 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannian Walk for Incremental Learning: Understanding Forgetting and Intransigence
Aug 14, 2018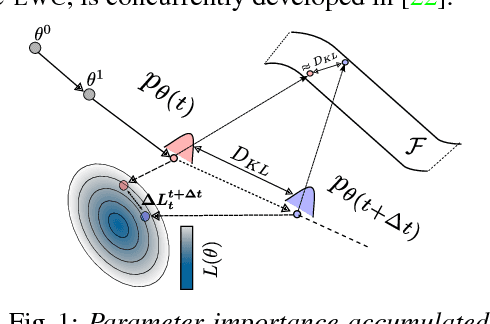
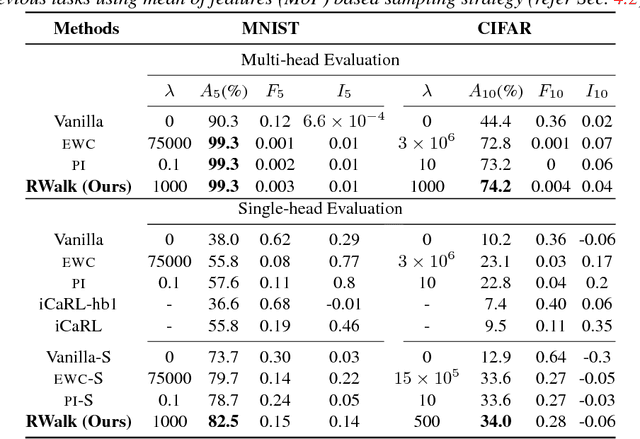
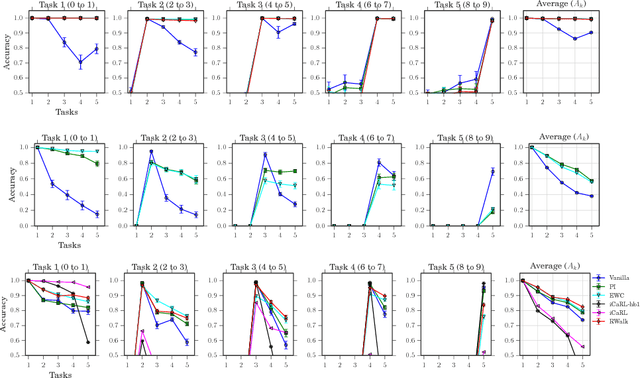
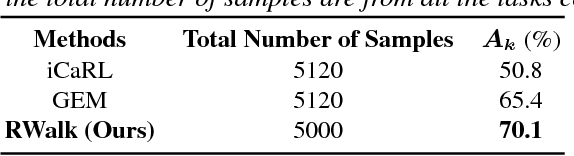
Incremental learning (IL) has received a lot of attention recently, however, the literature lacks a precise problem definition, proper evaluation settings, and metrics tailored specifically for the IL problem. One of the main objectives of this work is to fill these gaps so as to provide a common ground for better understanding of IL. The main challenge for an IL algorithm is to update the classifier whilst preserving existing knowledge. We observe that, in addition to forgetting, a known issue while preserving knowledge, IL also suffers from a problem we call intransigence, inability of a model to update its knowledge. We introduce two metrics to quantify forgetting and intransigence that allow us to understand, analyse, and gain better insights into the behaviour of IL algorithms. We present RWalk, a generalization of EWC++ (our efficient version of EWC [Kirkpatrick2016EWC]) and Path Integral [Zenke2017Continual] with a theoretically grounded KL-divergence based perspective. We provide a thorough analysis of various IL algorithms on MNIST and CIFAR-100 datasets. In these experiments, RWalk obtains superior results in terms of accuracy, and also provides a better trade-off between forgetting and intransigence.
Incremental Tube Construction for Human Action Detection
Jul 23, 2018
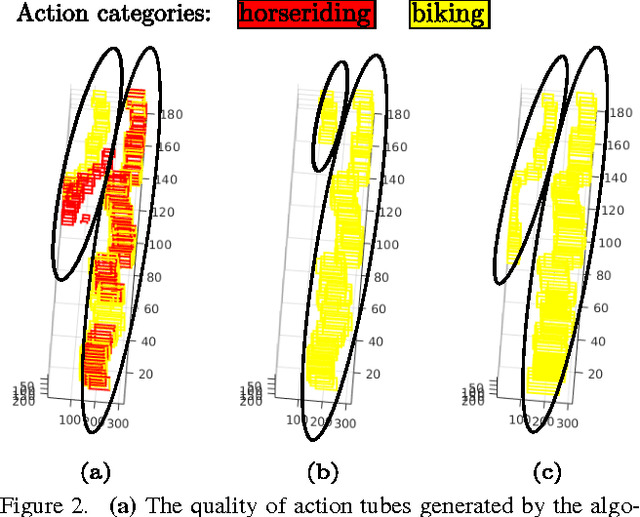
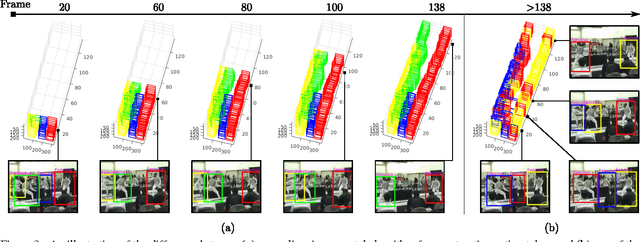

Current state-of-the-art action detection systems are tailored for offline batch-processing applications. However, for online applications like human-robot interaction, current systems fall short, either because they only detect one action per video, or because they assume that the entire video is available ahead of time. In this work, we introduce a real-time and online joint-labelling and association algorithm for action detection that can incrementally construct space-time action tubes on the most challenging action videos in which different action categories occur concurrently. In contrast to previous methods, we solve the detection-window association and action labelling problems jointly in a single pass. We demonstrate superior online association accuracy and speed (2.2ms per frame) as compared to the current state-of-the-art offline systems. We further demonstrate that the entire action detection pipeline can easily be made to work effectively in real-time using our action tube construction algorithm.
With Friends Like These, Who Needs Adversaries?
Jul 23, 2018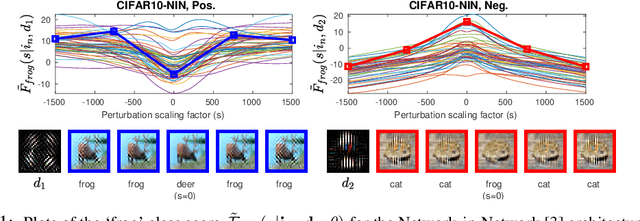

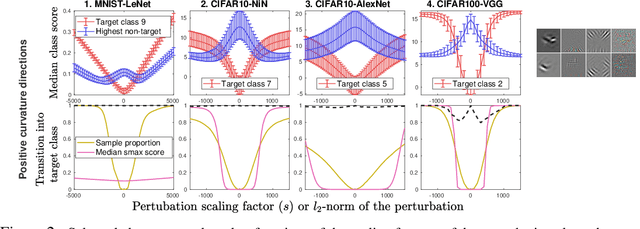
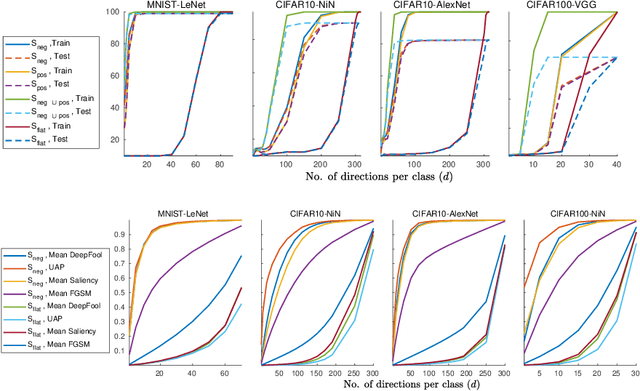
The vulnerability of deep image classification networks to adversarial attack is now well known, but less well understood. Via a novel experimental analysis, we illustrate some facts about deep convolutional networks (DCNs) that shed new light on their behaviour and its connection to the problem of adversaries, with two key results. The first is a straightforward explanation of the existence of universal adversarial perturbations and their association with specific class identities, obtained by analysing the properties of nets' logit responses as functions of 1D movements along specific image-space directions. The second is the clear demonstration of the tight coupling between classification performance and vulnerability to adversarial attack within the spaces spanned by these directions. Prior work has noted the importance of low-dimensional subspaces in adversarial vulnerability: we illustrate that this likewise represents the nets' notion of saliency. In all, we provide a digestible perspective from which to understand previously reported results which have appeared disjoint or contradictory, with implications for efforts to construct neural nets that are both accurate and robust to adversarial attack.
Multi-Agent Diverse Generative Adversarial Networks
Jul 16, 2018
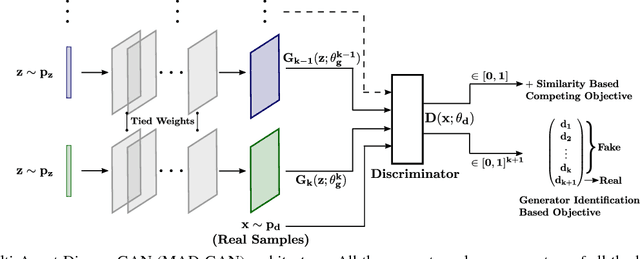

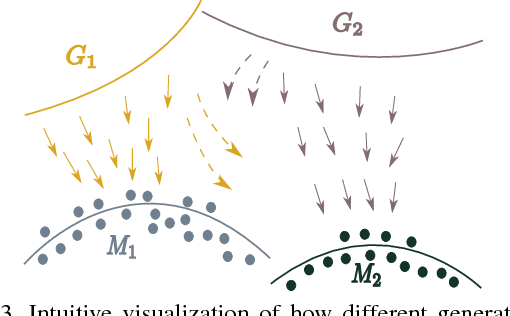
We propose MAD-GAN, an intuitive generalization to the Generative Adversarial Networks (GANs) and its conditional variants to address the well known problem of mode collapse. First, MAD-GAN is a multi-agent GAN architecture incorporating multiple generators and one discriminator. Second, to enforce that different generators capture diverse high probability modes, the discriminator of MAD-GAN is designed such that along with finding the real and fake samples, it is also required to identify the generator that generated the given fake sample. Intuitively, to succeed in this task, the discriminator must learn to push different generators towards different identifiable modes. We perform extensive experiments on synthetic and real datasets and compare MAD-GAN with different variants of GAN. We show high quality diverse sample generations for challenging tasks such as image-to-image translation and face generation. In addition, we also show that MAD-GAN is able to disentangle different modalities when trained using highly challenging diverse-class dataset (e.g. dataset with images of forests, icebergs, and bedrooms). In the end, we show its efficacy on the unsupervised feature representation task. In Appendix, we introduce a similarity based competing objective (MAD-GAN-Sim) which encourages different generators to generate diverse samples based on a user defined similarity metric. We show its performance on the image-to-image translation, and also show its effectiveness on the unsupervised feature representation task.
On the Robustness of Semantic Segmentation Models to Adversarial Attacks
Jul 08, 2018
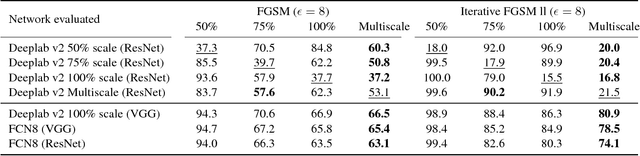
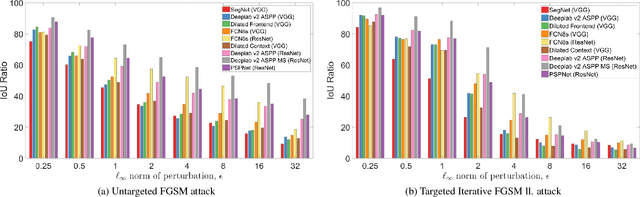

Deep Neural Networks (DNNs) have demonstrated exceptional performance on most recognition tasks such as image classification and segmentation. However, they have also been shown to be vulnerable to adversarial examples. This phenomenon has recently attracted a lot of attention but it has not been extensively studied on multiple, large-scale datasets and structured prediction tasks such as semantic segmentation which often require more specialised networks with additional components such as CRFs, dilated convolutions, skip-connections and multiscale processing. In this paper, we present what to our knowledge is the first rigorous evaluation of adversarial attacks on modern semantic segmentation models, using two large-scale datasets. We analyse the effect of different network architectures, model capacity and multiscale processing, and show that many observations made on the task of classification do not always transfer to this more complex task. Furthermore, we show how mean-field inference in deep structured models, multiscale processing (and more generally, input transformations) naturally implement recently proposed adversarial defenses. Our observations will aid future efforts in understanding and defending against adversarial examples. Moreover, in the shorter term, we show how to effectively benchmark robustness and show which segmentation models should currently be preferred in safety-critical applications due to their inherent robustness.
Intriguing Properties of Learned Representations
Jun 11, 2018

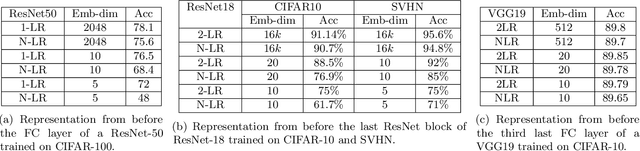
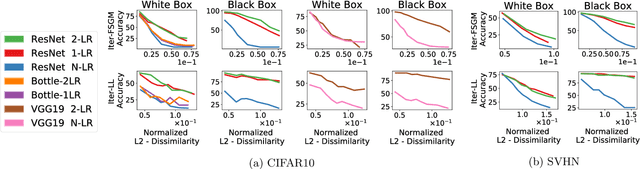
A key feature of neural networks, particularly deep convolutional neural networks, is their ability to "learn" useful representations from data. The very last layer of a neural network is then simply a linear model trained on these "learned" representations. Despite their numerous applications in other tasks such as classification, retrieval, clustering etc., a.k.a. transfer learning, not much work has been published that investigates the structure of these representations or indeed whether structure can be imposed on them during the training process. In this paper, we study the effective dimensionality of the learned representations by models that have proved highly successful for image classification. We focus on ResNet-18, ResNet-50 and VGG-19 and observe that when trained on CIFAR10 or CIFAR100, the learned representations exhibit a fairly low rank structure. We propose a modification to the training procedure, which further encourages low rank structure on learned activations. Empirically, we show that this has implications for robustness to adversarial examples and compression.
Value Propagation Networks
May 28, 2018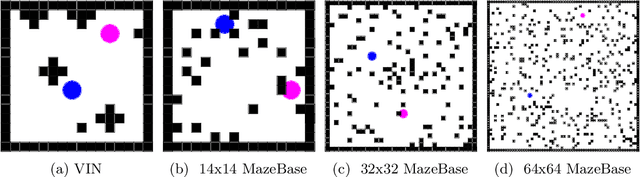

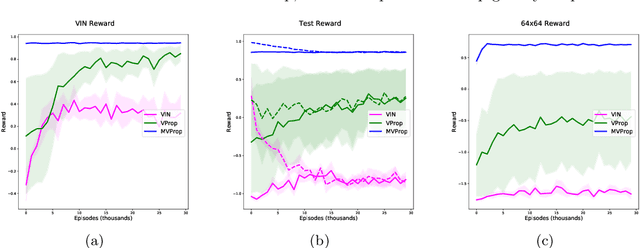
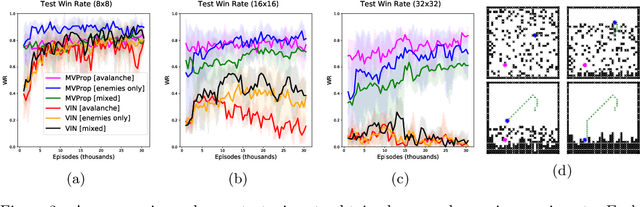
We present Value Propagation (VProp), a parameter-efficient differentiable planning module built on Value Iteration which can successfully be trained using reinforcement learning to solve unseen tasks, has the capability to generalize to larger map sizes, and can learn to navigate in dynamic environments. Furthermore, we show that the module enables learning to plan when the environment also includes stochastic elements, providing a cost-efficient learning system to build low-level size-invariant planners for a variety of interactive navigation problems. We evaluate on static and dynamic configurations of MazeBase grid-worlds, with randomly generated environments of several different sizes, and on a StarCraft navigation scenario, with more complex dynamics, and pixels as input.
A Unified View of Piecewise Linear Neural Network Verification
May 22, 2018
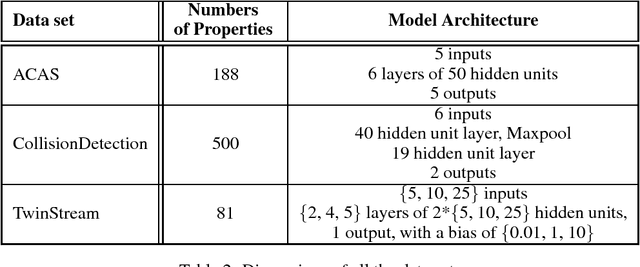
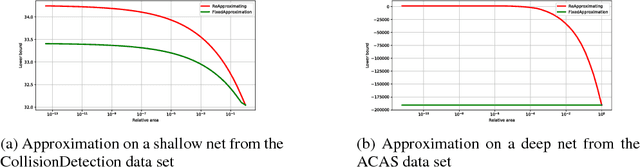
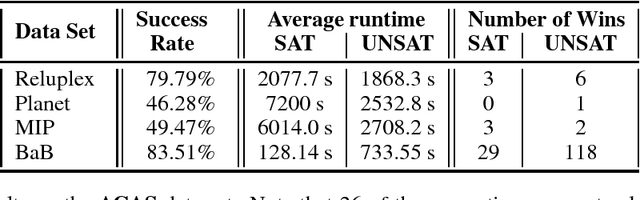
The success of Deep Learning and its potential use in many safety-critical applications has motivated research on formal verification of Neural Network (NN) models. Despite the reputation of learned NN models to behave as black boxes and the theoretical hardness of proving their properties, researchers have been successful in verifying some classes of models by exploiting their piecewise linear structure and taking insights from formal methods such as Satisifiability Modulo Theory. These methods are however still far from scaling to realistic neural networks. To facilitate progress on this crucial area, we make two key contributions. First, we present a unified framework that encompasses previous methods. This analysis results in the identification of new methods that combine the strengths of multiple existing approaches, accomplishing a speedup of two orders of magnitude compared to the previous state of the art. Second, we propose a new data set of benchmarks which includes a collection of previously released testcases. We use the benchmark to provide the first experimental comparison of existing algorithms and identify the factors impacting the hardness of verification problems.
Meta-learning with differentiable closed-form solvers
May 21, 2018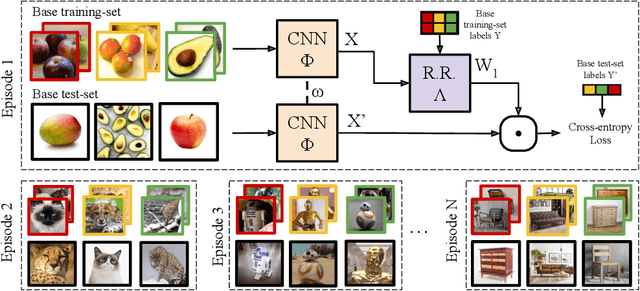
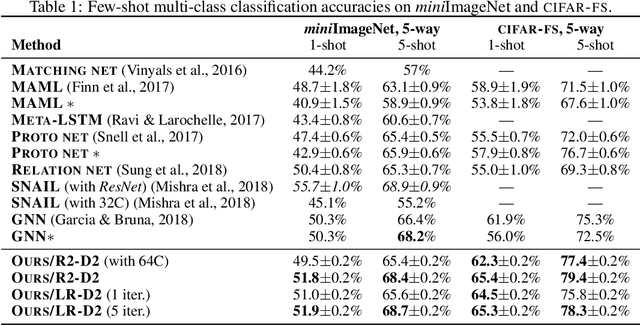
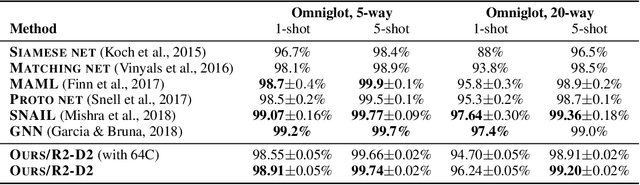
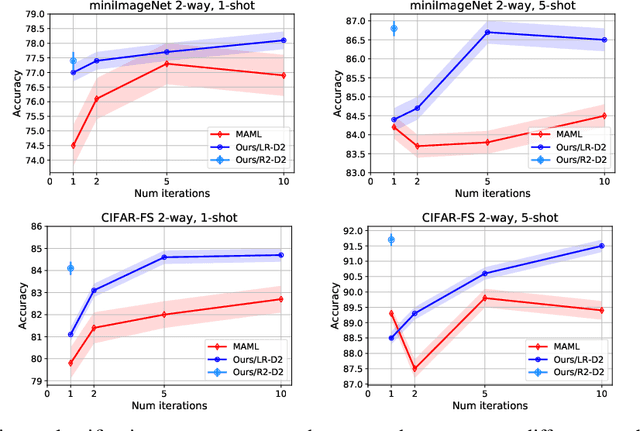
Adapting deep networks to new concepts from few examples is extremely challenging, due to the high computational and data requirements of standard fine-tuning procedures. Most works on meta-learning and few-shot learning have thus focused on simple learning techniques for adaptation, such as nearest neighbors or gradient descent. Nonetheless, the machine learning literature contains a wealth of methods that learn non-deep models very efficiently. In this work we propose to use these fast convergent methods as the main adaptation mechanism for few-shot learning. The main idea is to teach a deep network to use standard machine learning tools, such as logistic regression, as part of its own internal model, enabling it to quickly adapt to novel tasks. This requires back-propagating errors through the solver steps. While normally the matrix operations involved would be costly, the small number of examples works to our advantage, by making use of the Woodbury identity. We propose both iterative and closed-form solvers, based on logistic regression and ridge regression components. Our methods achieve excellent performance on three few-shot learning benchmarks, showing competitive performance on Omniglot and surpassing all state-of-the-art alternatives on miniImageNet and CIFAR-100.
Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning
May 21, 2018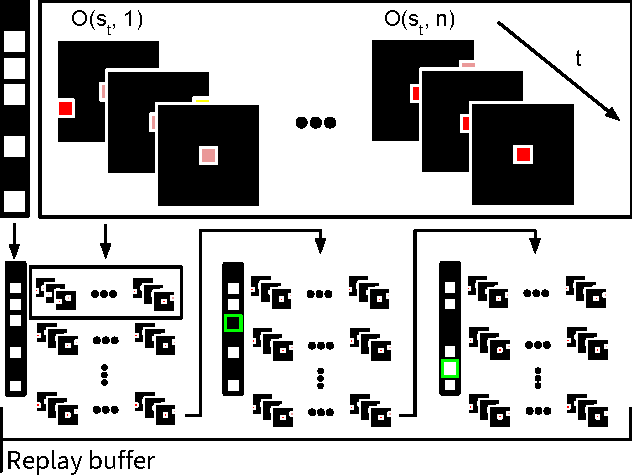

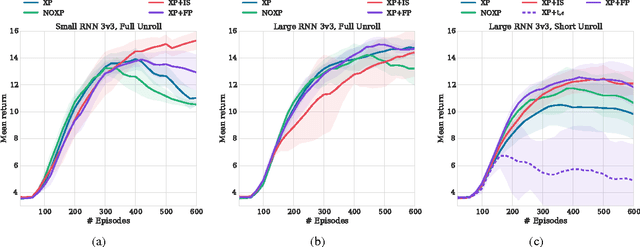
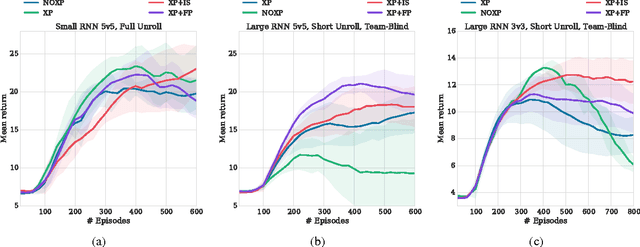
Many real-world problems, such as network packet routing and urban traffic control, are naturally modeled as multi-agent reinforcement learning (RL) problems. However, existing multi-agent RL methods typically scale poorly in the problem size. Therefore, a key challenge is to translate the success of deep learning on single-agent RL to the multi-agent setting. A major stumbling block is that independent Q-learning, the most popular multi-agent RL method, introduces nonstationarity that makes it incompatible with the experience replay memory on which deep Q-learning relies. This paper proposes two methods that address this problem: 1) using a multi-agent variant of importance sampling to naturally decay obsolete data and 2) conditioning each agent's value function on a fingerprint that disambiguates the age of the data sampled from the replay memory. Results on a challenging decentralised variant of StarCraft unit micromanagement confirm that these methods enable the successful combination of experience replay with multi-agent RL.