 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training via Denoising for Molecular Property Prediction
May 31, 2022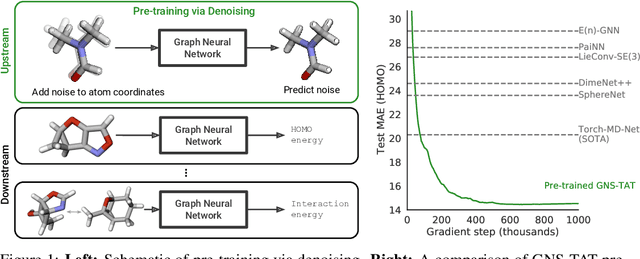
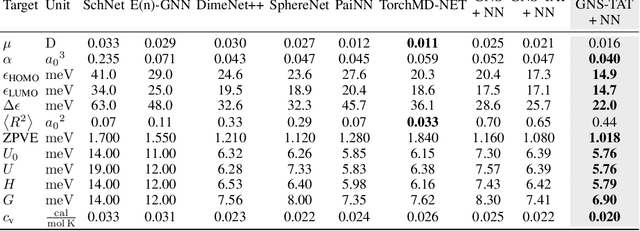
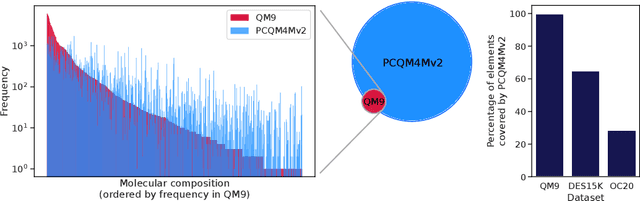
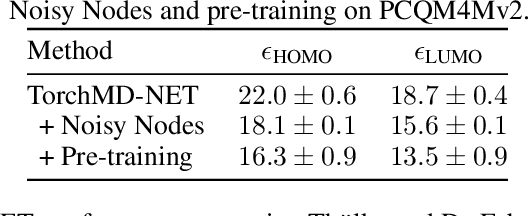
Many important problems involving molecular property prediction from 3D structures have limited data, posing a generalization challenge for neural networks. In this paper, we describe a pre-training technique that utilizes large datasets of 3D molecular structures at equilibrium to learn meaningful representations for downstream tasks. Inspired by recent advances in noise regularization, our pre-training objective is based on denoising. Relying on the well-known link between denoising autoencoders and score-matching, we also show that the objective corresponds to learning a molecular force field -- arising from approximating the physical state distribution with a mixture of Gaussians -- directly from equilibrium structures. Our experiments demonstrate that using this pre-training objective significantly improves performance on multiple benchmarks, achieving a new state-of-the-art on the majority of targets in the widely used QM9 dataset. Our analysis then provides practical insights into the effects of different factors -- dataset sizes, model size and architecture, and the choice of upstream and downstream datasets -- on pre-training.
Transframer: Arbitrary Frame Prediction with Generative Models
Mar 18, 2022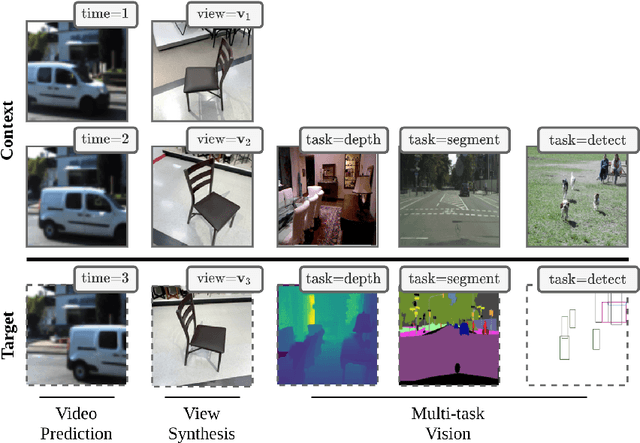

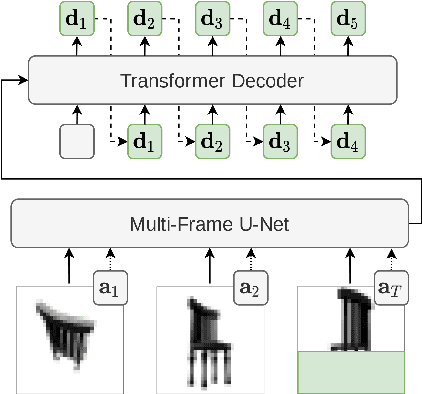

We present a general-purpose framework for image modelling and vision tasks based on probabilistic frame prediction. Our approach unifies a broad range of tasks, from image segmentation, to novel view synthesis and video interpolation. We pair this framework with an architecture we term Transframer, which uses U-Net and Transformer components to condition on annotated context frames, and outputs sequences of sparse, compressed image features. Transframer is the state-of-the-art on a variety of video generation benchmarks, is competitive with the strongest models on few-shot view synthesis, and can generate coherent 30 second videos from a single image without any explicit geometric information. A single generalist Transframer simultaneously produces promising results on 8 tasks, including semantic segmentation, image classification and optical flow prediction with no task-specific architectural components, demonstrating that multi-task computer vision can be tackled using probabilistic image models. Our approach can in principle be applied to a wide range of applications that require learning the conditional structure of annotated image-formatted data.
Rediscovering orbital mechanics with machine learning
Feb 04, 2022
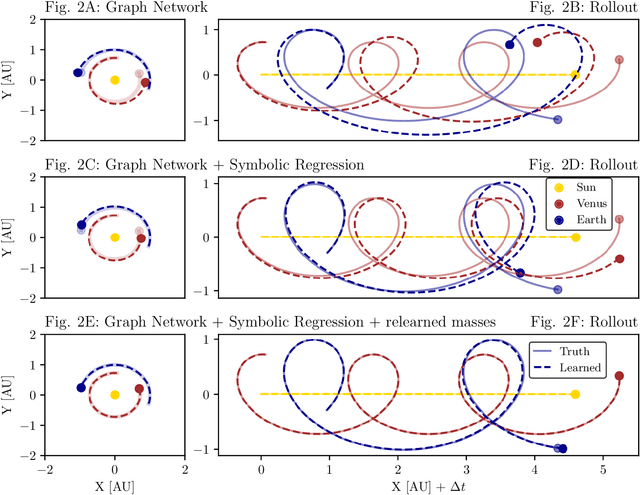
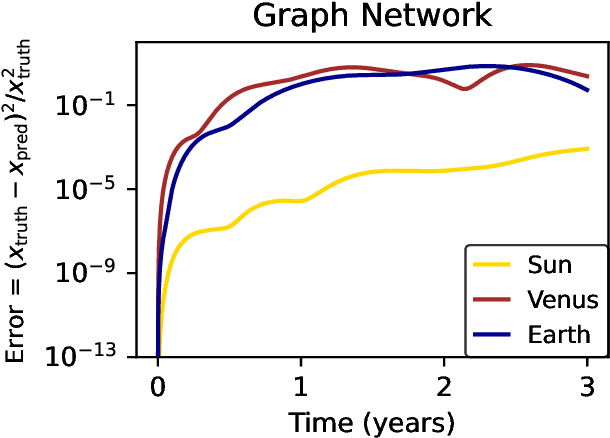
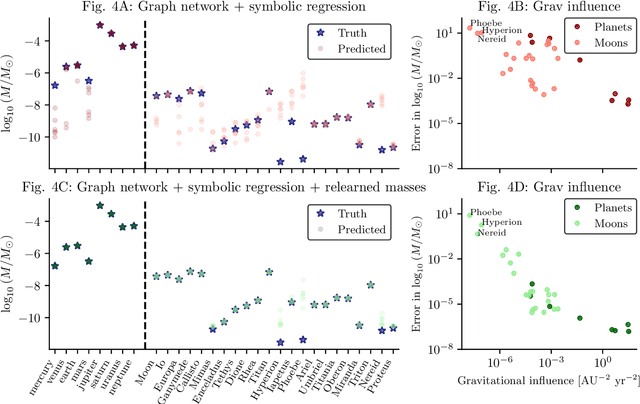
We present an approach for using machine learning to automatically discover the governing equations and hidden properties of real physical systems from observations. We train a "graph neural network" to simulate the dynamics of our solar system's Sun, planets, and large moons from 30 years of trajectory data. We then use symbolic regression to discover an analytical expression for the force law implicitly learned by the neural network, which our results showed is equivalent to Newton's law of gravitation. The key assumptions that were required were translational and rotational equivariance, and Newton's second and third laws of motion. Our approach correctly discovered the form of the symbolic force law. Furthermore, our approach did not require any assumptions about the masses of planets and moons or physical constants. They, too, were accurately inferred through our methods. Though, of course, the classical law of gravitation has been known since Isaac Newton, our result serves as a validation that our method can discover unknown laws and hidden properties from observed data. More broadly this work represents a key step toward realizing the potential of machine learning for accelerating scientific discovery.
Physical Design using Differentiable Learned Simulators
Feb 01, 2022Designing physical artifacts that serve a purpose - such as tools and other functional structures - is central to engineering as well as everyday human behavior. Though automating design has tremendous promise, general-purpose methods do not yet exist. Here we explore a simple, fast, and robust approach to inverse design which combines learned forward simulators based on graph neural networks with gradient-based design optimization. Our approach solves high-dimensional problems with complex physical dynamics, including designing surfaces and tools to manipulate fluid flows and optimizing the shape of an airfoil to minimize drag. This framework produces high-quality designs by propagating gradients through trajectories of hundreds of steps, even when using models that were pre-trained for single-step predictions on data substantially different from the design tasks. In our fluid manipulation tasks, the resulting designs outperformed those found by sampling-based optimization techniques. In airfoil design, they matched the quality of those obtained with a specialized solver. Our results suggest that despite some remaining challenges, machine learning-based simulators are maturing to the point where they can support general-purpose design optimization across a variety of domains.
Learned Coarse Models for Efficient Turbulence Simulation
Jan 04, 2022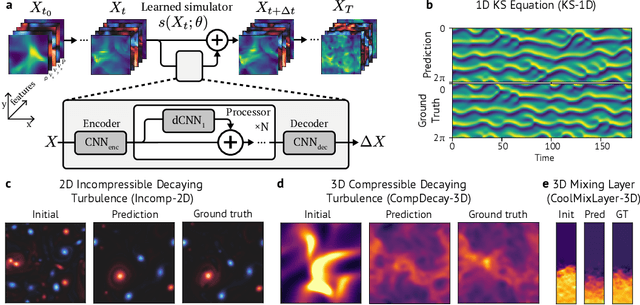
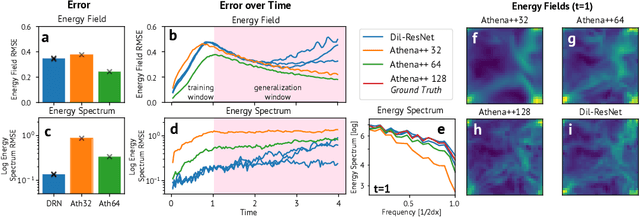

Turbulence simulation with classical numerical solvers requires very high-resolution grids to accurately resolve dynamics. Here we train learned simulators at low spatial and temporal resolutions to capture turbulent dynamics generated at high resolution. We show that our proposed model can simulate turbulent dynamics more accurately than classical numerical solvers at the same low resolutions across various scientifically relevant metrics. Our model is trained end-to-end from data and is capable of learning a range of challenging chaotic and turbulent dynamics at low resolution, including trajectories generated by the state-of-the-art Athena++ engine. We show that our simpler, general-purpose architecture outperforms various more specialized, turbulence-specific architectures from the learned turbulence simulation literature. In general, we see that learned simulators yield unstable trajectories; however, we show that tuning training noise and temporal downsampling solves this problem. We also find that while generalization beyond the training distribution is a challenge for learned models, training noise, convolutional architectures, and added loss constraints can help. Broadly, we conclude that our learned simulator outperforms traditional solvers run on coarser grids, and emphasize that simple design choices can offer stability and robust generalization.
Constraint-based graph network simulator
Dec 16, 2021
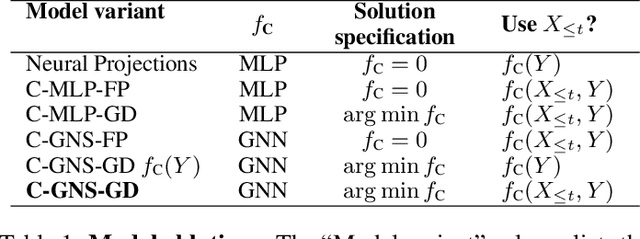

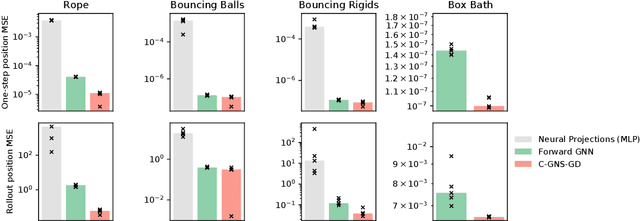
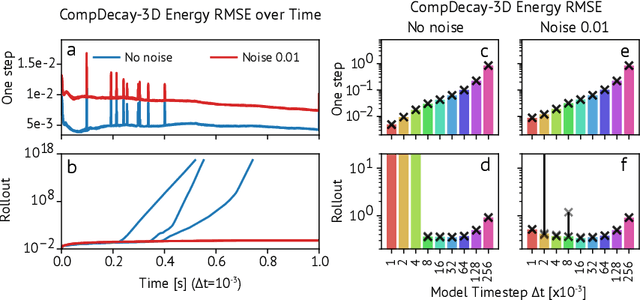
In the rapidly advancing area of learned physical simulators, nearly all methods train forward models that directly predict future states from input states. However, many traditional simulation engines use a constraint-based approach instead of direct prediction. Here we present a framework for constraint-based learned simulation, where a scalar constraint function is implemented as a neural network, and future predictions are computed as the solutions to optimization problems under these learned constraints. We implement our method using a graph neural network as the constraint function and gradient descent as the constraint solver. The architecture can be trained by standard backpropagation. We test the model on a variety of challenging physical domains, including simulated ropes, bouncing balls, colliding irregular shapes and splashing fluids. Our model achieves better or comparable performance to top learned simulators. A key advantage of our model is the ability to generalize to more solver iterations at test time to improve the simulation accuracy. We also show how hand-designed constraints can be added at test time to satisfy objectives which were not present in the training data, which is not possible with forward approaches. Our constraint-based framework is applicable to any setting where forward learned simulators are used, and demonstrates how learned simulators can leverage additional inductive biases as well as the techniques from the field of numerical methods.
Learning ground states of quantum Hamiltonians with graph networks
Oct 12, 2021
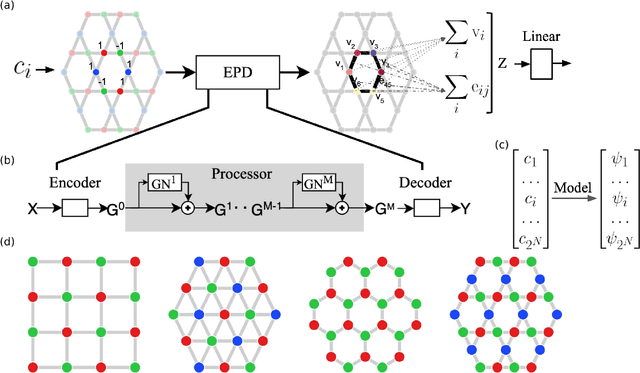
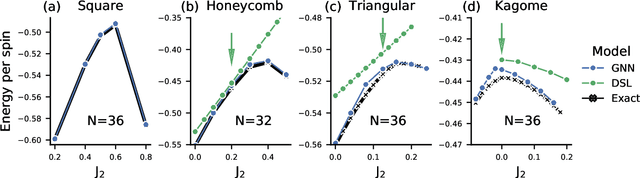
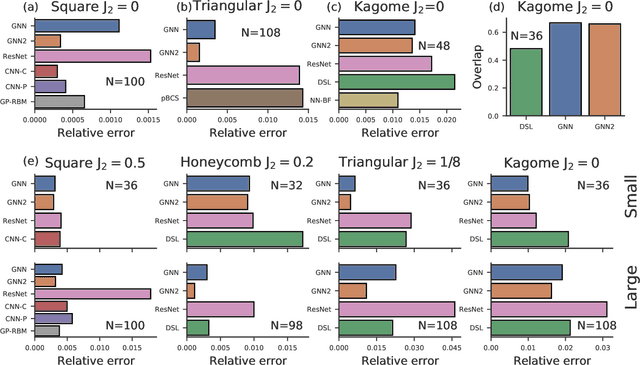
Solving for the lowest energy eigenstate of the many-body Schrodinger equation is a cornerstone problem that hinders understanding of a variety of quantum phenomena. The difficulty arises from the exponential nature of the Hilbert space which casts the governing equations as an eigenvalue problem of exponentially large, structured matrices. Variational methods approach this problem by searching for the best approximation within a lower-dimensional variational manifold. In this work we use graph neural networks to define a structured variational manifold and optimize its parameters to find high quality approximations of the lowest energy solutions on a diverse set of Heisenberg Hamiltonians. Using graph networks we learn distributed representations that by construction respect underlying physical symmetries of the problem and generalize to problems of larger size. Our approach achieves state-of-the-art results on a set of quantum many-body benchmark problems and works well on problems whose solutions are not positive-definite. The discussed techniques hold promise of being a useful tool for studying quantum many-body systems and providing insights into optimization and implicit modeling of exponentially-sized objects.
Very Deep Graph Neural Networks Via Noise Regularisation
Jun 15, 2021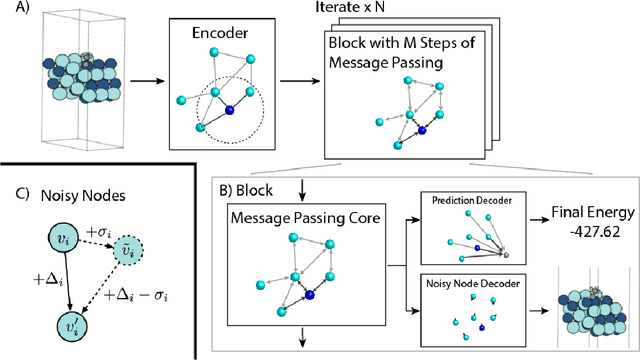
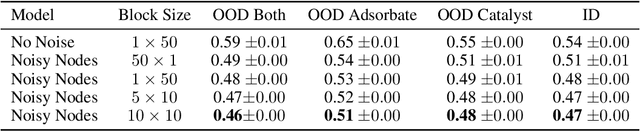
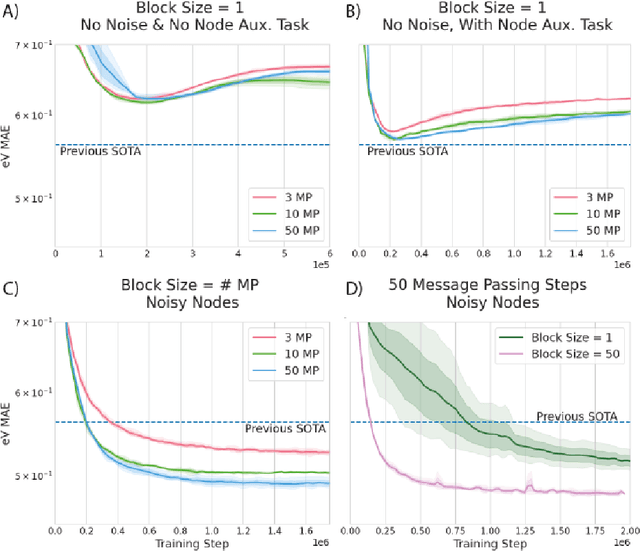
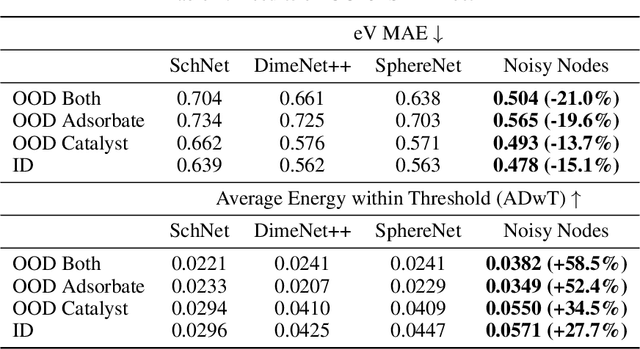
Graph Neural Networks (GNNs) perform learned message passing over an input graph, but conventional wisdom says performing more than handful of steps makes training difficult and does not yield improved performance. Here we show the contrary. We train a deep GNN with up to 100 message passing steps and achieve several state-of-the-art results on two challenging molecular property prediction benchmarks, Open Catalyst 2020 IS2RE and QM9. Our approach depends crucially on a novel but simple regularisation method, which we call ``Noisy Nodes'', in which we corrupt the input graph with noise and add an auxiliary node autoencoder loss if the task is graph property prediction. Our results show this regularisation method allows the model to monotonically improve in performance with increased message passing steps. Our work opens new opportunities for reaping the benefits of deep neural networks in the space of graph and other structured prediction problems.
A Bayesian neural network predicts the dissolution of compact planetary systems
Jan 11, 2021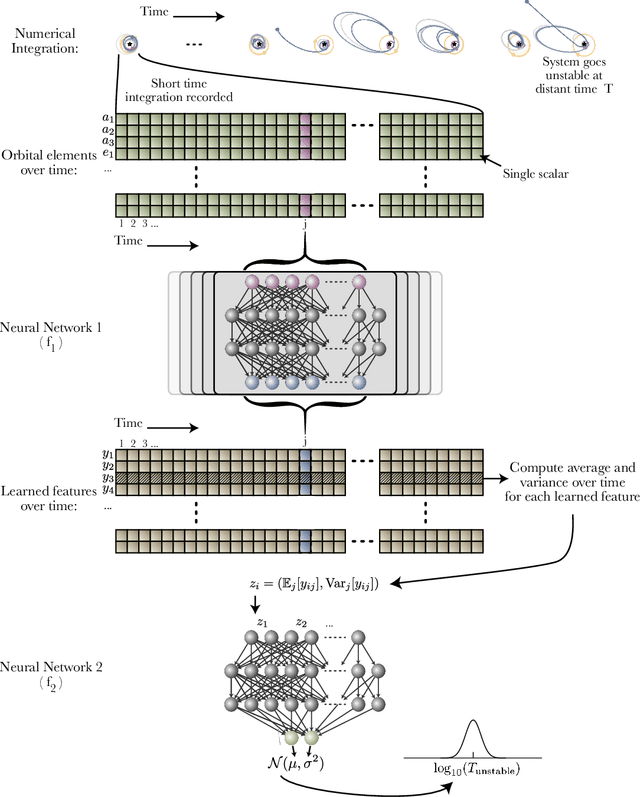
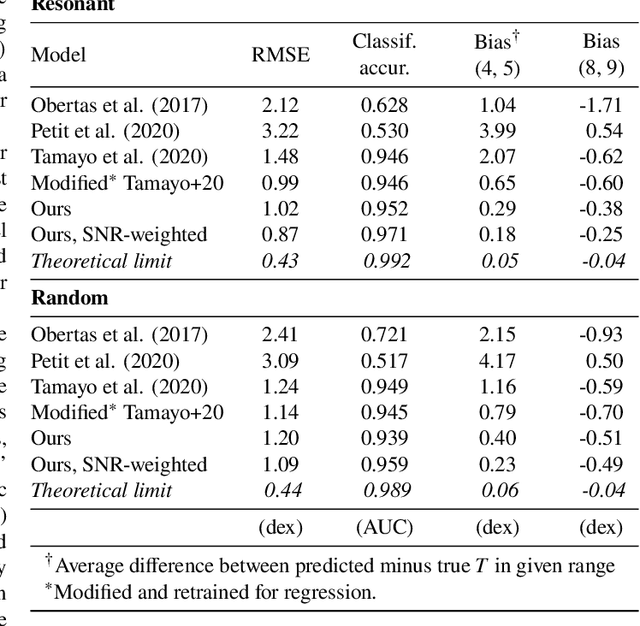
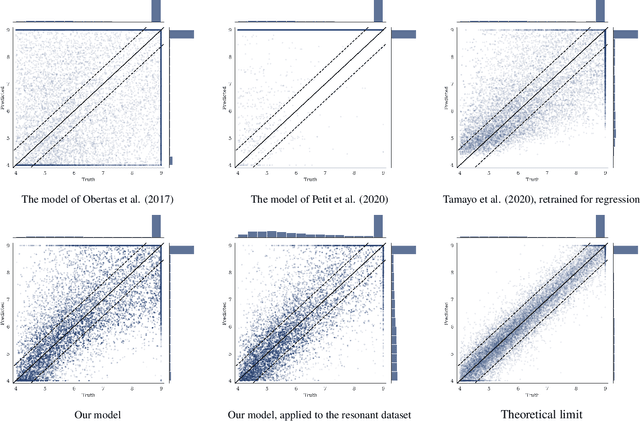
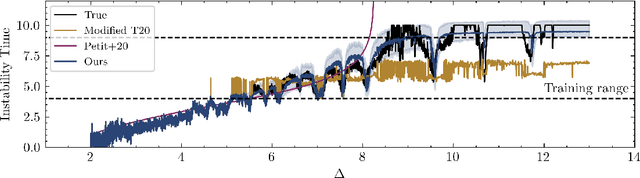
Despite over three hundred years of effort, no solutions exist for predicting when a general planetary configuration will become unstable. We introduce a deep learning architecture to push forward this problem for compact systems. While current machine learning algorithms in this area rely on scientist-derived instability metrics, our new technique learns its own metrics from scratch, enabled by a novel internal structure inspired from dynamics theory. Our Bayesian neural network model can accurately predict not only if, but also when a compact planetary system with three or more planets will go unstable. Our model, trained directly from short N-body time series of raw orbital elements, is more than two orders of magnitude more accurate at predicting instability times than analytical estimators, while also reducing the bias of existing machine learning algorithms by nearly a factor of three. Despite being trained on compact resonant and near-resonant three-planet configurations, the model demonstrates robust generalization to both non-resonant and higher multiplicity configurations, in the latter case outperforming models fit to that specific set of integrations. The model computes instability estimates up to five orders of magnitude faster than a numerical integrator, and unlike previous efforts provides confidence intervals on its predictions. Our inference model is publicly available in the SPOCK package, with training code open-sourced.
Graph Networks with Spectral Message Passing
Dec 31, 2020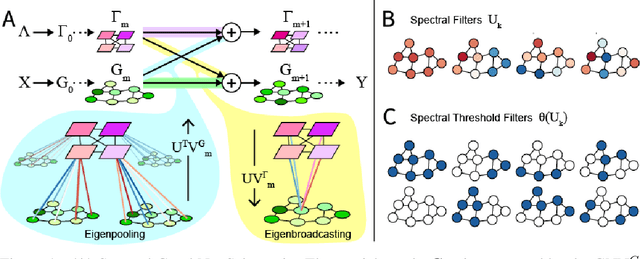
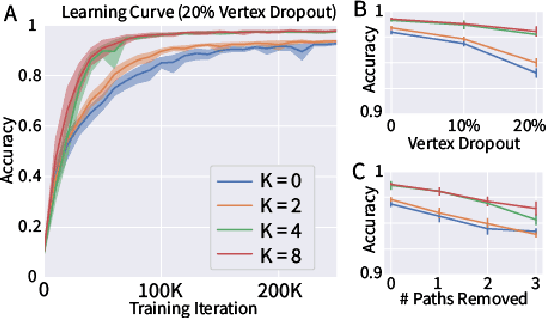
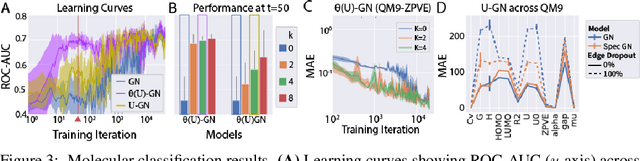
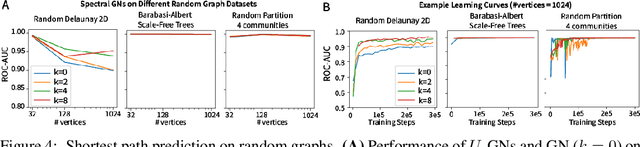
Graph Neural Networks (GNNs) are the subject of intense focus by the machine learning community for problems involving relational reasoning. GNNs can be broadly divided into spatial and spectral approaches. Spatial approaches use a form of learned message-passing, in which interactions among vertices are computed locally, and information propagates over longer distances on the graph with greater numbers of message-passing steps. Spectral approaches use eigendecompositions of the graph Laplacian to produce a generalization of spatial convolutions to graph structured data which access information over short and long time scales simultaneously. Here we introduce the Spectral Graph Network, which applies message passing to both the spatial and spectral domains. Our model projects vertices of the spatial graph onto the Laplacian eigenvectors, which are each represented as vertices in a fully connected "spectral graph", and then applies learned message passing to them. We apply this model to various benchmark tasks including a graph-based variant of MNIST classification, molecular property prediction on MoleculeNet and QM9, and shortest path problems on random graphs. Our results show that the Spectral GN promotes efficient training, reaching high performance with fewer training iterations despite having more parameters. The model also provides robustness to edge dropout and outperforms baselines for the classification tasks. We also explore how these performance benefits depend on properties of the dataset.