 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Engineering for Everyone
Feb 23, 2021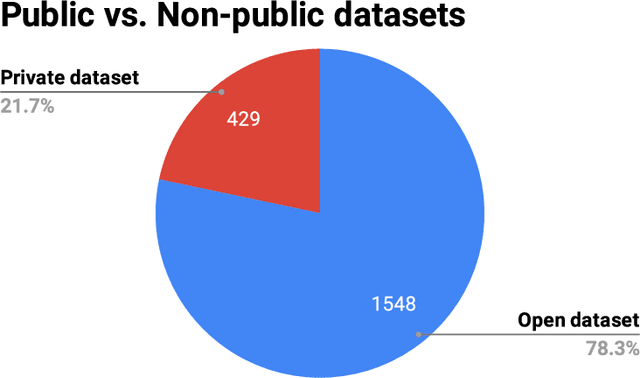
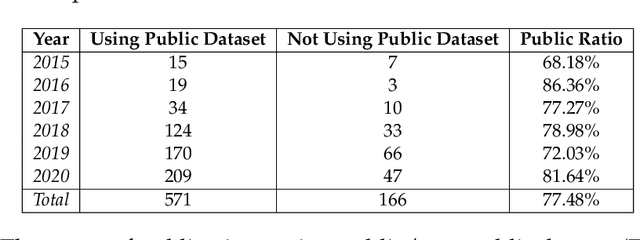
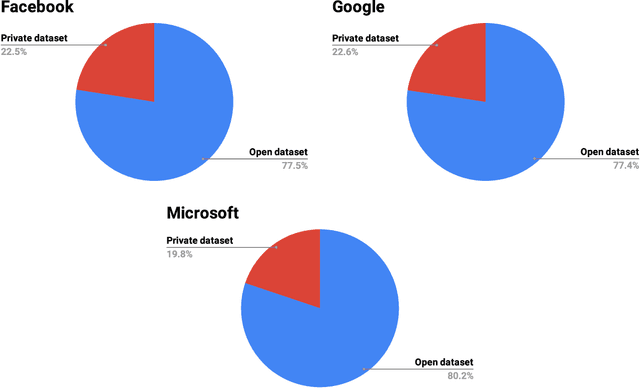
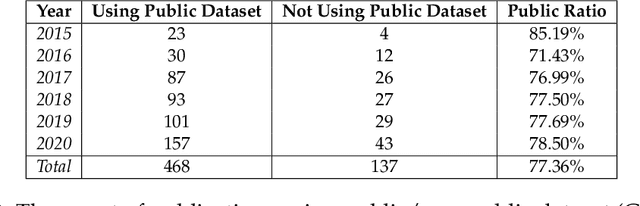
Data engineering is one of the fastest-growing fields within machine learning (ML). As ML becomes more common, the appetite for data grows more ravenous. But ML requires more data than individual teams of data engineers can readily produce, which presents a severe challenge to ML deployment at scale. Much like the software-engineering revolution, where mass adoption of open-source software replaced the closed, in-house development model for infrastructure code, there is a growing need to enable rapid development and open contribution to massive machine learning data sets. This article shows that open-source data sets are the rocket fuel for research and innovation at even some of the largest AI organizations. Our analysis of nearly 2000 research publications from Facebook, Google and Microsoft over the past five years shows the widespread use and adoption of open data sets. Open data sets that are easily accessible to the public are vital to accelerating ML innovation for everyone. But such open resources are scarce in the wild. So, what if we are able to accelerate data-set creation via automatic data set generation tools?
TensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems
Oct 20, 2020

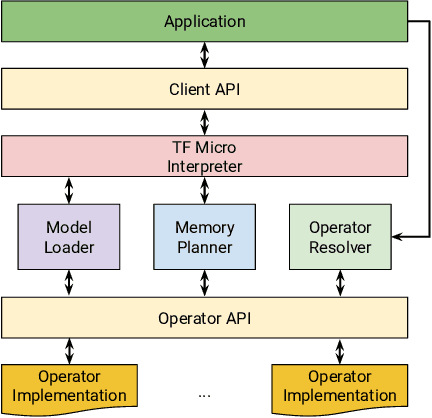
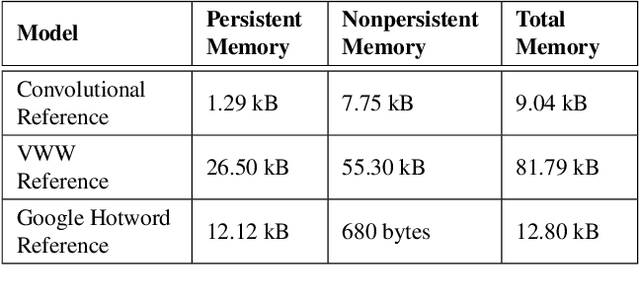
Deep learning inference on embedded devices is a burgeoning field with myriad applications because tiny embedded devices are omnipresent. But we must overcome major challenges before we can benefit from this opportunity. Embedded processors are severely resource constrained. Their nearest mobile counterparts exhibit at least a 100---1,000x difference in compute capability, memory availability, and power consumption. As a result, the machine-learning (ML) models and associated ML inference framework must not only execute efficiently but also operate in a few kilobytes of memory. Also, the embedded devices' ecosystem is heavily fragmented. To maximize efficiency, system vendors often omit many features that commonly appear in mainstream systems, including dynamic memory allocation and virtual memory, that allow for cross-platform interoperability. The hardware comes in many flavors (e.g., instruction-set architecture and FPU support, or lack thereof). We introduce TensorFlow Lite Micro (TF Micro), an open-source ML inference framework for running deep-learning models on embedded systems. TF Micro tackles the efficiency requirements imposed by embedded-system resource constraints and the fragmentation challenges that make cross-platform interoperability nearly impossible. The framework adopts a unique interpreter-based approach that provides flexibility while overcoming these challenges. This paper explains the design decisions behind TF Micro and describes its implementation details. Also, we present an evaluation to demonstrate its low resource requirement and minimal run-time performance overhead.
Visual Wake Words Dataset
Jun 12, 2019

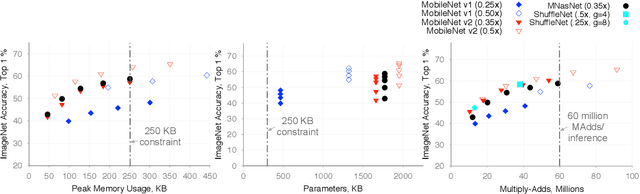
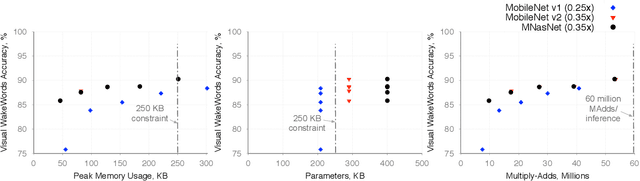
The emergence of Internet of Things (IoT) applications requires intelligence on the edge. Microcontrollers provide a low-cost compute platform to deploy intelligent IoT applications using machine learning at scale, but have extremely limited on-chip memory and compute capability. To deploy computer vision on such devices, we need tiny vision models that fit within a few hundred kilobytes of memory footprint in terms of peak usage and model size on device storage. To facilitate the development of microcontroller friendly models, we present a new dataset, Visual Wake Words, that represents a common microcontroller vision use-case of identifying whether a person is present in the image or not, and provides a realistic benchmark for tiny vision models. Within a limited memory footprint of 250 KB, several state-of-the-art mobile models achieve accuracy of 85-90% on the Visual Wake Words dataset. We anticipate the proposed dataset will advance the research on tiny vision models that can push the pareto-optimal boundary in terms of accuracy versus memory usage for microcontroller applications.
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
Apr 09, 2018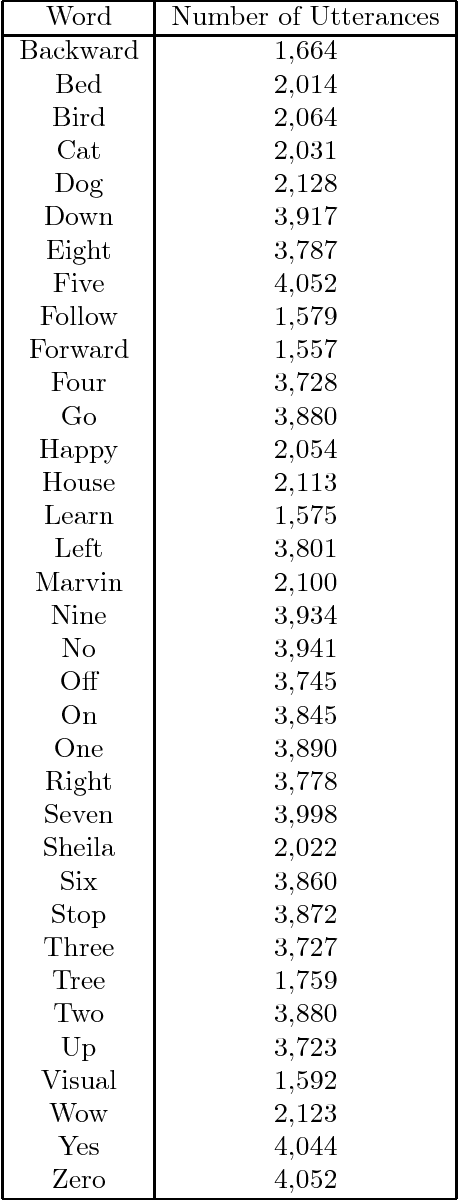
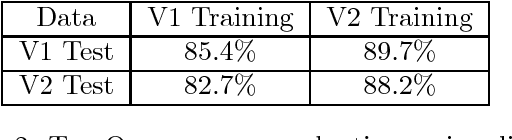
Describes an audio dataset of spoken words designed to help train and evaluate keyword spotting systems. Discusses why this task is an interesting challenge, and why it requires a specialized dataset that is different from conventional datasets used for automatic speech recognition of full sentences. Suggests a methodology for reproducible and comparable accuracy metrics for this task. Describes how the data was collected and verified, what it contains, previous versions and properties. Concludes by reporting baseline results of models trained on this dataset.
TensorFlow: A system for large-scale machine learning
May 31, 2016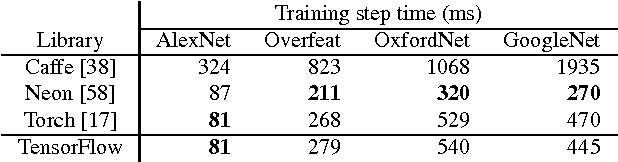

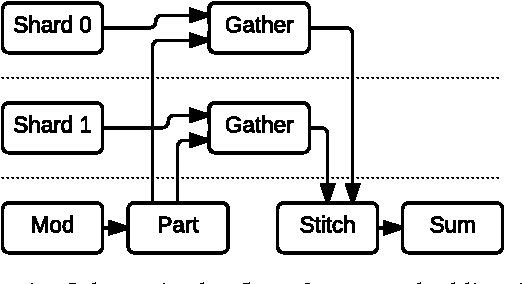
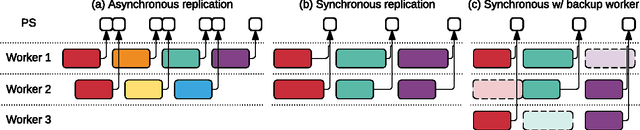
TensorFlow is a machine learning system that operates at large scale and in heterogeneous environments. TensorFlow uses dataflow graphs to represent computation, shared state, and the operations that mutate that state. It maps the nodes of a dataflow graph across many machines in a cluster, and within a machine across multiple computational devices, including multicore CPUs, general-purpose GPUs, and custom designed ASICs known as Tensor Processing Units (TPUs). This architecture gives flexibility to the application developer: whereas in previous "parameter server" designs the management of shared state is built into the system, TensorFlow enables developers to experiment with novel optimizations and training algorithms. TensorFlow supports a variety of applications, with particularly strong support for training and inference on deep neural networks. Several Google services use TensorFlow in production, we have released it as an open-source project, and it has become widely used for machine learning research. In this paper, we describe the TensorFlow dataflow model in contrast to existing systems, and demonstrate the compelling performance that TensorFlow achieves for several real-world applications.
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Mar 16, 2016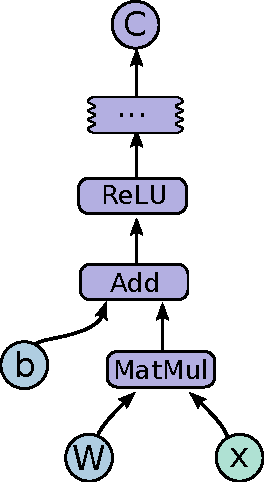

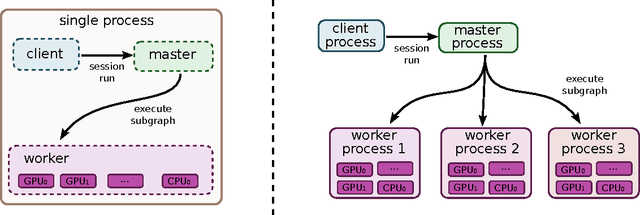
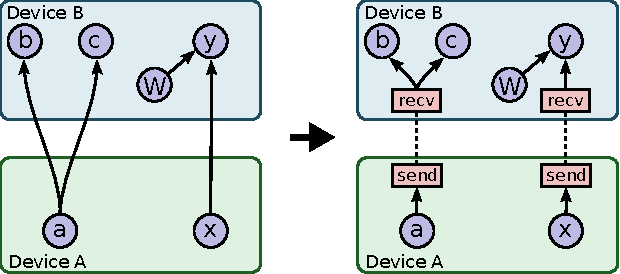
TensorFlow is an interface for expressing machine learning algorithms, and an implementation for executing such algorithms. A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.