 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Evaluation of Adversarial Perturbations for Sequence-to-Sequence Models
Mar 19, 2019
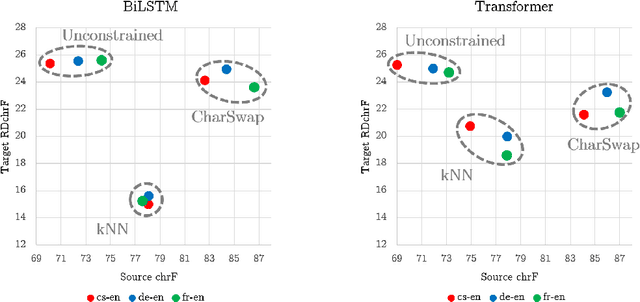
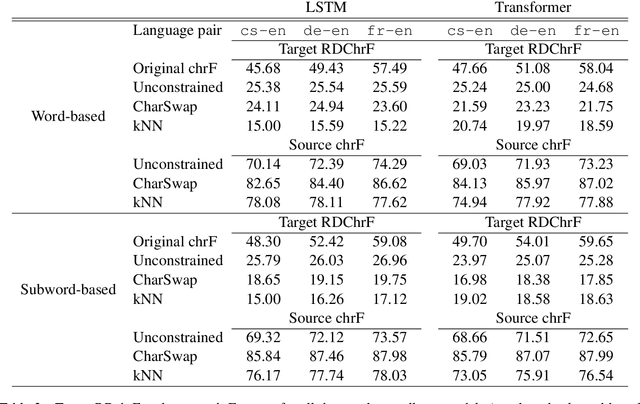

Adversarial examples --- perturbations to the input of a model that elicit large changes in the output --- have been shown to be an effective way of assessing the robustness of sequence-to-sequence (seq2seq) models. However, these perturbations only indicate weaknesses in the model if they do not change the input so significantly that it legitimately results in changes in the expected output. This fact has largely been ignored in the evaluations of the growing body of related literature. Using the example of untargeted attacks on machine translation (MT), we propose a new evaluation framework for adversarial attacks on seq2seq models that takes the semantic equivalence of the pre- and post-perturbation input into account. Using this framework, we demonstrate that existing methods may not preserve meaning in general, breaking the aforementioned assumption that source side perturbations should not result in changes in the expected output. We further use this framework to demonstrate that adding additional constraints on attacks allows for adversarial perturbations that are more meaning-preserving, but nonetheless largely change the output sequence. Finally, we show that performing untargeted adversarial training with meaning-preserving attacks is beneficial to the model in terms of adversarial robustness, without hurting test performance. A toolkit implementing our evaluation framework is released at https://github.com/pmichel31415/teapot-nlp.
MTNT: A Testbed for Machine Translation of Noisy Text
Sep 02, 2018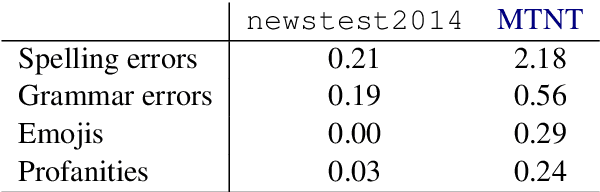
Noisy or non-standard input text can cause disastrous mistranslations in most modern Machine Translation (MT) systems, and there has been growing research interest in creating noise-robust MT systems. However, as of yet there are no publicly available parallel corpora of with naturally occurring noisy inputs and translations, and thus previous work has resorted to evaluating on synthetically created datasets. In this paper, we propose a benchmark dataset for Machine Translation of Noisy Text (MTNT), consisting of noisy comments on Reddit (www.reddit.com) and professionally sourced translations. We commissioned translations of English comments into French and Japanese, as well as French and Japanese comments into English, on the order of 7k-37k sentences per language pair. We qualitatively and quantitatively examine the types of noise included in this dataset, then demonstrate that existing MT models fail badly on a number of noise-related phenomena, even after performing adaptation on a small training set of in-domain data. This indicates that this dataset can provide an attractive testbed for methods tailored to handling noisy text in MT. The data is publicly available at www.cs.cmu.edu/~pmichel1/mtnt/.
Extreme Adaptation for Personalized Neural Machine Translation
May 04, 2018
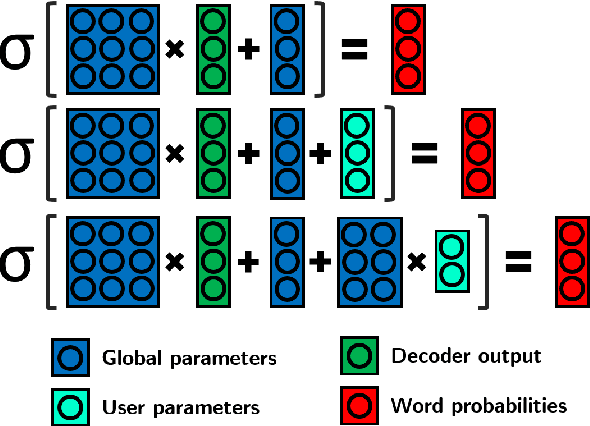
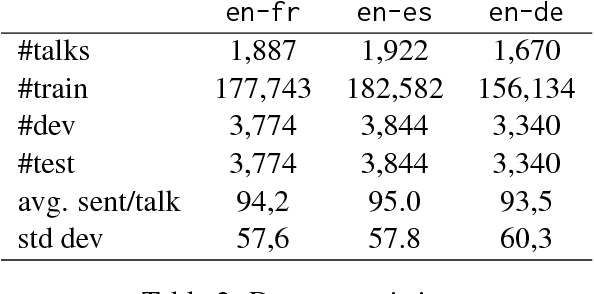
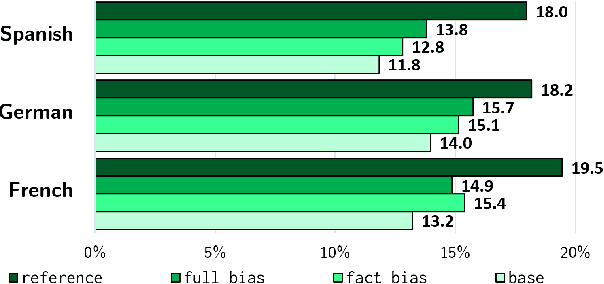
Every person speaks or writes their own flavor of their native language, influenced by a number of factors: the content they tend to talk about, their gender, their social status, or their geographical origin. When attempting to perform Machine Translation (MT), these variations have a significant effect on how the system should perform translation, but this is not captured well by standard one-size-fits-all models. In this paper, we propose a simple and parameter-efficient adaptation technique that only requires adapting the bias of the output softmax to each particular user of the MT system, either directly or through a factored approximation. Experiments on TED talks in three languages demonstrate improvements in translation accuracy, and better reflection of speaker traits in the target text.
Does the Geometry of Word Embeddings Help Document Classification? A Case Study on Persistent Homology Based Representations
May 31, 2017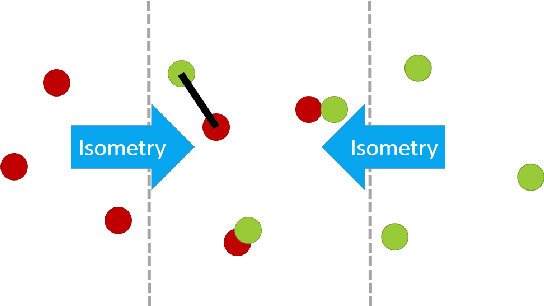

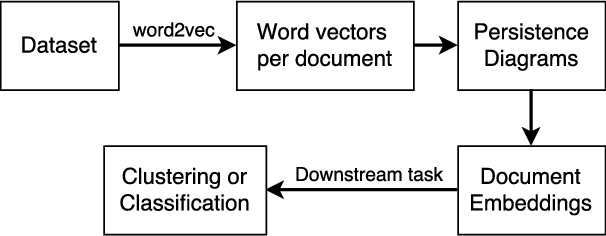

We investigate the pertinence of methods from algebraic topology for text data analysis. These methods enable the development of mathematically-principled isometric-invariant mappings from a set of vectors to a document embedding, which is stable with respect to the geometry of the document in the selected metric space. In this work, we evaluate the utility of these topology-based document representations in traditional NLP tasks, specifically document clustering and sentiment classification. We find that the embeddings do not benefit text analysis. In fact, performance is worse than simple techniques like $\textit{tf-idf}$, indicating that the geometry of the document does not provide enough variability for classification on the basis of topic or sentiment in the chosen datasets.
Blind phoneme segmentation with temporal prediction errors
May 27, 2017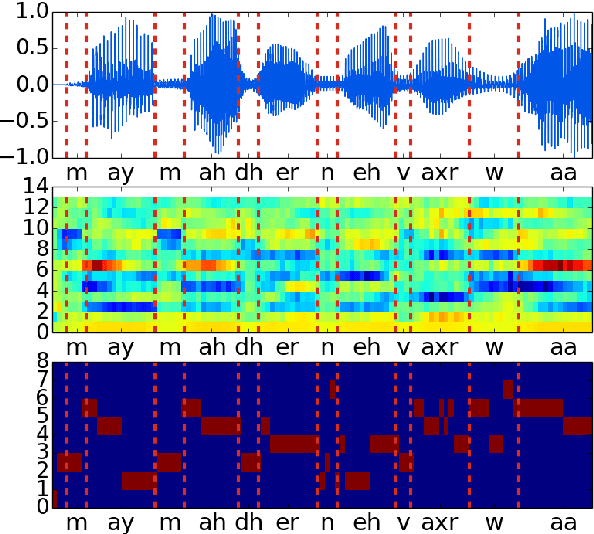
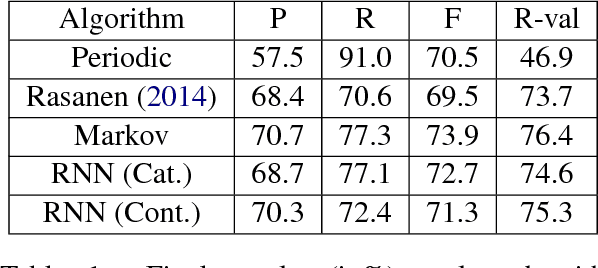
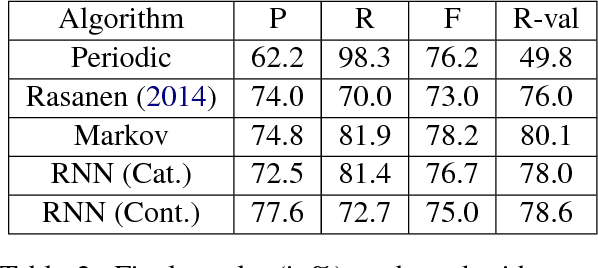
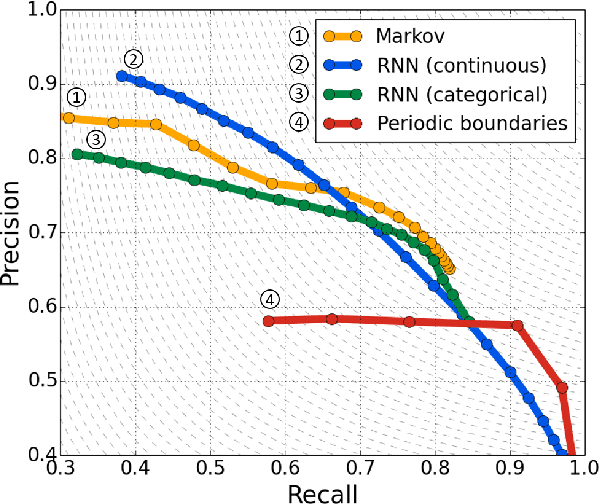
Phonemic segmentation of speech is a critical step of speech recognition systems. We propose a novel unsupervised algorithm based on sequence prediction models such as Markov chains and recurrent neural network. Our approach consists in analyzing the error profile of a model trained to predict speech features frame-by-frame. Specifically, we try to learn the dynamics of speech in the MFCC space and hypothesize boundaries from local maxima in the prediction error. We evaluate our system on the TIMIT dataset, with improvements over similar methods.
DyNet: The Dynamic Neural Network Toolkit
Jan 15, 2017
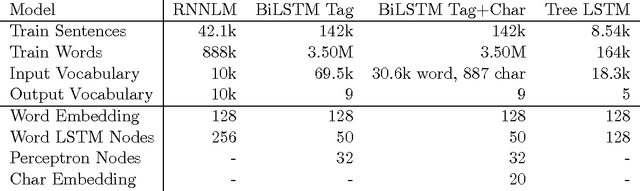

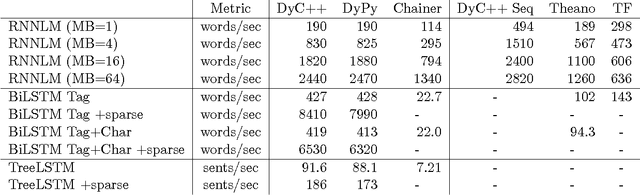
We describe DyNet, a toolkit for implementing neural network models based on dynamic declaration of network structure. In the static declaration strategy that is used in toolkits like Theano, CNTK, and TensorFlow, the user first defines a computation graph (a symbolic representation of the computation), and then examples are fed into an engine that executes this computation and computes its derivatives. In DyNet's dynamic declaration strategy, computation graph construction is mostly transparent, being implicitly constructed by executing procedural code that computes the network outputs, and the user is free to use different network structures for each input. Dynamic declaration thus facilitates the implementation of more complicated network architectures, and DyNet is specifically designed to allow users to implement their models in a way that is idiomatic in their preferred programming language (C++ or Python). One challenge with dynamic declaration is that because the symbolic computation graph is defined anew for every training example, its construction must have low overhead. To achieve this, DyNet has an optimized C++ backend and lightweight graph representation. Experiments show that DyNet's speeds are faster than or comparable with static declaration toolkits, and significantly faster than Chainer, another dynamic declaration toolkit. DyNet is released open-source under the Apache 2.0 license and available at http://github.com/clab/dynet.