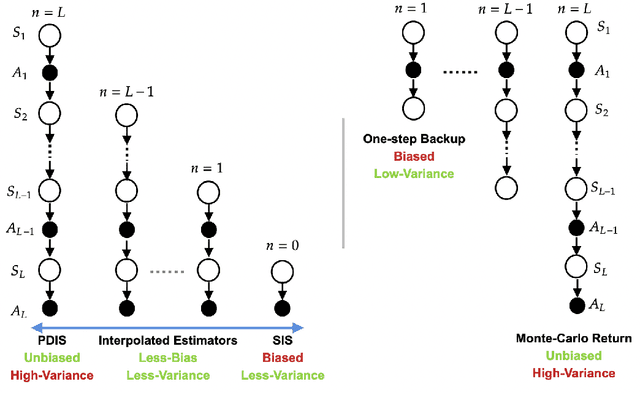
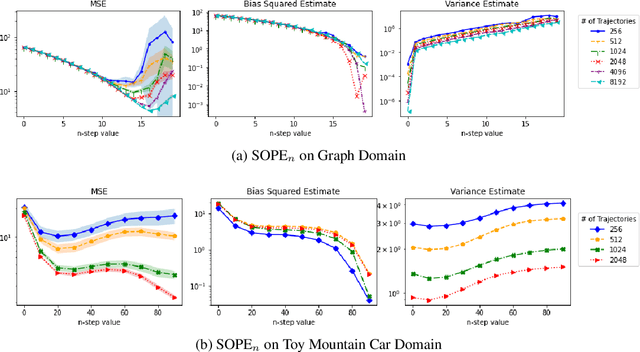
Many sequential decision making problems are high-stakes and require off-policy evaluation (OPE) of a new policy using historical data collected using some other policy. One of the most common OPE techniques that provides unbiased estimates is trajectory based importance sampling (IS). However, due to the high variance of trajectory IS estimates, importance sampling methods based on state-action visitation distributions (SIS) have recently been adopted. Unfortunately, while SIS often provides lower variance estimates for long horizons, estimating the state-action distribution ratios can be challenging and lead to biased estimates. In this paper, we present a new perspective on this bias-variance trade-off and show the existence of a spectrum of estimators whose endpoints are SIS and IS. Additionally, we also establish a spectrum for doubly-robust and weighted version of these estimators. We provide empirical evidence that estimators in this spectrum can be used to trade-off between the bias and variance of IS and SIS and can achieve lower mean-squared error than both IS and SIS.
Multi-Objective SPIBB: Seldonian Offline Policy Improvement with Safety Constraints in Finite MDPs
May 31, 2021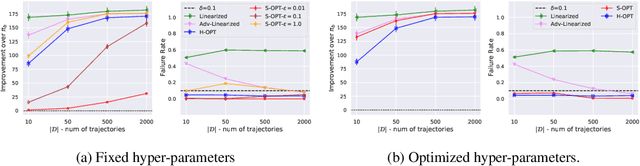
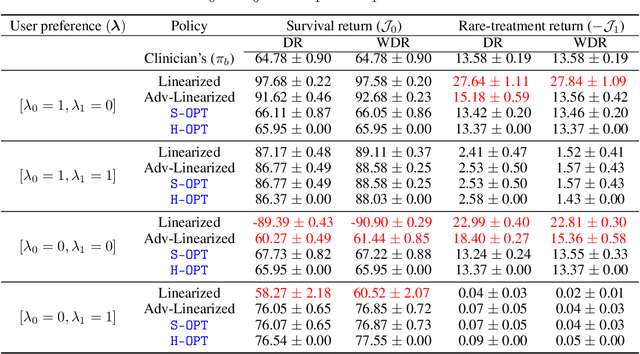
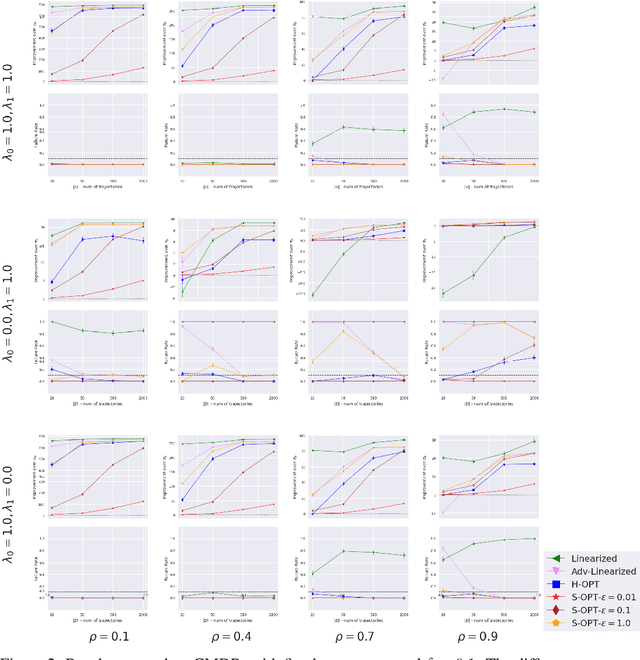

We study the problem of Safe Policy Improvement (SPI) under constraints in the offline Reinforcement Learning (RL) setting. We consider the scenario where: (i) we have a dataset collected under a known baseline policy, (ii) multiple reward signals are received from the environment inducing as many objectives to optimize. We present an SPI formulation for this RL setting that takes into account the preferences of the algorithm's user for handling the trade-offs for different reward signals while ensuring that the new policy performs at least as well as the baseline policy along each individual objective. We build on traditional SPI algorithms and propose a novel method based on Safe Policy Iteration with Baseline Bootstrapping (SPIBB, Laroche et al., 2019) that provides high probability guarantees on the performance of the agent in the true environment. We show the effectiveness of our method on a synthetic grid-world safety task as well as in a real-world critical care context to learn a policy for the administration of IV fluids and vasopressors to treat sepsis.
Universal Off-Policy Evaluation
Apr 26, 2021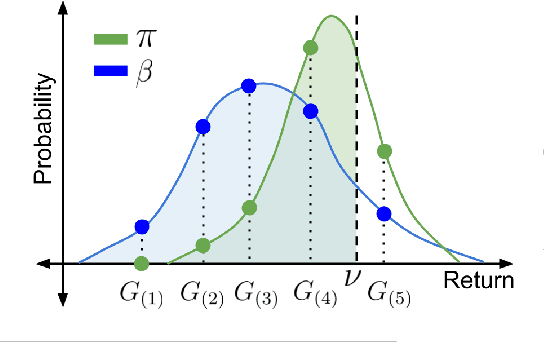

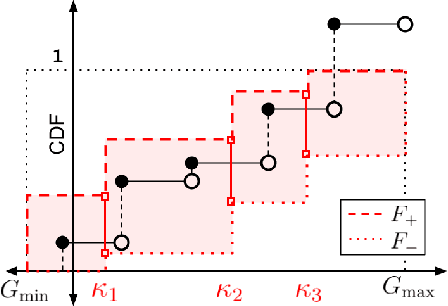
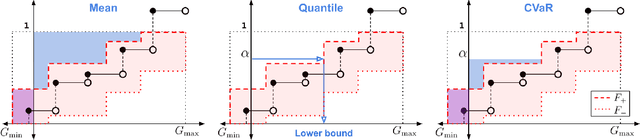
When faced with sequential decision-making problems, it is often useful to be able to predict what would happen if decisions were made using a new policy. Those predictions must often be based on data collected under some previously used decision-making rule. Many previous methods enable such off-policy (or counterfactual) estimation of the expected value of a performance measure called the return. In this paper, we take the first steps towards a universal off-policy estimator (UnO) -- one that provides off-policy estimates and high-confidence bounds for any parameter of the return distribution. We use UnO for estimating and simultaneously bounding the mean, variance, quantiles/median, inter-quantile range, CVaR, and the entire cumulative distribution of returns. Finally, we also discuss Uno's applicability in various settings, including fully observable, partially observable (i.e., with unobserved confounders), Markovian, non-Markovian, stationary, smoothly non-stationary, and discrete distribution shifts.
High-Confidence Off-Policy (or Counterfactual) Variance Estimation
Jan 25, 2021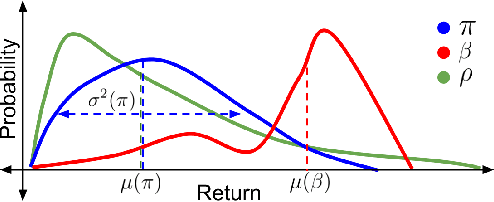
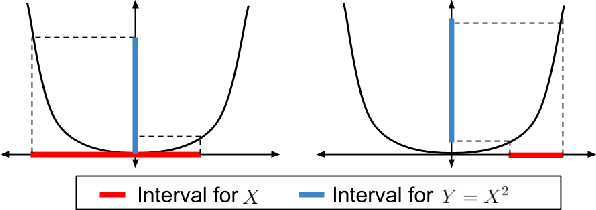
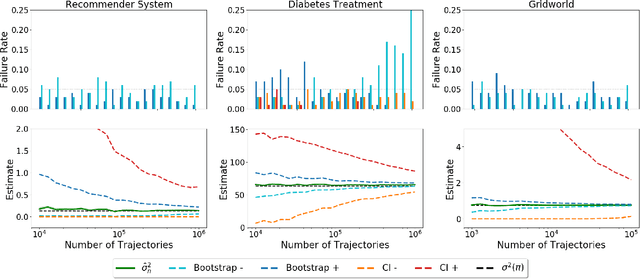
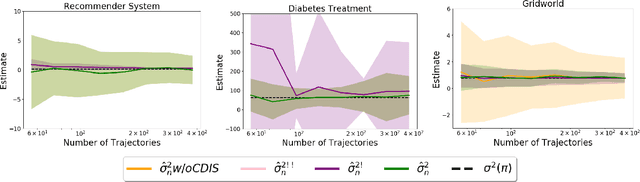
Many sequential decision-making systems leverage data collected using prior policies to propose a new policy. For critical applications, it is important that high-confidence guarantees on the new policy's behavior are provided before deployment, to ensure that the policy will behave as desired. Prior works have studied high-confidence off-policy estimation of the expected return, however, high-confidence off-policy estimation of the variance of returns can be equally critical for high-risk applications. In this paper, we tackle the previously open problem of estimating and bounding, with high confidence, the variance of returns from off-policy data
Towards Safe Policy Improvement for Non-Stationary MDPs
Oct 23, 2020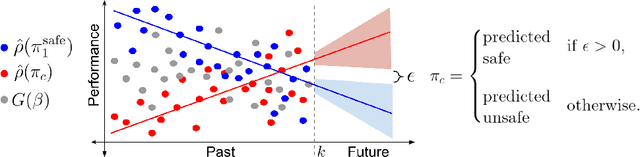
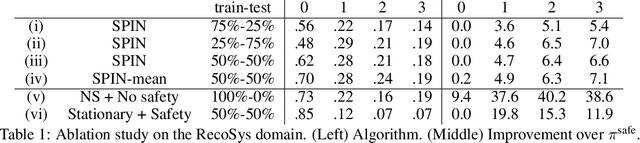
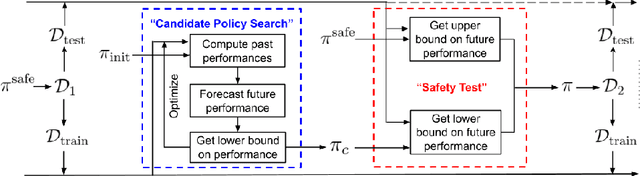

Many real-world sequential decision-making problems involve critical systems with financial risks and human-life risks. While several works in the past have proposed methods that are safe for deployment, they assume that the underlying problem is stationary. However, many real-world problems of interest exhibit non-stationarity, and when stakes are high, the cost associated with a false stationarity assumption may be unacceptable. We take the first steps towards ensuring safety, with high confidence, for smoothly-varying non-stationary decision problems. Our proposed method extends a type of safe algorithm, called a Seldonian algorithm, through a synthesis of model-free reinforcement learning with time-series analysis. Safety is ensured using sequential hypothesis testing of a policy's forecasted performance, and confidence intervals are obtained using wild bootstrap.