 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Training Vision Transformers on Structural MRI Scans for Alzheimer's Disease Detection
Mar 14, 2023



Neuroimaging of large populations is valuable to identify factors that promote or resist brain disease, and to assist diagnosis, subtyping, and prognosis. Data-driven models such as convolutional neural networks (CNNs) have increasingly been applied to brain images to perform diagnostic and prognostic tasks by learning robust features. Vision transformers (ViT) - a new class of deep learning architectures - have emerged in recent years as an alternative to CNNs for several computer vision applications. Here we tested variants of the ViT architecture for a range of desired neuroimaging downstream tasks based on difficulty, in this case for sex and Alzheimer's disease (AD) classification based on 3D brain MRI. In our experiments, two vision transformer architecture variants achieved an AUC of 0.987 for sex and 0.892 for AD classification, respectively. We independently evaluated our models on data from two benchmark AD datasets. We achieved a performance boost of 5% and 9-10% upon fine-tuning vision transformer models pre-trained on synthetic (generated by a latent diffusion model) and real MRI scans, respectively. Our main contributions include testing the effects of different ViT training strategies including pre-training, data augmentation and learning rate warm-ups followed by annealing, as pertaining to the neuroimaging domain. These techniques are essential for training ViT-like models for neuroimaging applications where training data is usually limited. We also analyzed the effect of the amount of training data utilized on the test-time performance of the ViT via data-model scaling curves.
Few-Shot Classification of Autism Spectrum Disorder using Site-Agnostic Meta-Learning and Brain MRI
Mar 14, 2023For machine learning applications in medical imaging, the availability of training data is often limited, which hampers the design of radiological classifiers for subtle conditions such as autism spectrum disorder (ASD). Transfer learning is one method to counter this problem of low training data regimes. Here we explore the use of meta-learning for very low data regimes in the context of having prior data from multiple sites - an approach we term site-agnostic meta-learning. Inspired by the effectiveness of meta-learning for optimizing a model across multiple tasks, here we propose a framework to adapt it to learn across multiple sites. We tested our meta-learning model for classifying ASD versus typically developing controls in 2,201 T1-weighted (T1-w) MRI scans collected from 38 imaging sites as part of Autism Brain Imaging Data Exchange (ABIDE) [age: 5.2-64.0 years]. The method was trained to find a good initialization state for our model that can quickly adapt to data from new unseen sites by fine-tuning on the limited data that is available. The proposed method achieved an ROC-AUC=0.857 on 370 scans from 7 unseen sites in ABIDE using a few-shot setting of 2-way 20-shot i.e., 20 training samples per site. Our results outperformed a transfer learning baseline by generalizing across a wider range of sites as well as other related prior work. We also tested our model in a zero-shot setting on an independent test site without any additional fine-tuning. Our experiments show the promise of the proposed site-agnostic meta-learning framework for challenging neuroimaging tasks involving multi-site heterogeneity with limited availability of training data.
Transferring Models Trained on Natural Images to 3D MRI via Position Encoded Slice Models
Mar 02, 2023


Transfer learning has remarkably improved computer vision. These advances also promise improvements in neuroimaging, where training set sizes are often small. However, various difficulties arise in directly applying models pretrained on natural images to radiologic images, such as MRIs. In particular, a mismatch in the input space (2D images vs. 3D MRIs) restricts the direct transfer of models, often forcing us to consider only a few MRI slices as input. To this end, we leverage the 2D-Slice-CNN architecture of Gupta et al. (2021), which embeds all the MRI slices with 2D encoders (neural networks that take 2D image input) and combines them via permutation-invariant layers. With the insight that the pretrained model can serve as the 2D encoder, we initialize the 2D encoder with ImageNet pretrained weights that outperform those initialized and trained from scratch on two neuroimaging tasks -- brain age prediction on the UK Biobank dataset and Alzheimer's disease detection on the ADNI dataset. Further, we improve the modeling capabilities of 2D-Slice models by incorporating spatial information through position embeddings, which can improve the performance in some cases.
Curriculum Based Multi-Task Learning for Parkinson's Disease Detection
Feb 27, 2023There is great interest in developing radiological classifiers for diagnosis, staging, and predictive modeling in progressive diseases such as Parkinson's disease (PD), a neurodegenerative disease that is difficult to detect in its early stages. Here we leverage severity-based meta-data on the stages of disease to define a curriculum for training a deep convolutional neural network (CNN). Typically, deep learning networks are trained by randomly selecting samples in each mini-batch. By contrast, curriculum learning is a training strategy that aims to boost classifier performance by starting with examples that are easier to classify. Here we define a curriculum to progressively increase the difficulty of the training data corresponding to the Hoehn and Yahr (H&Y) staging system for PD (total N=1,012; 653 PD patients, 359 controls; age range: 20.0-84.9 years). Even with our multi-task setting using pre-trained CNNs and transfer learning, PD classification based on T1-weighted (T1-w) MRI was challenging (ROC AUC: 0.59-0.65), but curriculum training boosted performance (by 3.9%) compared to our baseline model. Future work with multimodal imaging may further boost performance.
Improved Prediction of Beta-Amyloid and Tau Burden Using Hippocampal Surface Multivariate Morphometry Statistics and Sparse Coding
Oct 28, 2022



Background: Beta-amyloid (A$\beta$) plaques and tau protein tangles in the brain are the defining 'A' and 'T' hallmarks of Alzheimer's disease (AD), and together with structural atrophy detectable on brain magnetic resonance imaging (MRI) scans as one of the neurodegenerative ('N') biomarkers comprise the ''ATN framework'' of AD. Current methods to detect A$\beta$/tau pathology include cerebrospinal fluid (CSF; invasive), positron emission tomography (PET; costly and not widely available), and blood-based biomarkers (BBBM; promising but mainly still in development). Objective: To develop a non-invasive and widely available structural MRI-based framework to quantitatively predict the amyloid and tau measurements. Methods: With MRI-based hippocampal multivariate morphometry statistics (MMS) features, we apply our Patch Analysis-based Surface Correntropy-induced Sparse coding and max-pooling (PASCS-MP) method combined with the ridge regression model to individual amyloid/tau measure prediction. Results: We evaluate our framework on amyloid PET/MRI and tau PET/MRI datasets from the Alzheimer's Disease Neuroimaging Initiative (ADNI). Each subject has one pair consisting of a PET image and MRI scan, collected at about the same time. Experimental results suggest that amyloid/tau measurements predicted with our PASCP-MP representations are closer to the real values than the measures derived from other approaches, such as hippocampal surface area, volume, and shape morphometry features based on spherical harmonics (SPHARM). Conclusion: The MMS-based PASCP-MP is an efficient tool that can bridge hippocampal atrophy with amyloid and tau pathology and thus help assess disease burden, progression, and treatment effects.
Secure Federated Learning for Neuroimaging
May 11, 2022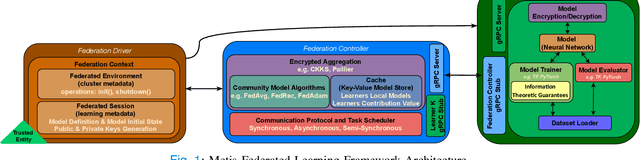
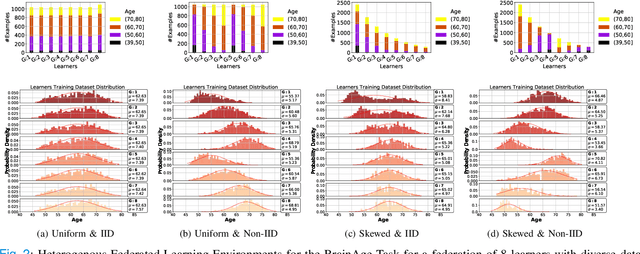
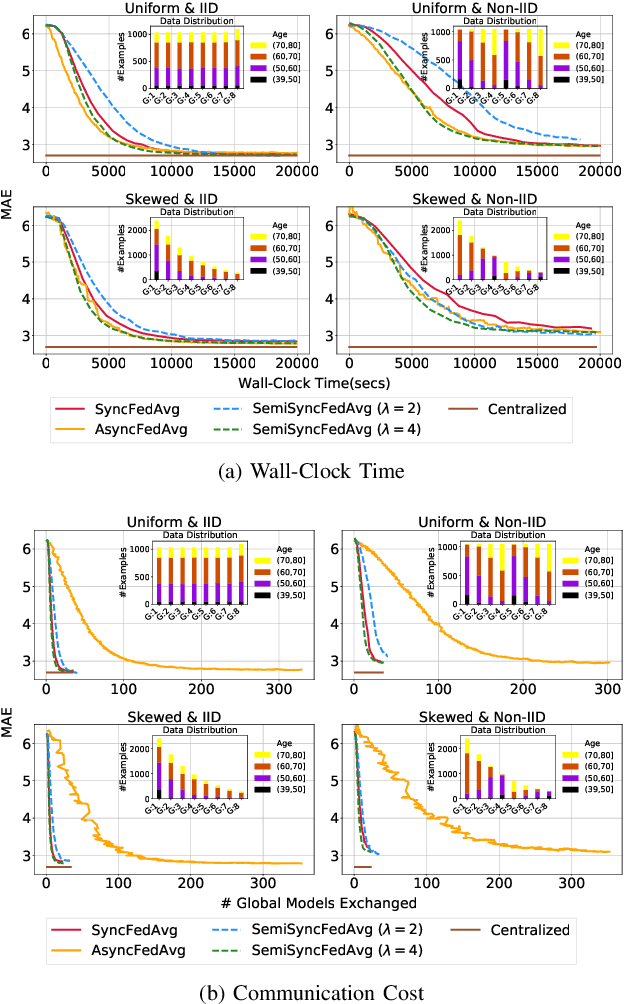
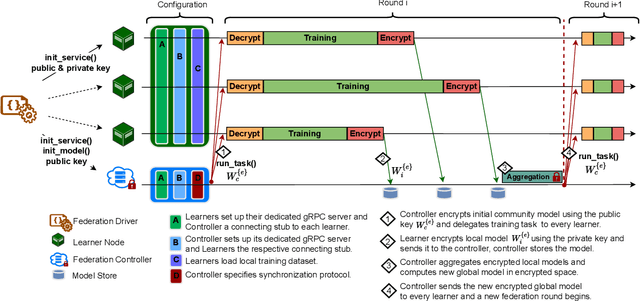
The amount of biomedical data continues to grow rapidly. However, the ability to collect data from multiple sites for joint analysis remains challenging due to security, privacy, and regulatory concerns. We present a Secure Federated Learning architecture, MetisFL, which enables distributed training of neural networks over multiple data sources without sharing data. Each site trains the neural network over its private data for some time, then shares the neural network parameters (i.e., weights, gradients) with a Federation Controller, which in turn aggregates the local models, sends the resulting community model back to each site, and the process repeats. Our architecture provides strong security and privacy. First, sample data never leaves a site. Second, neural parameters are encrypted before transmission and the community model is computed under fully-homomorphic encryption. Finally, we use information-theoretic methods to limit information leakage from the neural model to prevent a curious site from performing membership attacks. We demonstrate this architecture in neuroimaging. Specifically, we investigate training neural models to classify Alzheimer's disease, and estimate Brain Age, from magnetic resonance imaging datasets distributed across multiple sites, including heterogeneous environments where sites have different amounts of data, statistical distributions, and computational capabilities.
Predicting Tau Accumulation in Cerebral Cortex with Multivariate MRI Morphometry Measurements, Sparse Coding, and Correntropy
Oct 20, 2021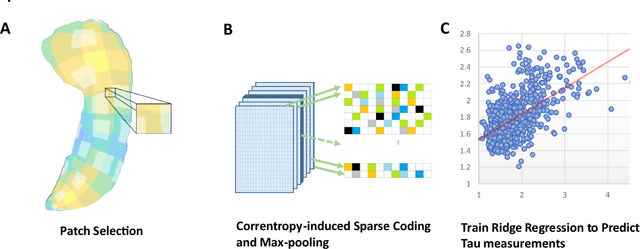
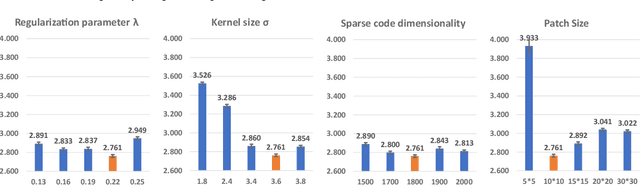
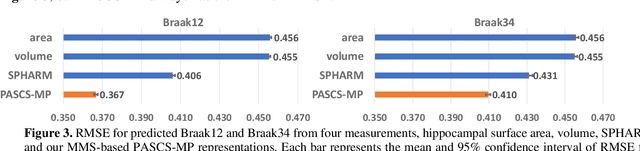
Biomarker-assisted diagnosis and intervention in Alzheimer's disease (AD) may be the key to prevention breakthroughs. One of the hallmarks of AD is the accumulation of tau plaques in the human brain. However, current methods to detect tau pathology are either invasive (lumbar puncture) or quite costly and not widely available (Tau PET). In our previous work, structural MRI-based hippocampal multivariate morphometry statistics (MMS) showed superior performance as an effective neurodegenerative biomarker for preclinical AD and Patch Analysis-based Surface Correntropy-induced Sparse coding and max-pooling (PASCS-MP) has excellent ability to generate low-dimensional representations with strong statistical power for brain amyloid prediction. In this work, we apply this framework together with ridge regression models to predict Tau deposition in Braak12 and Braak34 brain regions separately. We evaluate our framework on 925 subjects from the Alzheimer's Disease Neuroimaging Initiative (ADNI). Each subject has one pair consisting of a PET image and MRI scan which were collected at about the same times. Experimental results suggest that the representations from our MMS and PASCS-MP have stronger predictive power and their predicted Braak12 and Braak34 are closer to the real values compared to the measures derived from other approaches such as hippocampal surface area and volume, and shape morphometry features based on spherical harmonics (SPHARM).
Secure Neuroimaging Analysis using Federated Learning with Homomorphic Encryption
Aug 07, 2021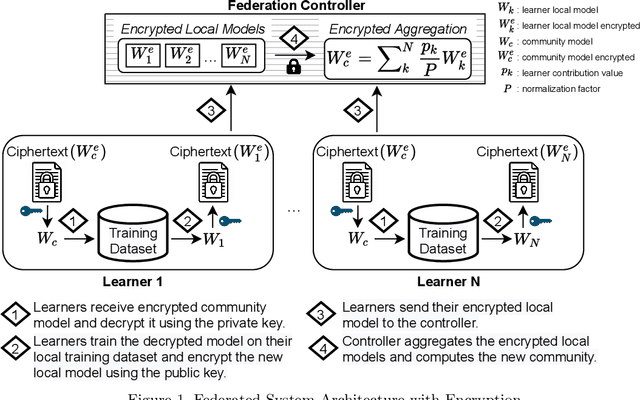
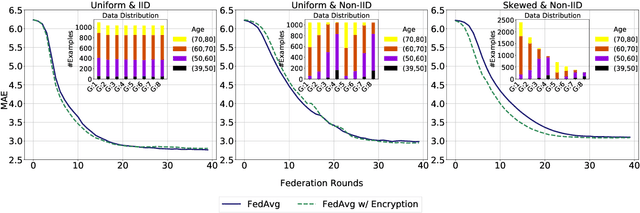
Federated learning (FL) enables distributed computation of machine learning models over various disparate, remote data sources, without requiring to transfer any individual data to a centralized location. This results in an improved generalizability of models and efficient scaling of computation as more sources and larger datasets are added to the federation. Nevertheless, recent membership attacks show that private or sensitive personal data can sometimes be leaked or inferred when model parameters or summary statistics are shared with a central site, requiring improved security solutions. In this work, we propose a framework for secure FL using fully-homomorphic encryption (FHE). Specifically, we use the CKKS construction, an approximate, floating point compatible scheme that benefits from ciphertext packing and rescaling. In our evaluation on large-scale brain MRI datasets, we use our proposed secure FL framework to train a deep learning model to predict a person's age from distributed MRI scans, a common benchmarking task, and demonstrate that there is no degradation in the learning performance between the encrypted and non-encrypted federated models.
Membership Inference Attacks on Deep Regression Models for Neuroimaging
Jun 03, 2021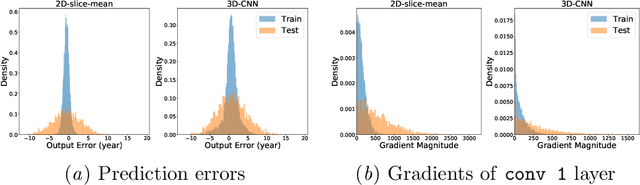


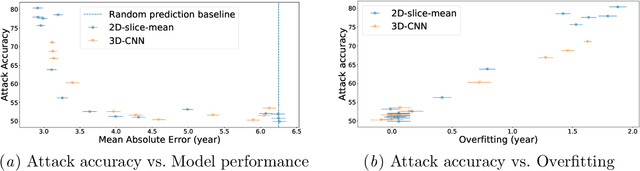
Ensuring the privacy of research participants is vital, even more so in healthcare environments. Deep learning approaches to neuroimaging require large datasets, and this often necessitates sharing data between multiple sites, which is antithetical to the privacy objectives. Federated learning is a commonly proposed solution to this problem. It circumvents the need for data sharing by sharing parameters during the training process. However, we demonstrate that allowing access to parameters may leak private information even if data is never directly shared. In particular, we show that it is possible to infer if a sample was used to train the model given only access to the model prediction (black-box) or access to the model itself (white-box) and some leaked samples from the training data distribution. Such attacks are commonly referred to as Membership Inference attacks. We show realistic Membership Inference attacks on deep learning models trained for 3D neuroimaging tasks in a centralized as well as decentralized setup. We demonstrate feasible attacks on brain age prediction models (deep learning models that predict a person's age from their brain MRI scan). We correctly identified whether an MRI scan was used in model training with a 60% to over 80% success rate depending on model complexity and security assumptions.
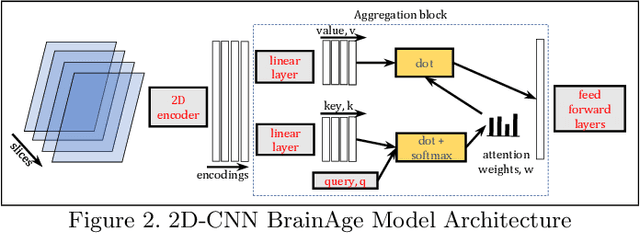
Improved Brain Age Estimation with Slice-based Set Networks
Feb 09, 2021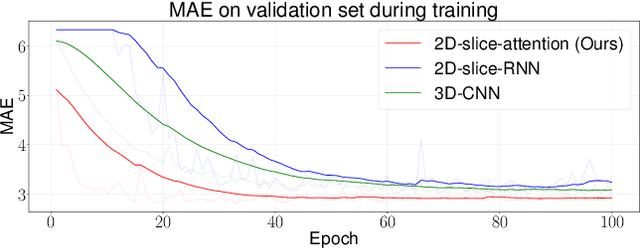

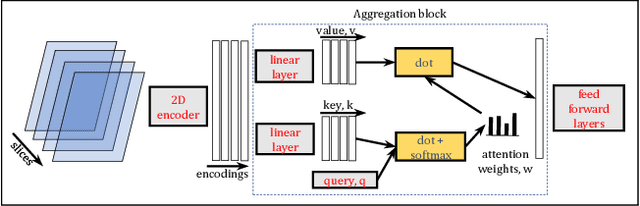
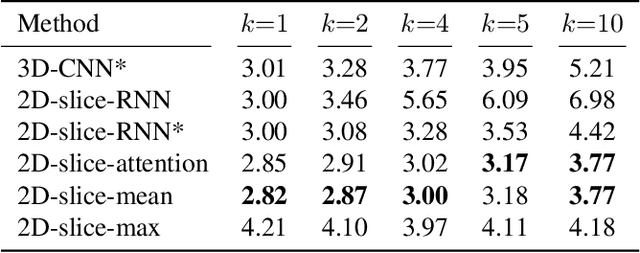
Deep Learning for neuroimaging data is a promising but challenging direction. The high dimensionality of 3D MRI scans makes this endeavor compute and data-intensive. Most conventional 3D neuroimaging methods use 3D-CNN-based architectures with a large number of parameters and require more time and data to train. Recently, 2D-slice-based models have received increasing attention as they have fewer parameters and may require fewer samples to achieve comparable performance. In this paper, we propose a new architecture for BrainAGE prediction. The proposed architecture works by encoding each 2D slice in an MRI with a deep 2D-CNN model. Next, it combines the information from these 2D-slice encodings using set networks or permutation invariant layers. Experiments on the BrainAGE prediction problem, using the UK Biobank dataset, showed that the model with the permutation invariant layers trains faster and provides better predictions compared to other state-of-the-art approaches.