 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling Customer Trajectories with Reinforcement Learning for Practical Retail Insights
May 18, 2026Understanding customer movement within retail spaces is essential for optimizing store layouts. Real-world trajectory data can provide highly accurate insights, but collecting it is costly and often infeasible for many retailers. Heuristics such as Travelling Salesman Problem (TSP) and Probabilistic Nearest Neighbours (PNN) are commonly used as inexpensive approximations, but actual customer trajectories deviate by an average of 28% from shortest paths, highlighting a tradeoff between accuracy and practicality. We propose an agent-based modelling framework that casts customer trajectory prediction as a maximum entropy reinforcement learning (RL) problem, balancing reward maximization with stochasticity to better reflect customers with bounded rationality. Using real-world trajectory data from a convenience store, we show that RL-generated trajectories align more closely with customer behaviour than TSP and PNN, providing more accurate estimates of impulse purchase rates and shelf traffic densities. Furthermore, only RL-based predictions yield repositioning decisions for impulse products that align with those derived from actual trajectory data, resulting in comparable estimated profit gains. Our work demonstrates that RL provides a practical, behaviourally grounded alternative that bridges the gap between oversimplified heuristics and data-intensive approaches, making accurate layout optimization more accessible. To encourage further research, the source code is available on GitHub.
Investigation of Independent Reinforcement Learning Algorithms in Multi-Agent Environments
Nov 01, 2021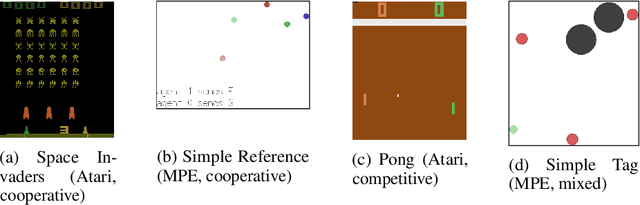

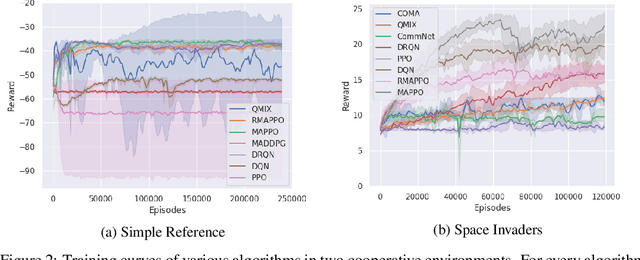
Independent reinforcement learning algorithms have no theoretical guarantees for finding the best policy in multi-agent settings. However, in practice, prior works have reported good performance with independent algorithms in some domains and bad performance in others. Moreover, a comprehensive study of the strengths and weaknesses of independent algorithms is lacking in the literature. In this paper, we carry out an empirical comparison of the performance of independent algorithms on four PettingZoo environments that span the three main categories of multi-agent environments, i.e., cooperative, competitive, and mixed. We show that in fully-observable environments, independent algorithms can perform on par with multi-agent algorithms in cooperative and competitive settings. For the mixed environments, we show that agents trained via independent algorithms learn to perform well individually, but fail to learn to cooperate with allies and compete with enemies. We also show that adding recurrence improves the learning of independent algorithms in cooperative partially observable environments.