 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable knowledge base completion with superposition memories
Oct 24, 2021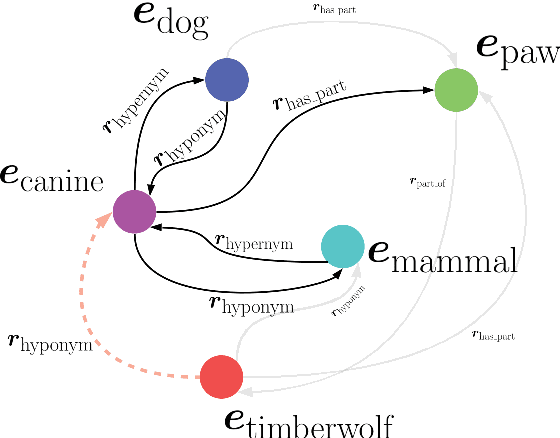
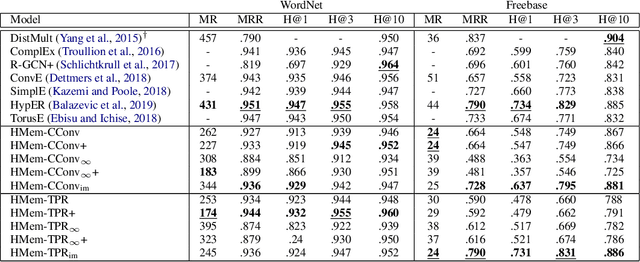
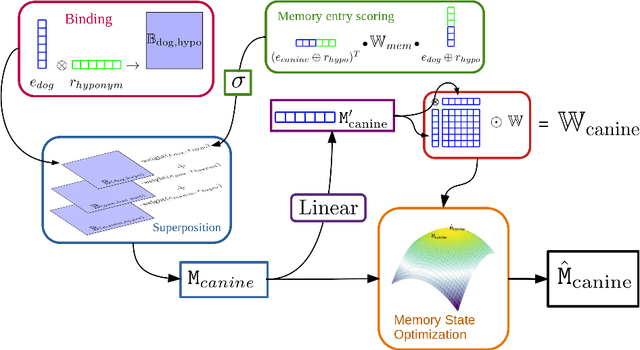
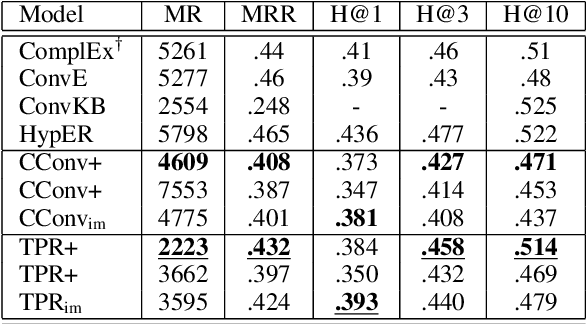
We present Harmonic Memory Networks (HMem), a neural architecture for knowledge base completion that models entities as weighted sums of pairwise bindings between an entity's neighbors and corresponding relations. Since entities are modeled as aggregated neighborhoods, representations of unseen entities can be generated on the fly. We demonstrate this with two new datasets: WNGen and FBGen. Experiments show that the model is SOTA on benchmarks, and flexible enough to evolve without retraining as the knowledge graph grows.
Enriching Transformers with Structured Tensor-Product Representations for Abstractive Summarization
Jun 02, 2021
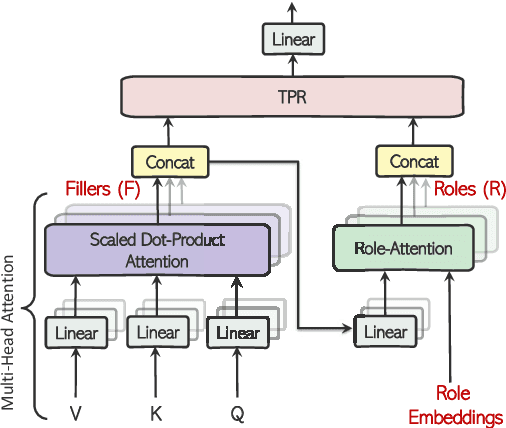
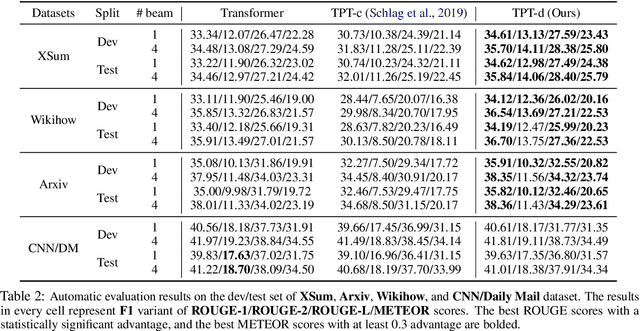
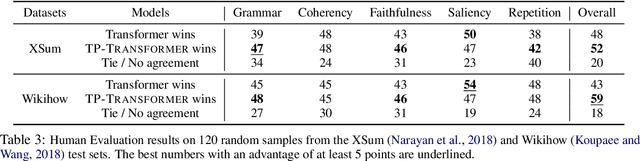
Abstractive summarization, the task of generating a concise summary of input documents, requires: (1) reasoning over the source document to determine the salient pieces of information scattered across the long document, and (2) composing a cohesive text by reconstructing these salient facts into a shorter summary that faithfully reflects the complex relations connecting these facts. In this paper, we adapt TP-TRANSFORMER (Schlag et al., 2019), an architecture that enriches the original Transformer (Vaswani et al., 2017) with the explicitly compositional Tensor Product Representation (TPR), for the task of abstractive summarization. The key feature of our model is a structural bias that we introduce by encoding two separate representations for each token to represent the syntactic structure (with role vectors) and semantic content (with filler vectors) separately. The model then binds the role and filler vectors into the TPR as the layer output. We argue that the structured intermediate representations enable the model to take better control of the contents (salient facts) and structures (the syntax that connects the facts) when generating the summary. Empirically, we show that our TP-TRANSFORMER outperforms the Transformer and the original TP-TRANSFORMER significantly on several abstractive summarization datasets based on both automatic and human evaluations. On several syntactic and semantic probing tasks, we demonstrate the emergent structural information in the role vectors and improved syntactic interpretability in the TPR layer outputs. Code and models are available at https://github.com/jiangycTarheel/TPT-Summ.
Compositional Processing Emerges in Neural Networks Solving Math Problems
May 19, 2021
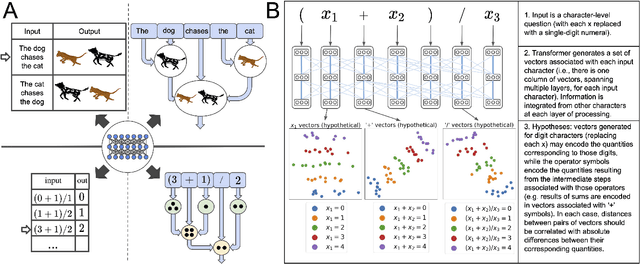
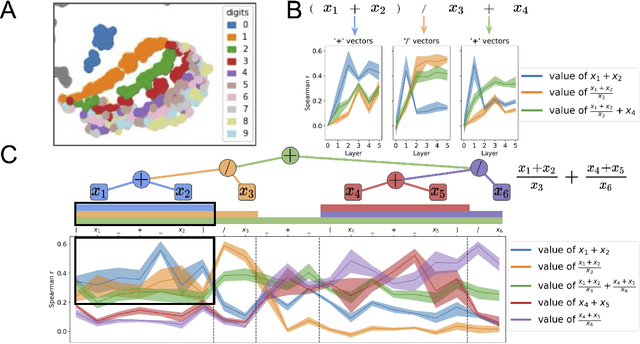
A longstanding question in cognitive science concerns the learning mechanisms underlying compositionality in human cognition. Humans can infer the structured relationships (e.g., grammatical rules) implicit in their sensory observations (e.g., auditory speech), and use this knowledge to guide the composition of simpler meanings into complex wholes. Recent progress in artificial neural networks has shown that when large models are trained on enough linguistic data, grammatical structure emerges in their representations. We extend this work to the domain of mathematical reasoning, where it is possible to formulate precise hypotheses about how meanings (e.g., the quantities corresponding to numerals) should be composed according to structured rules (e.g., order of operations). Our work shows that neural networks are not only able to infer something about the structured relationships implicit in their training data, but can also deploy this knowledge to guide the composition of individual meanings into composite wholes.
Neuro-Symbolic Representations for Video Captioning: A Case for Leveraging Inductive Biases for Vision and Language
Nov 18, 2020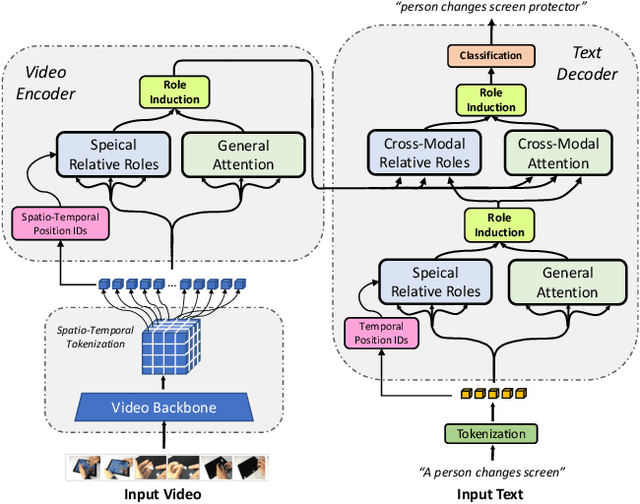
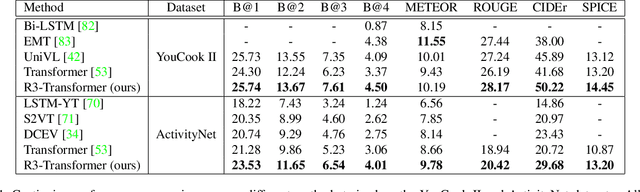
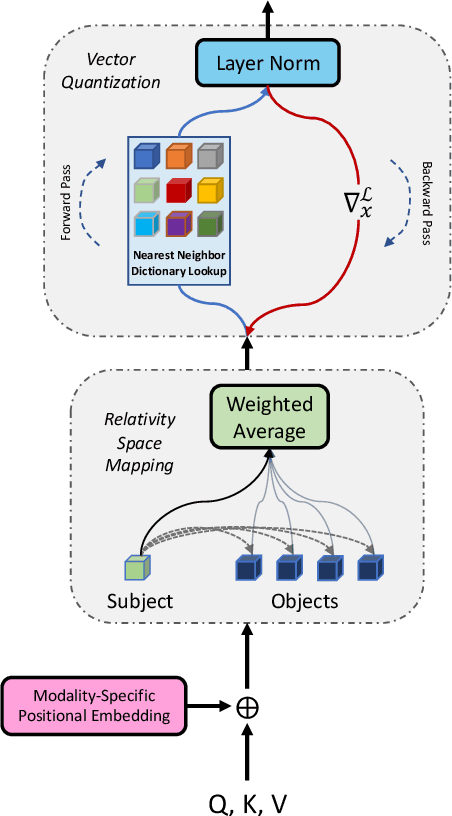
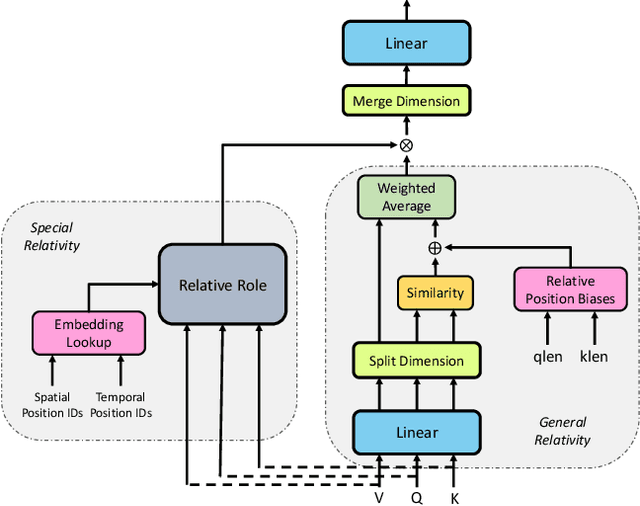
Neuro-symbolic representations have proved effective in learning structure information in vision and language. In this paper, we propose a new model architecture for learning multi-modal neuro-symbolic representations for video captioning. Our approach uses a dictionary learning-based method of learning relations between videos and their paired text descriptions. We refer to these relations as relative roles and leverage them to make each token role-aware using attention. This results in a more structured and interpretable architecture that incorporates modality-specific inductive biases for the captioning task. Intuitively, the model is able to learn spatial, temporal, and cross-modal relations in a given pair of video and text. The disentanglement achieved by our proposal gives the model more capacity to capture multi-modal structures which result in captions with higher quality for videos. Our experiments on two established video captioning datasets verifies the effectiveness of the proposed approach based on automatic metrics. We further conduct a human evaluation to measure the grounding and relevance of the generated captions and observe consistent improvement for the proposed model. The codes and trained models can be found at https://github.com/hassanhub/R3Transformer
Universal linguistic inductive biases via meta-learning
Jun 29, 2020
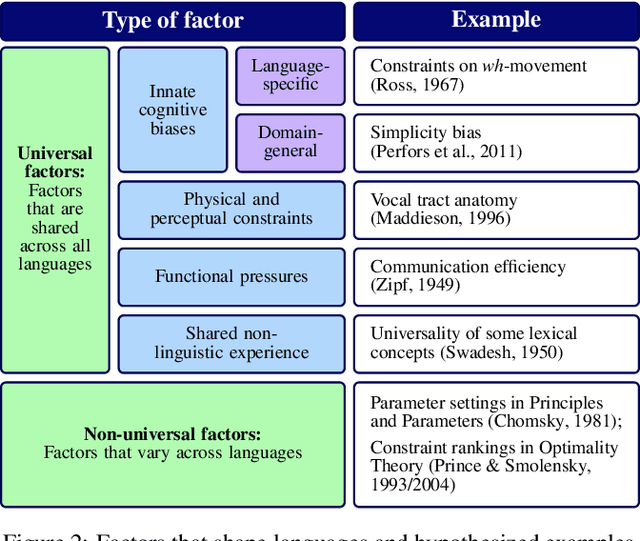

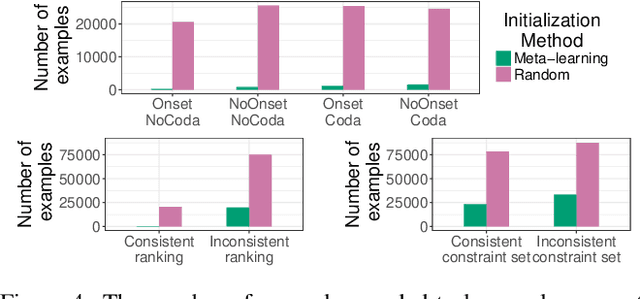
How do learners acquire languages from the limited data available to them? This process must involve some inductive biases - factors that affect how a learner generalizes - but it is unclear which inductive biases can explain observed patterns in language acquisition. To facilitate computational modeling aimed at addressing this question, we introduce a framework for giving particular linguistic inductive biases to a neural network model; such a model can then be used to empirically explore the effects of those inductive biases. This framework disentangles universal inductive biases, which are encoded in the initial values of a neural network's parameters, from non-universal factors, which the neural network must learn from data in a given language. The initial state that encodes the inductive biases is found with meta-learning, a technique through which a model discovers how to acquire new languages more easily via exposure to many possible languages. By controlling the properties of the languages that are used during meta-learning, we can control the inductive biases that meta-learning imparts. We demonstrate this framework with a case study based on syllable structure. First, we specify the inductive biases that we intend to give our model, and then we translate those inductive biases into a space of languages from which a model can meta-learn. Finally, using existing analysis techniques, we verify that our approach has imparted the linguistic inductive biases that it was intended to impart.
Discovering the Compositional Structure of Vector Representations with Role Learning Networks
Nov 17, 2019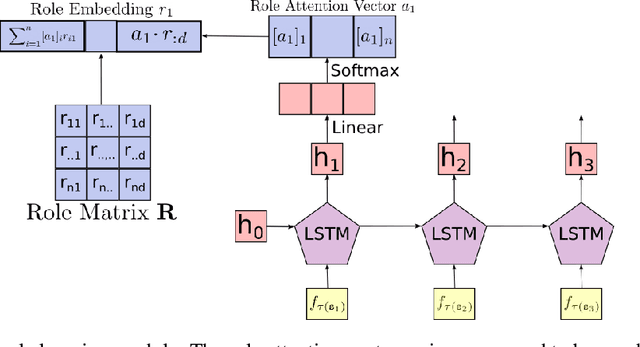



Neural networks are able to perform tasks that rely on compositional structure even though they lack obvious mechanisms for representing this structure. To analyze the internal representations that enable such success, we propose ROLE, a technique that detects whether these representations implicitly encode symbolic structure. ROLE learns to approximate the representations of a target encoder E by learning a symbolic constituent structure and an embedding of that structure into E's representational vector space. The constituents of the approximating symbol structure are defined by structural positions - roles - that can be filled by symbols. We show that when E is constructed to explicitly embed a particular type of structure (string or tree), ROLE successfully extracts the ground-truth roles defining that structure. We then analyze a GRU seq2seq network trained to perform a more complex compositional task (SCAN), where there is no ground truth role scheme available. For this model, ROLE successfully discovers an interpretable symbolic structure that the model implicitly uses to perform the SCAN task, providing a comprehensive account of the representations that drive the behavior of a frequently-used but hard-to-interpret type of model. We verify the causal importance of the discovered symbolic structure by showing that, when we systematically manipulate hidden embeddings based on this symbolic structure, the model's resulting output is changed in the way predicted by our analysis. Finally, we use ROLE to explore whether popular sentence embedding models are capturing compositional structure and find evidence that they are not; we conclude by suggesting how insights from ROLE can be used to impart new inductive biases to improve the compositional abilities of such models.
HUBERT Untangles BERT to Improve Transfer across NLP Tasks
Oct 25, 2019
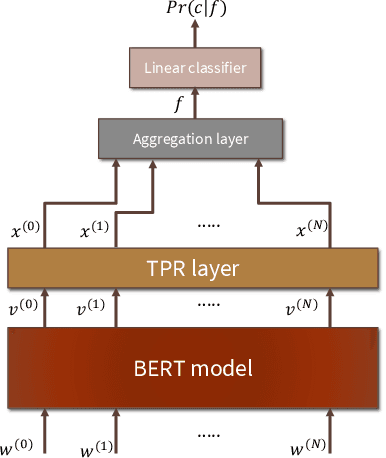

We introduce HUBERT which combines the structured-representational power of Tensor-Product Representations (TPRs) and BERT, a pre-trained bidirectional Transformer language model. We show that there is shared structure between different NLP datasets that HUBERT, but not BERT, is able to learn and leverage. We validate the effectiveness of our model on the GLUE benchmark and HANS dataset. Our experiment results show that untangling data-specific semantics from general language structure is key for better transfer among NLP tasks.
Enhancing the Transformer with Explicit Relational Encoding for Math Problem Solving
Oct 15, 2019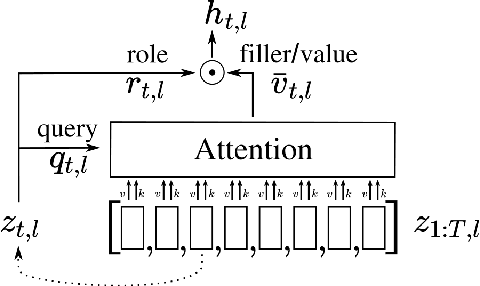
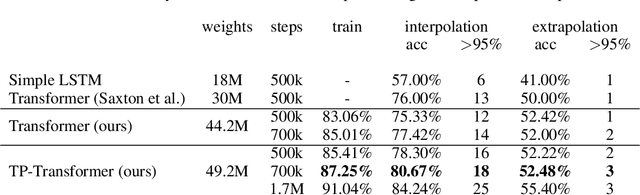
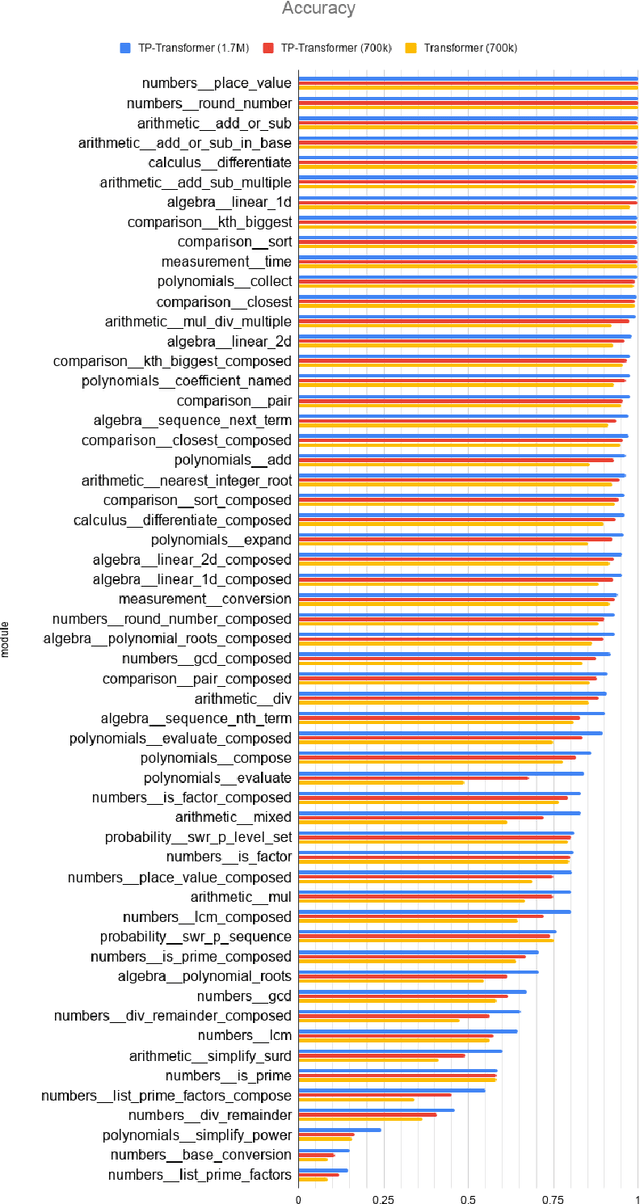

We incorporate Tensor-Product Representations within the Transformer in order to better support the explicit representation of relation structure. Our Tensor-Product Transformer (TP-Transformer) sets a new state of the art on the recently-introduced Mathematics Dataset containing 56 categories of free-form math word-problems. The essential component of the model is a novel attention mechanism, called TP-Attention, which explicitly encodes the relations between each Transformer cell and the other cells from which values have been retrieved by attention. TP-Attention goes beyond linear combination of retrieved values, strengthening representation-building and resolving ambiguities introduced by multiple layers of standard attention. The TP-Transformer's attention maps give better insights into how it is capable of solving the Mathematics Dataset's challenging problems. Pretrained models and code will be made available after publication.
Natural- to formal-language generation using Tensor Product Representations
Oct 05, 2019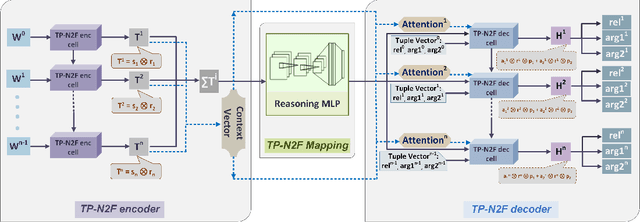

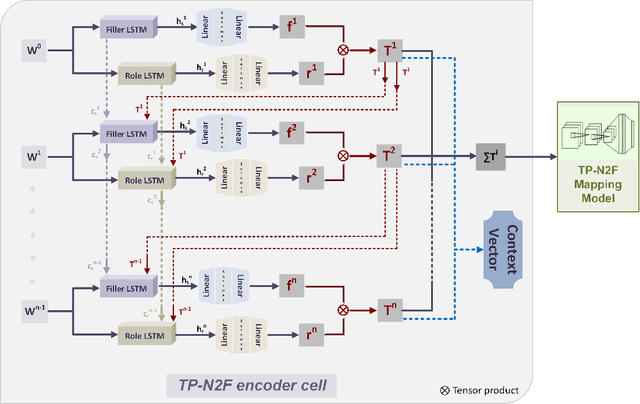
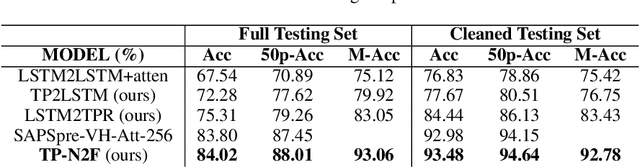
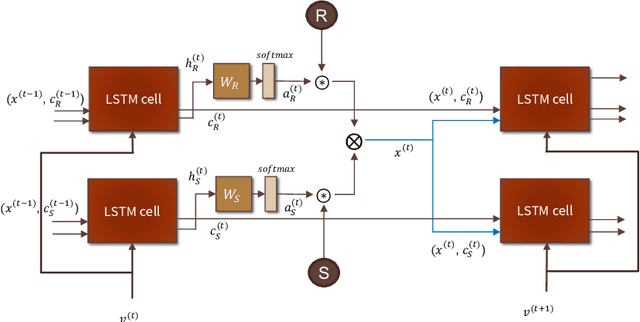
Generating formal-language represented by relational tuples, such as Lisp programs or mathematical expressions, from a natural-language input is an extremely challenging task because it requires to explicitly capture discrete symbolic structural information from the input to generate the output. Most state-of-the-art neural sequence models do not explicitly capture such structure information, and thus do not perform well on these tasks. In this paper, we propose a new encoder-decoder model based on Tensor Product Representations (TPRs) for Natural- to Formal-language generation, called TP-N2F. The encoder of TP-N2F employs TPR 'binding' to encode natural-language symbolic structure in vector space and the decoder uses TPR 'unbinding' to generate a sequence of relational tuples, each consisting of a relation (or operation) and a number of arguments, in symbolic space. TP-N2F considerably outperforms LSTM-based Seq2Seq models, creating a new state of the art results on two benchmarks: the MathQA dataset for math problem solving, and the AlgoList dataset for program synthesis. Ablation studies show that improvements are mainly attributed to the use of TPRs in both the encoder and decoder to explicitly capture relational structure information for symbolic reasoning.
RNNs Implicitly Implement Tensor Product Representations
Dec 20, 2018

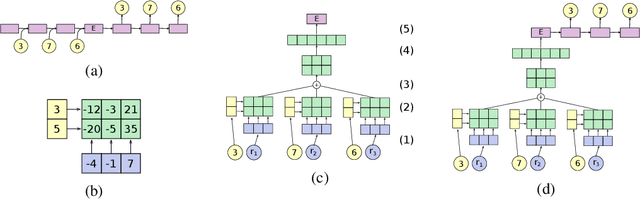

Recurrent neural networks (RNNs) can learn continuous vector representations of symbolic structures such as sequences and sentences; these representations often exhibit linear regularities (analogies). Such regularities motivate our hypothesis that RNNs that show such regularities implicitly compile symbolic structures into tensor product representations (TPRs; Smolensky, 1990), which additively combine tensor products of vectors representing roles (e.g., sequence positions) and vectors representing fillers (e.g., particular words). To test this hypothesis, we introduce Tensor Product Decomposition Networks (TPDNs), which use TPRs to approximate existing vector representations. We demonstrate using synthetic data that TPDNs can successfully approximate linear and tree-based RNN autoencoder representations, suggesting that these representations exhibit interpretable compositional structure; we explore the settings that lead RNNs to induce such structure-sensitive representations. By contrast, further TPDN experiments show that the representations of four models trained to encode naturally-occurring sentences can be largely approximated with a bag-of-words, with only marginal improvements from more sophisticated structures. We conclude that TPDNs provide a powerful method for interpreting vector representations, and that standard RNNs can induce compositional sequence representations that are remarkably well approximated by TPRs; at the same time, existing training tasks for sentence representation learning may not be sufficient for inducing robust structural representations.