 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Resize Images for Computer Vision Tasks
Mar 17, 2021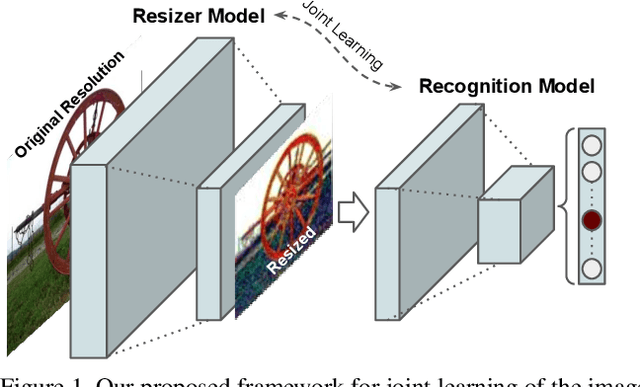


For all the ways convolutional neural nets have revolutionized computer vision in recent years, one important aspect has received surprisingly little attention: the effect of image size on the accuracy of tasks being trained for. Typically, to be efficient, the input images are resized to a relatively small spatial resolution (e.g. 224x224), and both training and inference are carried out at this resolution. The actual mechanism for this re-scaling has been an afterthought: Namely, off-the-shelf image resizers such as bilinear and bicubic are commonly used in most machine learning software frameworks. But do these resizers limit the on task performance of the trained networks? The answer is yes. Indeed, we show that the typical linear resizer can be replaced with learned resizers that can substantially improve performance. Importantly, while the classical resizers typically result in better perceptual quality of the downscaled images, our proposed learned resizers do not necessarily give better visual quality, but instead improve task performance. Our learned image resizer is jointly trained with a baseline vision model. This learned CNN-based resizer creates machine friendly visual manipulations that lead to a consistent improvement of the end task metric over the baseline model. Specifically, here we focus on the classification task with the ImageNet dataset, and experiment with four different models to learn resizers adapted to each model. Moreover, we show that the proposed resizer can also be useful for fine-tuning the classification baselines for other vision tasks. To this end, we experiment with three different baselines to develop image quality assessment (IQA) models on the AVA dataset.
High Perceptual Quality Image Denoising with a Posterior Sampling CGAN
Mar 17, 2021
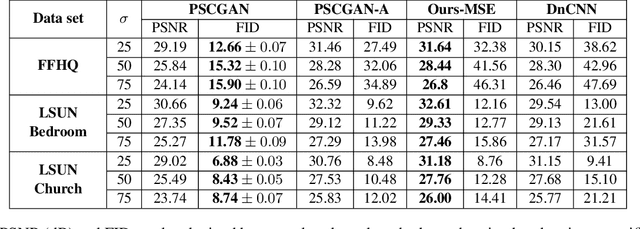

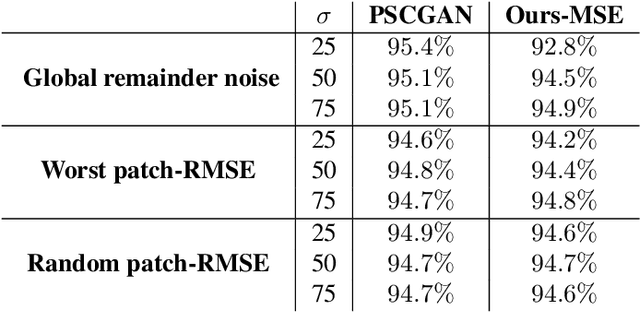
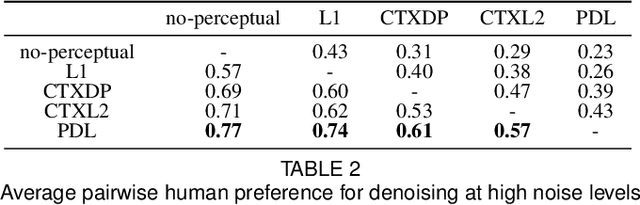
The vast work in Deep Learning (DL) has led to a leap in image denoising research. Most DL solutions for this task have chosen to put their efforts on the denoiser's architecture while maximizing distortion performance. However, distortion driven solutions lead to blurry results with sub-optimal perceptual quality, especially in immoderate noise levels. In this paper we propose a different perspective, aiming to produce sharp and visually pleasing denoised images that are still faithful to their clean sources. Formally, our goal is to achieve high perceptual quality with acceptable distortion. This is attained by a stochastic denoiser that samples from the posterior distribution, trained as a generator in the framework of conditional generative adversarial networks (CGAN). Contrary to distortion-based regularization terms that conflict with perceptual quality, we introduce to the CGAN objective a theoretically founded penalty term that does not force a distortion requirement on individual samples, but rather on their mean. We showcase our proposed method with a novel denoiser architecture that achieves the reformed denoising goal and produces vivid and diverse outcomes in immoderate noise levels.
Mobile Computational Photography: A Tour
Mar 10, 2021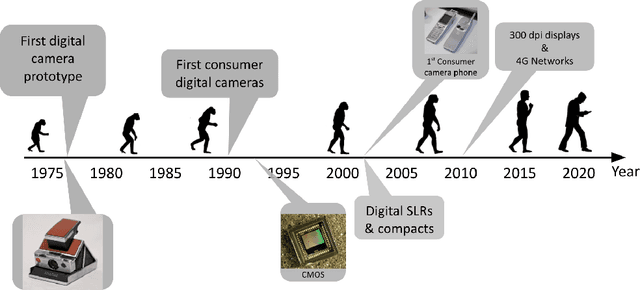

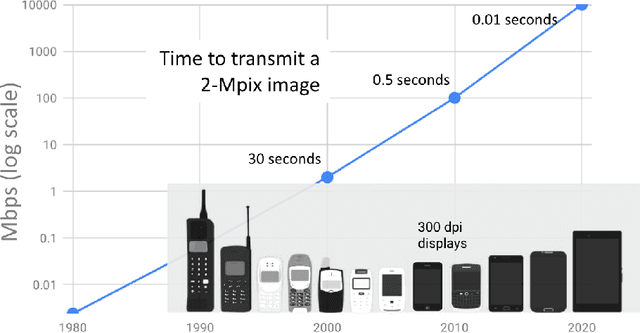

The first mobile camera phone was sold only 20 years ago, when taking pictures with one's phone was an oddity, and sharing pictures online was unheard of. Today, the smartphone is more camera than phone. How did this happen? This transformation was enabled by advances in computational photography -the science and engineering of making great images from small form factor, mobile cameras. Modern algorithmic and computing advances, including machine learning, have changed the rules of photography, bringing to it new modes of capture, post-processing, storage, and sharing. In this paper, we give a brief history of mobile computational photography and describe some of the key technological components, including burst photography, noise reduction, and super-resolution. At each step, we may draw naive parallels to the human visual system.
Deep Perceptual Image Quality Assessment for Compression
Mar 01, 2021

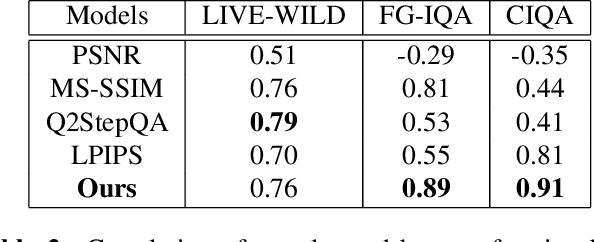
Lossy Image compression is necessary for efficient storage and transfer of data. Typically the trade-off between bit-rate and quality determines the optimal compression level. This makes the image quality metric an integral part of any imaging system. While the existing full-reference metrics such as PSNR and SSIM may be less sensitive to perceptual quality, the recently introduced learning methods may fail to generalize to unseen data. In this paper we propose the largest image compression quality dataset to date with human perceptual preferences, enabling the use of deep learning, and we develop a full reference perceptual quality assessment metric for lossy image compression that outperforms the existing state-of-the-art methods. We show that the proposed model can effectively learn from thousands of examples available in the new dataset, and consequently it generalizes better to other unseen datasets of human perceptual preference.
Polyblur: Removing mild blur by polynomial reblurring
Dec 16, 2020

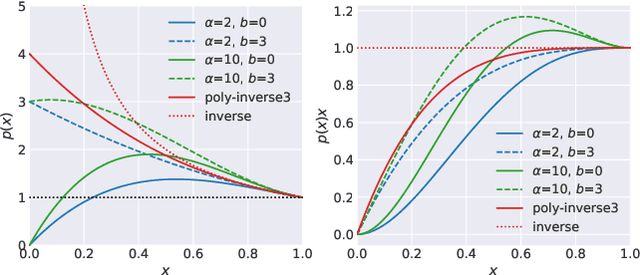
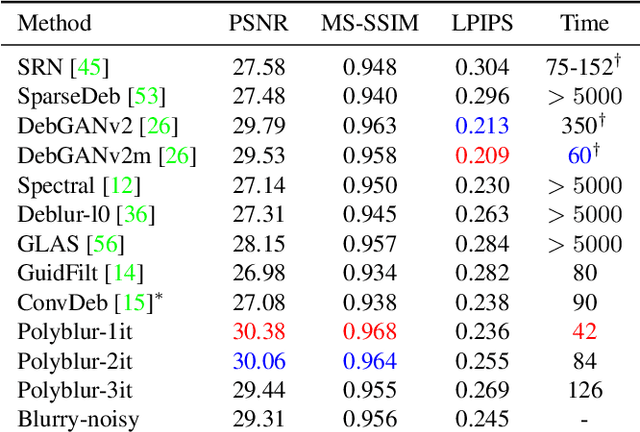
We present a highly efficient blind restoration method to remove mild blur in natural images. Contrary to the mainstream, we focus on removing slight blur that is often present, damaging image quality and commonly generated by small out-of-focus, lens blur, or slight camera motion. The proposed algorithm first estimates image blur and then compensates for it by combining multiple applications of the estimated blur in a principled way. To estimate blur we introduce a simple yet robust algorithm based on empirical observations about the distribution of the gradient in sharp natural images. Our experiments show that, in the context of mild blur, the proposed method outperforms traditional and modern blind deblurring methods and runs in a fraction of the time. Our method can be used to blindly correct blur before applying off-the-shelf deep super-resolution methods leading to superior results than other highly complex and computationally demanding techniques. The proposed method estimates and removes mild blur from a 12MP image on a modern mobile phone in a fraction of a second.
Projected Distribution Loss for Image Enhancement
Dec 16, 2020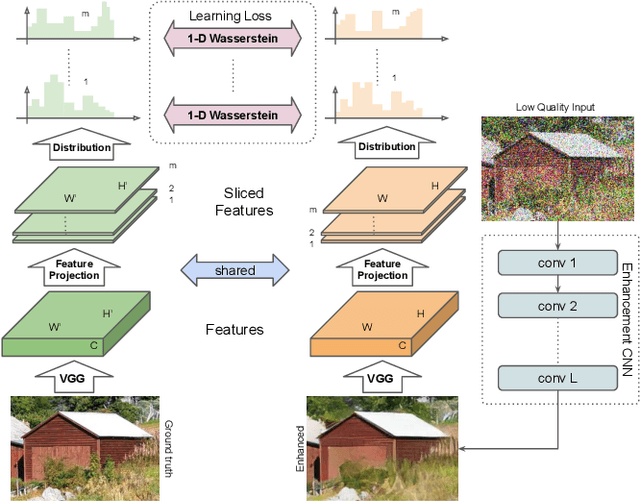
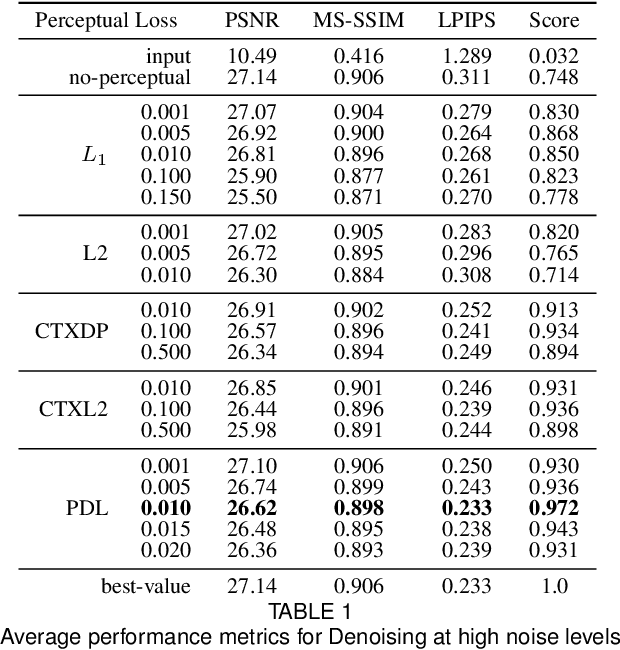
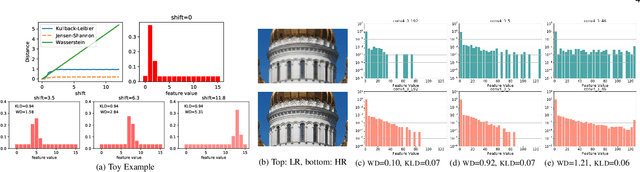
Features obtained from object recognition CNNs have been widely used for measuring perceptual similarities between images. Such differentiable metrics can be used as perceptual learning losses to train image enhancement models. However, the choice of the distance function between input and target features may have a consequential impact on the performance of the trained model. While using the norm of the difference between extracted features leads to limited hallucination of details, measuring the distance between distributions of features may generate more textures; yet also more unrealistic details and artifacts. In this paper, we demonstrate that aggregating 1D-Wasserstein distances between CNN activations is more reliable than the existing approaches, and it can significantly improve the perceptual performance of enhancement models. More explicitly, we show that in imaging applications such as denoising, super-resolution, demosaicing, deblurring and JPEG artifact removal, the proposed learning loss outperforms the current state-of-the-art on reference-based perceptual losses. This means that the proposed learning loss can be plugged into different imaging frameworks and produce perceptually realistic results.
Learning to Reduce Defocus Blur by Realistically Modeling Dual-Pixel Data
Dec 06, 2020
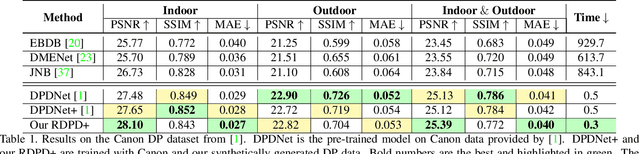
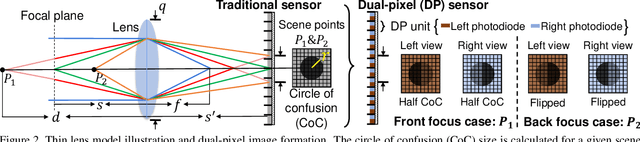
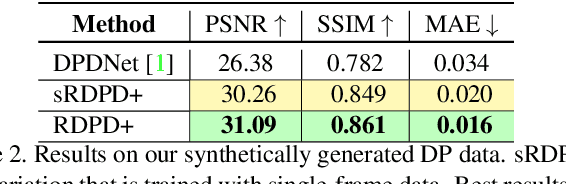
Recent work has shown impressive results on data-driven defocus deblurring using the two-image views available on modern dual-pixel (DP) sensors. One significant challenge in this line of research is access to DP data. Despite many cameras having DP sensors, only a limited number provide access to the low-level DP sensor images. In addition, capturing training data for defocus deblurring involves a time-consuming and tedious setup requiring the camera's aperture to be adjusted. Some cameras with DP sensors (e.g., smartphones) do not have adjustable apertures, further limiting the ability to produce the necessary training data. We address the data capture bottleneck by proposing a procedure to generate realistic DP data synthetically. Our synthesis approach mimics the optical image formation found on DP sensors and can be applied to virtual scenes rendered with standard computer software. Leveraging these realistic synthetic DP images, we introduce a new recurrent convolutional network (RCN) architecture that can improve deblurring results and is suitable for use with single-frame and multi-frame data captured by DP sensors. Finally, we show that our synthetic DP data is useful for training DNN models targeting video deblurring applications where access to DP data remains challenging.
Rank-smoothed Pairwise Learning In Perceptual Quality Assessment
Nov 21, 2020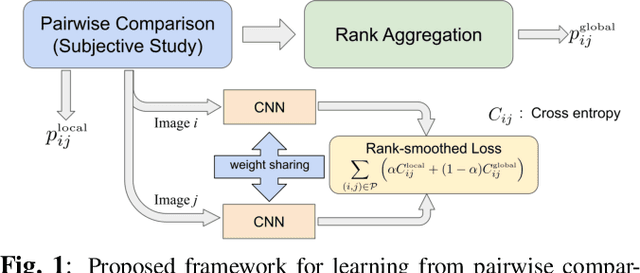
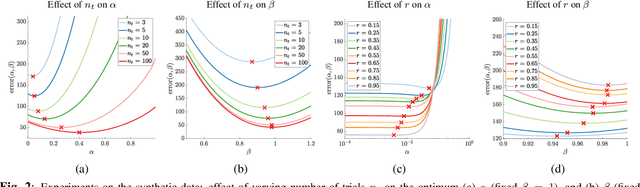
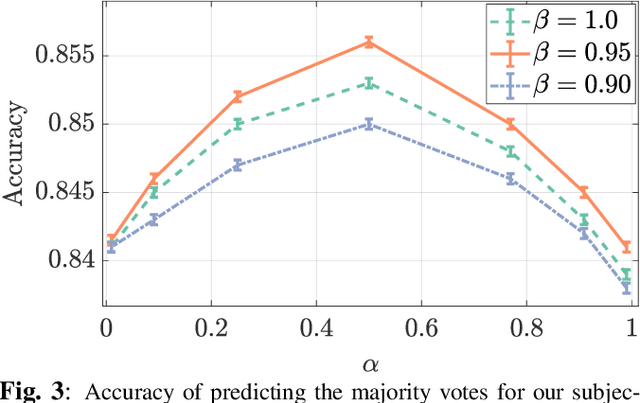

Conducting pairwise comparisons is a widely used approach in curating human perceptual preference data. Typically raters are instructed to make their choices according to a specific set of rules that address certain dimensions of image quality and aesthetics. The outcome of this process is a dataset of sampled image pairs with their associated empirical preference probabilities. Training a model on these pairwise preferences is a common deep learning approach. However, optimizing by gradient descent through mini-batch learning means that the "global" ranking of the images is not explicitly taken into account. In other words, each step of the gradient descent relies only on a limited number of pairwise comparisons. In this work, we demonstrate that regularizing the pairwise empirical probabilities with aggregated rankwise probabilities leads to a more reliable training loss. We show that training a deep image quality assessment model with our rank-smoothed loss consistently improves the accuracy of predicting human preferences.
Multi-path Neural Networks for On-device Multi-domain Visual Classification
Oct 10, 2020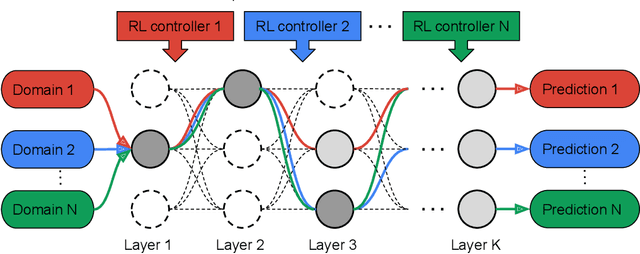
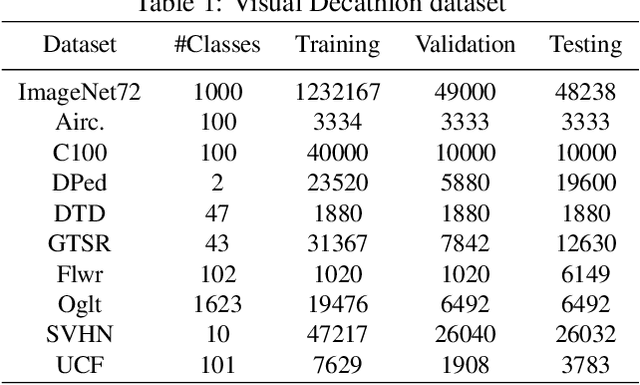
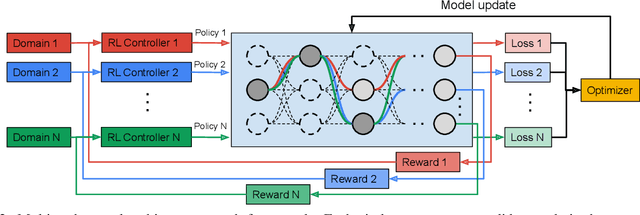
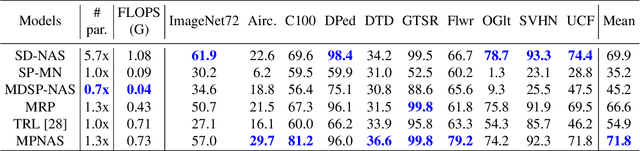
Learning multiple domains/tasks with a single model is important for improving data efficiency and lowering inference cost for numerous vision tasks, especially on resource-constrained mobile devices. However, hand-crafting a multi-domain/task model can be both tedious and challenging. This paper proposes a novel approach to automatically learn a multi-path network for multi-domain visual classification on mobile devices. The proposed multi-path network is learned from neural architecture search by applying one reinforcement learning controller for each domain to select the best path in the super-network created from a MobileNetV3-like search space. An adaptive balanced domain prioritization algorithm is proposed to balance optimizing the joint model on multiple domains simultaneously. The determined multi-path model selectively shares parameters across domains in shared nodes while keeping domain-specific parameters within non-shared nodes in individual domain paths. This approach effectively reduces the total number of parameters and FLOPS, encouraging positive knowledge transfer while mitigating negative interference across domains. Extensive evaluations on the Visual Decathlon dataset demonstrate that the proposed multi-path model achieves state-of-the-art performance in terms of accuracy, model size, and FLOPS against other approaches using MobileNetV3-like architectures. Furthermore, the proposed method improves average accuracy over learning single-domain models individually, and reduces the total number of parameters and FLOPS by 78% and 32% respectively, compared to the approach that simply bundles single-domain models for multi-domain learning.
The Rate-Distortion-Accuracy Tradeoff: JPEG Case Study
Aug 03, 2020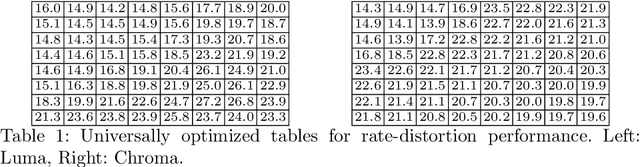
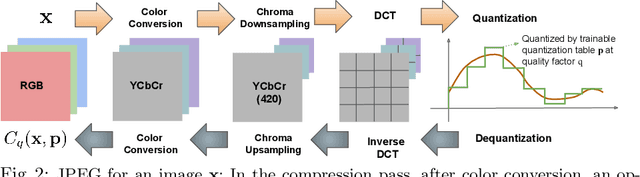
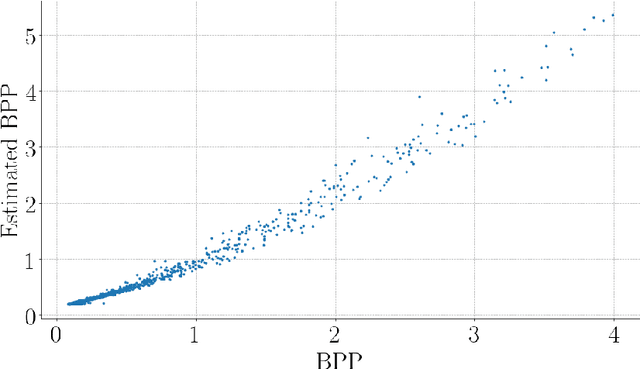
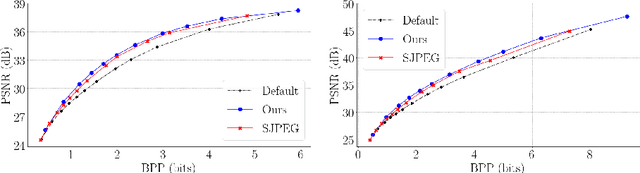
Handling digital images is almost always accompanied by a lossy compression in order to facilitate efficient transmission and storage. This introduces an unavoidable tension between the allocated bit-budget (rate) and the faithfulness of the resulting image to the original one (distortion). An additional complicating consideration is the effect of the compression on recognition performance by given classifiers (accuracy). This work aims to explore this rate-distortion-accuracy tradeoff. As a case study, we focus on the design of the quantization tables in the JPEG compression standard. We offer a novel optimal tuning of these tables via continuous optimization, leveraging a differential implementation of both the JPEG encoder-decoder and an entropy estimator. This enables us to offer a unified framework that considers the interplay between rate, distortion and classification accuracy. In all these fronts, we report a substantial boost in performance by a simple and easily implemented modification of these tables.