 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubtleties in the trainability of quantum machine learning models
Oct 27, 2021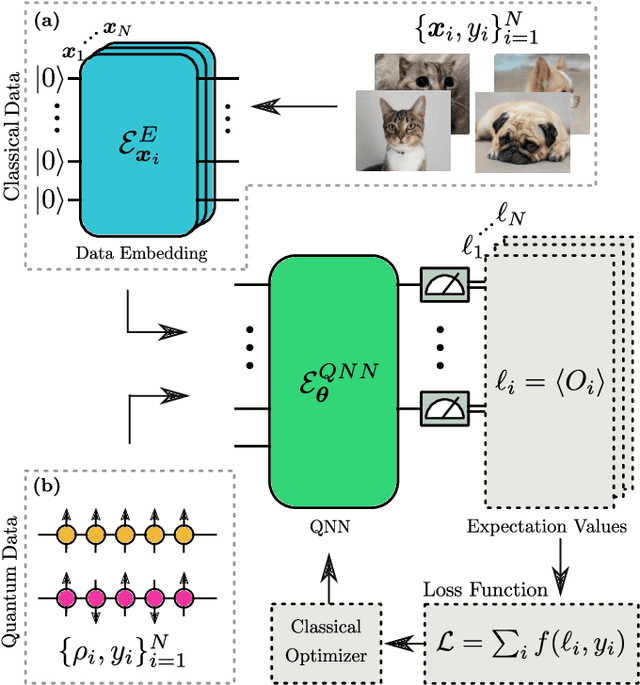
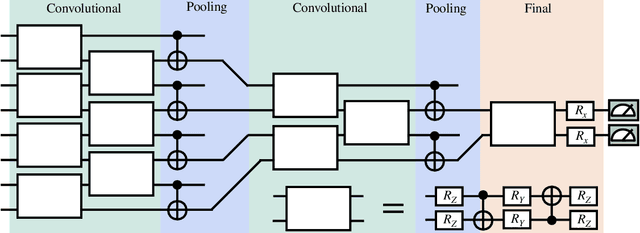
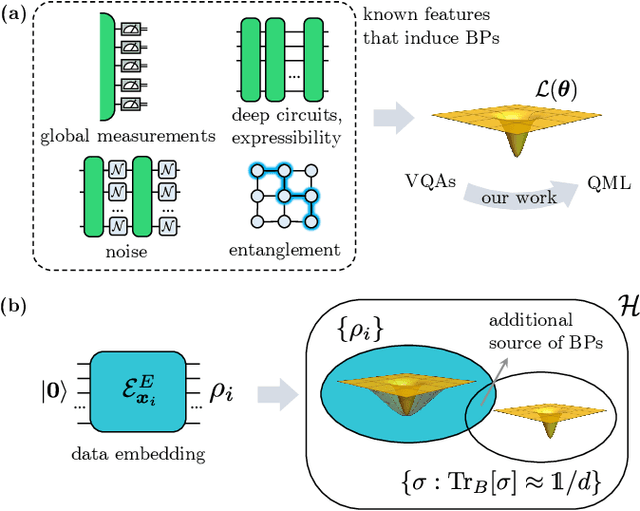
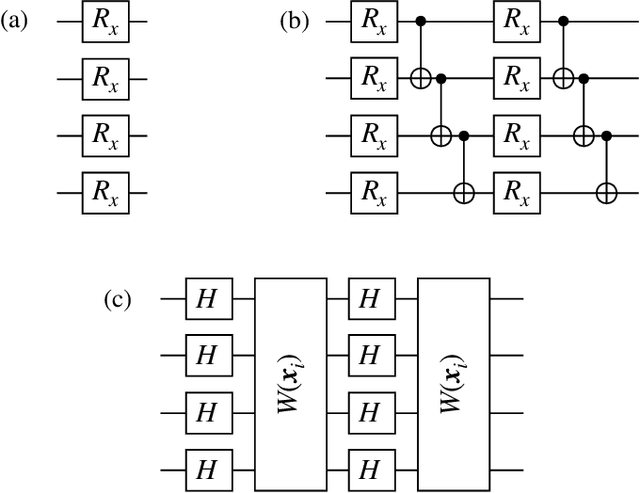
A new paradigm for data science has emerged, with quantum data, quantum models, and quantum computational devices. This field, called Quantum Machine Learning (QML), aims to achieve a speedup over traditional machine learning for data analysis. However, its success usually hinges on efficiently training the parameters in quantum neural networks, and the field of QML is still lacking theoretical scaling results for their trainability. Some trainability results have been proven for a closely related field called Variational Quantum Algorithms (VQAs). While both fields involve training a parametrized quantum circuit, there are crucial differences that make the results for one setting not readily applicable to the other. In this work we bridge the two frameworks and show that gradient scaling results for VQAs can also be applied to study the gradient scaling of QML models. Our results indicate that features deemed detrimental for VQA trainability can also lead to issues such as barren plateaus in QML. Consequently, our work has implications for several QML proposals in the literature. In addition, we provide theoretical and numerical evidence that QML models exhibit further trainability issues not present in VQAs, arising from the use of a training dataset. We refer to these as dataset-induced barren plateaus. These results are most relevant when dealing with classical data, as here the choice of embedding scheme (i.e., the map between classical data and quantum states) can greatly affect the gradient scaling.
Theory of overparametrization in quantum neural networks
Sep 23, 2021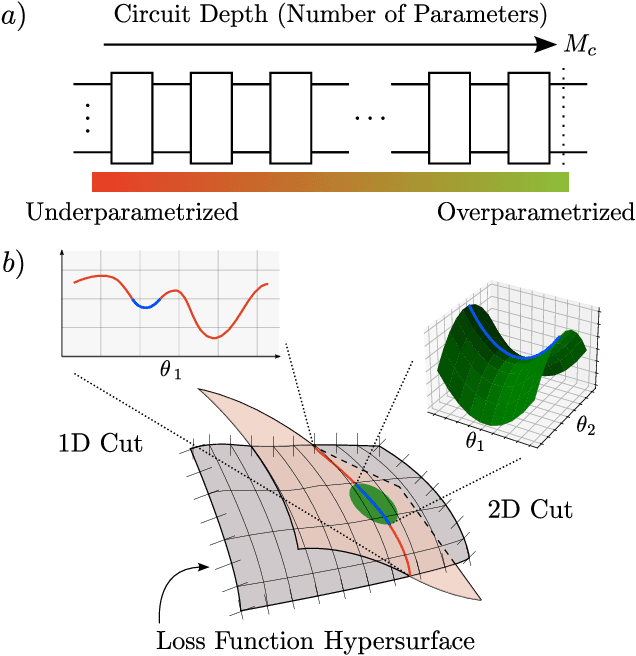
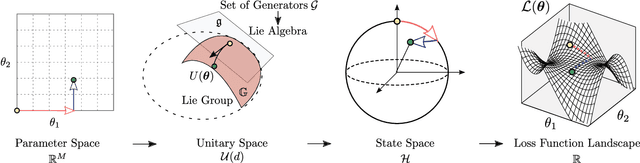
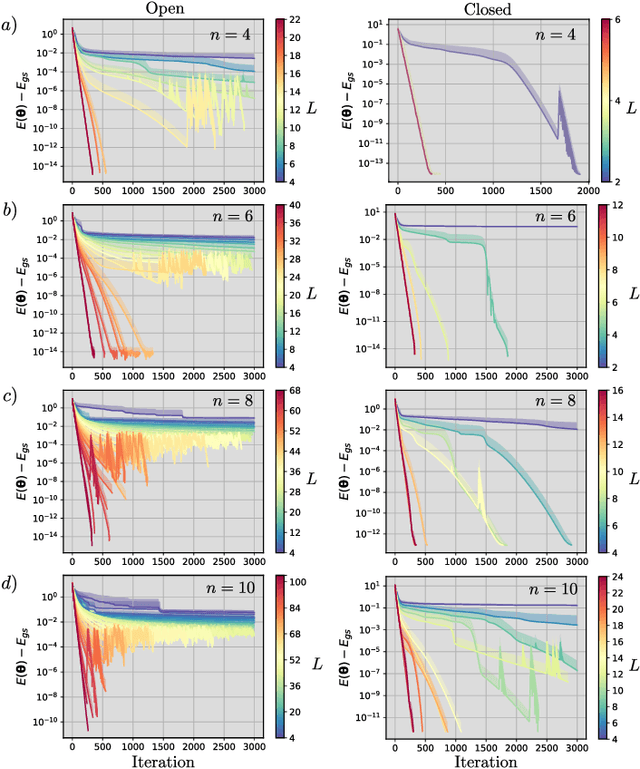
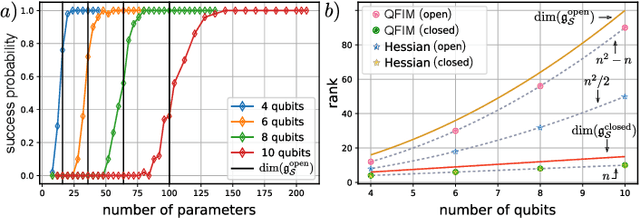
The prospect of achieving quantum advantage with Quantum Neural Networks (QNNs) is exciting. Understanding how QNN properties (e.g., the number of parameters $M$) affect the loss landscape is crucial to the design of scalable QNN architectures. Here, we rigorously analyze the overparametrization phenomenon in QNNs with periodic structure. We define overparametrization as the regime where the QNN has more than a critical number of parameters $M_c$ that allows it to explore all relevant directions in state space. Our main results show that the dimension of the Lie algebra obtained from the generators of the QNN is an upper bound for $M_c$, and for the maximal rank that the quantum Fisher information and Hessian matrices can reach. Underparametrized QNNs have spurious local minima in the loss landscape that start disappearing when $M\geq M_c$. Thus, the overparametrization onset corresponds to a computational phase transition where the QNN trainability is greatly improved by a more favorable landscape. We then connect the notion of overparametrization to the QNN capacity, so that when a QNN is overparametrized, its capacity achieves its maximum possible value. We run numerical simulations for eigensolver, compilation, and autoencoding applications to showcase the overparametrization computational phase transition. We note that our results also apply to variational quantum algorithms and quantum optimal control.
Entangled Datasets for Quantum Machine Learning
Sep 08, 2021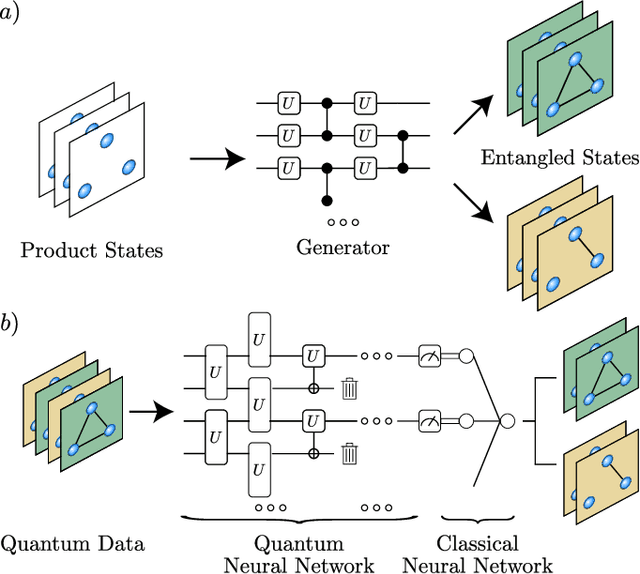
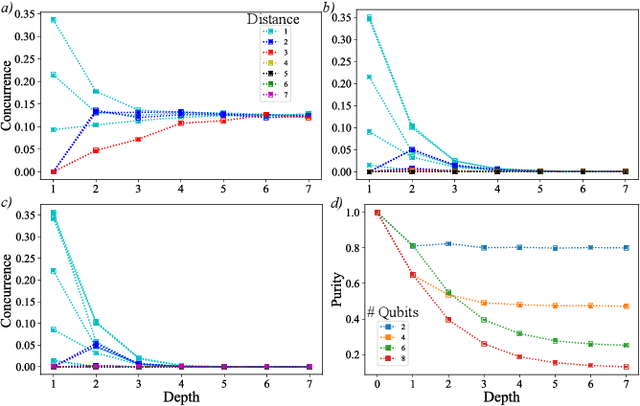

High-quality, large-scale datasets have played a crucial role in the development and success of classical machine learning. Quantum Machine Learning (QML) is a new field that aims to use quantum computers for data analysis, with the hope of obtaining a quantum advantage of some sort. While most proposed QML architectures are benchmarked using classical datasets, there is still doubt whether QML on classical datasets will achieve such an advantage. In this work, we argue that one should instead employ quantum datasets composed of quantum states. For this purpose, we introduce the NTangled dataset composed of quantum states with different amounts and types of multipartite entanglement. We first show how a quantum neural network can be trained to generate the states in the NTangled dataset. Then, we use the NTangled dataset to benchmark QML models for supervised learning classification tasks. We also consider an alternative entanglement-based dataset, which is scalable and is composed of states prepared by quantum circuits with different depths. As a byproduct of our results, we introduce a novel method for generating multipartite entangled states, providing a use-case of quantum neural networks for quantum entanglement theory.
Can Error Mitigation Improve Trainability of Noisy Variational Quantum Algorithms?
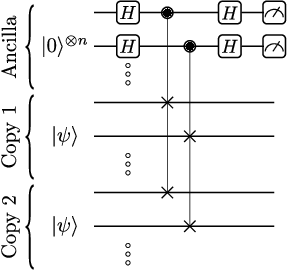
Sep 02, 2021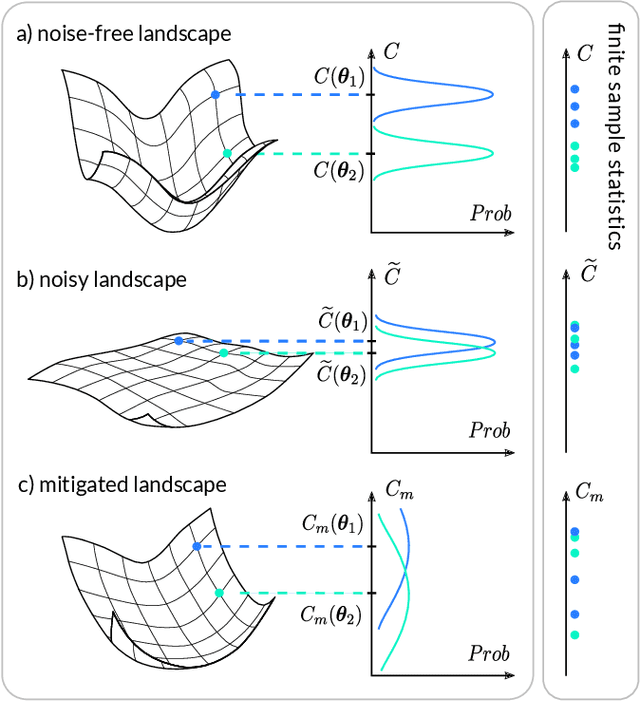
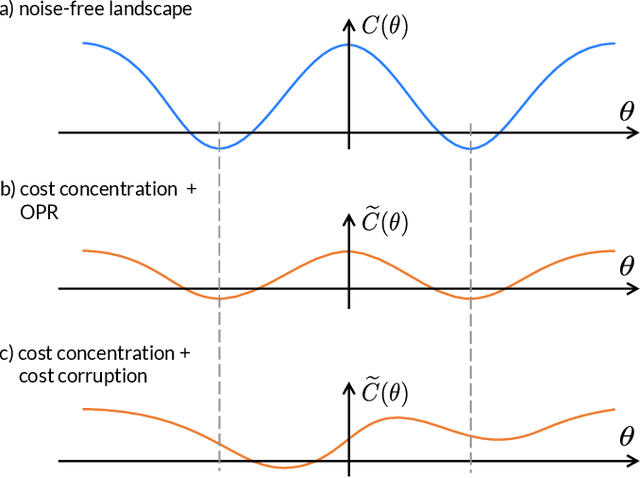
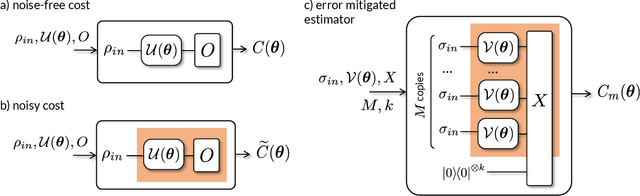
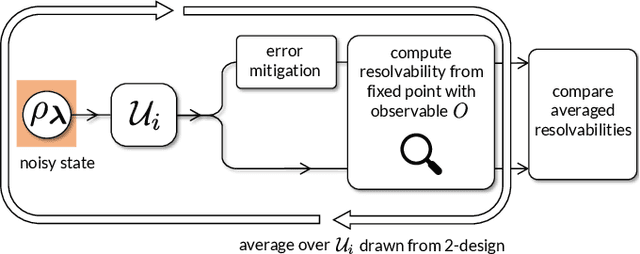
Variational Quantum Algorithms (VQAs) are widely viewed as the best hope for near-term quantum advantage. However, recent studies have shown that noise can severely limit the trainability of VQAs, e.g., by exponentially flattening the cost landscape and suppressing the magnitudes of cost gradients. Error Mitigation (EM) shows promise in reducing the impact of noise on near-term devices. Thus, it is natural to ask whether EM can improve the trainability of VQAs. In this work, we first show that, for a broad class of EM strategies, exponential cost concentration cannot be resolved without committing exponential resources elsewhere. This class of strategies includes as special cases Zero Noise Extrapolation, Virtual Distillation, Probabilistic Error Cancellation, and Clifford Data Regression. Second, we perform analytical and numerical analysis of these EM protocols, and we find that some of them (e.g., Virtual Distillation) can make it harder to resolve cost function values compared to running no EM at all. As a positive result, we do find numerical evidence that Clifford Data Regression (CDR) can aid the training process in certain settings where cost concentration is not too severe. Our results show that care should be taken in applying EM protocols as they can either worsen or not improve trainability. On the other hand, our positive results for CDR highlight the possibility of engineering error mitigation methods to improve trainability.
Adaptive shot allocation for fast convergence in variational quantum algorithms
Aug 23, 2021
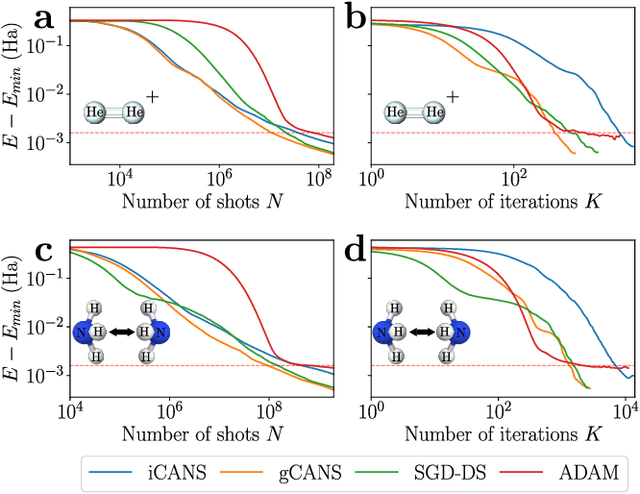
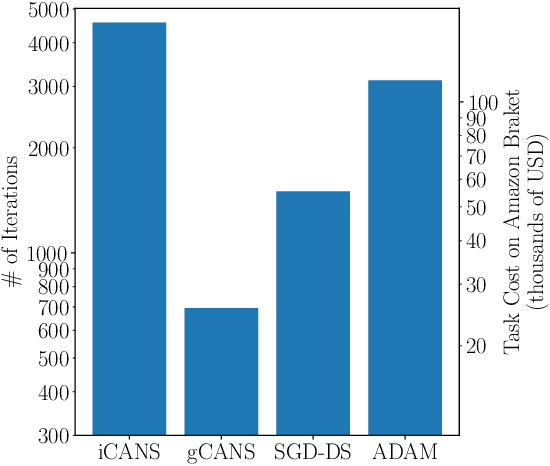
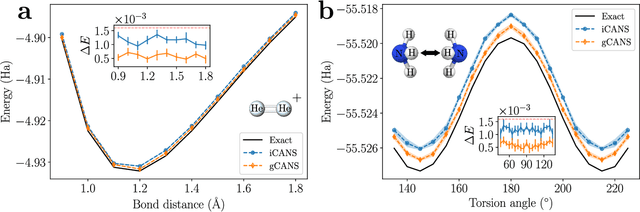
Variational Quantum Algorithms (VQAs) are a promising approach for practical applications like chemistry and materials science on near-term quantum computers as they typically reduce quantum resource requirements. However, in order to implement VQAs, an efficient classical optimization strategy is required. Here we present a new stochastic gradient descent method using an adaptive number of shots at each step, called the global Coupled Adaptive Number of Shots (gCANS) method, which improves on prior art in both the number of iterations as well as the number of shots required. These improvements reduce both the time and money required to run VQAs on current cloud platforms. We analytically prove that in a convex setting gCANS achieves geometric convergence to the optimum. Further, we numerically investigate the performance of gCANS on some chemical configuration problems. We also consider finding the ground state for an Ising model with different numbers of spins to examine the scaling of the method. We find that for these problems, gCANS compares favorably to all of the other optimizers we consider.
Equivalence of quantum barren plateaus to cost concentration and narrow gorges
Apr 12, 2021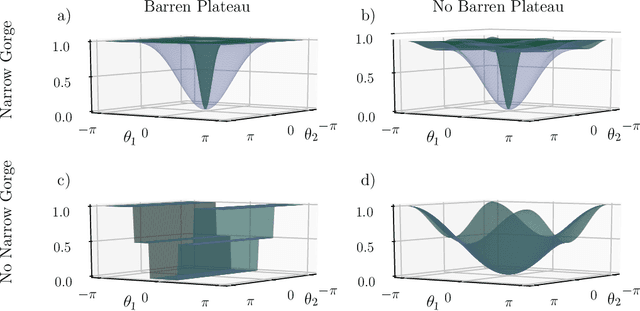
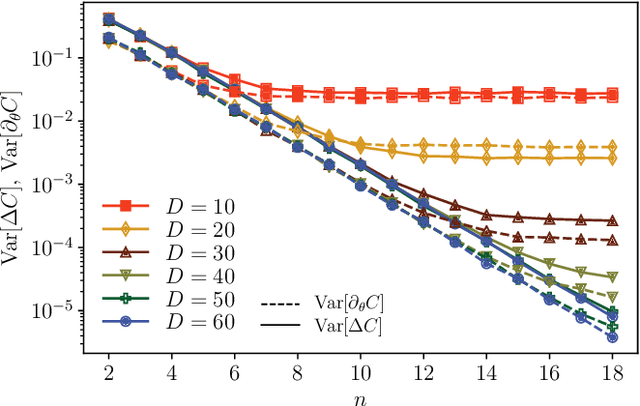
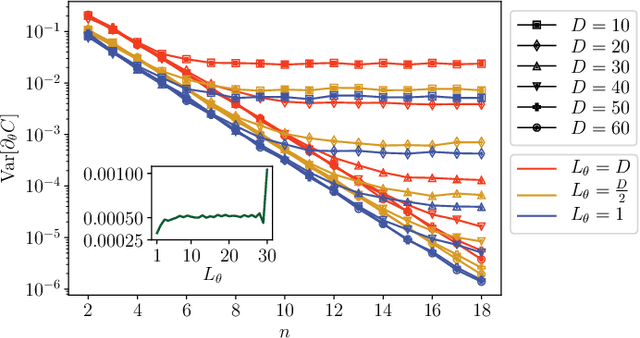
Optimizing parameterized quantum circuits (PQCs) is the leading approach to make use of near-term quantum computers. However, very little is known about the cost function landscape for PQCs, which hinders progress towards quantum-aware optimizers. In this work, we investigate the connection between three different landscape features that have been observed for PQCs: (1) exponentially vanishing gradients (called barren plateaus), (2) exponential cost concentration about the mean, and (3) the exponential narrowness of minina (called narrow gorges). We analytically prove that these three phenomena occur together, i.e., when one occurs then so do the other two. A key implication of this result is that one can numerically diagnose barren plateaus via cost differences rather than via the computationally more expensive gradients. More broadly, our work shows that quantum mechanics rules out certain cost landscapes (which otherwise would be mathematically possible), and hence our results are interesting from a quantum foundations perspective.
A semi-agnostic ansatz with variable structure for quantum machine learning
Mar 11, 2021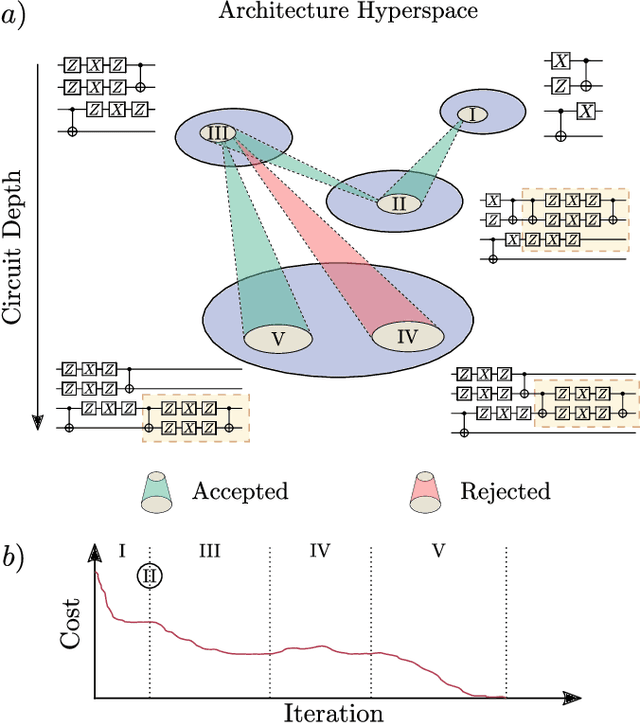
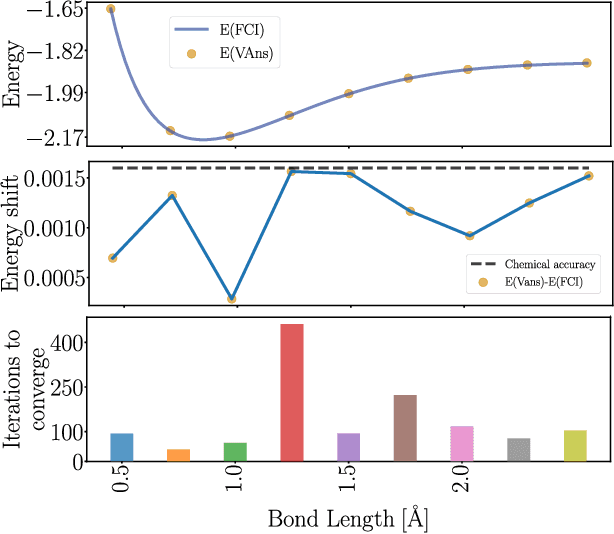
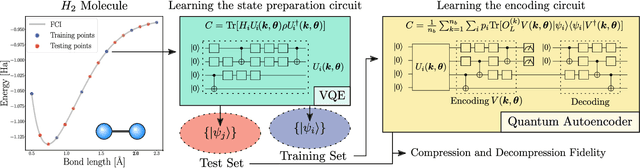
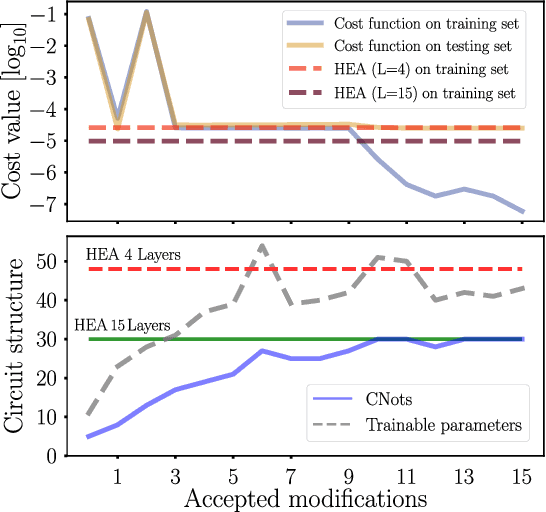
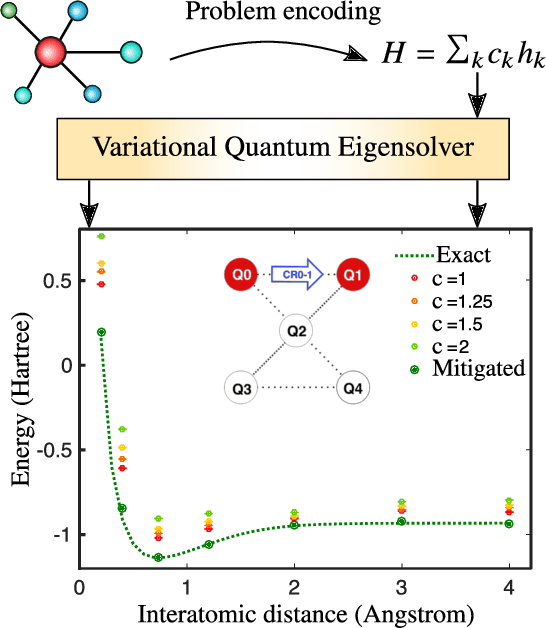
Quantum machine learning (QML) offers a powerful, flexible paradigm for programming near-term quantum computers, with applications in chemistry, metrology, materials science, data science, and mathematics. Here, one trains an ansatz, in the form of a parameterized quantum circuit, to accomplish a task of interest. However, challenges have recently emerged suggesting that deep ansatzes are difficult to train, due to flat training landscapes caused by randomness or by hardware noise. This motivates our work, where we present a variable structure approach to build ansatzes for QML. Our approach, called VAns (Variable Ansatz), applies a set of rules to both grow and (crucially) remove quantum gates in an informed manner during the optimization. Consequently, VAns is ideally suited to mitigate trainability and noise-related issues by keeping the ansatz shallow. We employ VAns in the variational quantum eigensolver for condensed matter and quantum chemistry applications and also in the quantum autoencoder for data compression, showing successful results in all cases.
Long-time simulations with high fidelity on quantum hardware
Feb 08, 2021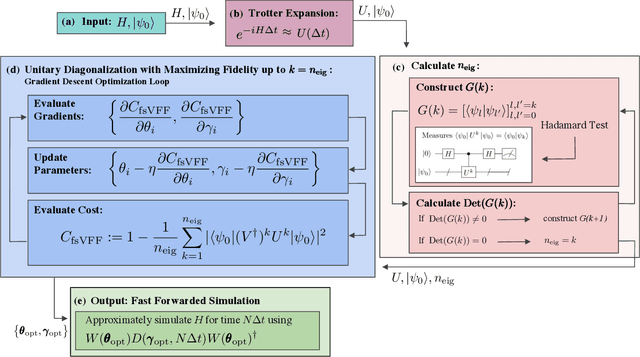
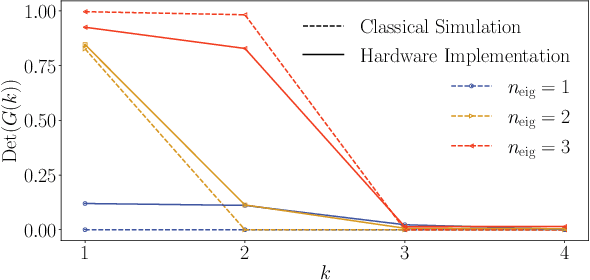

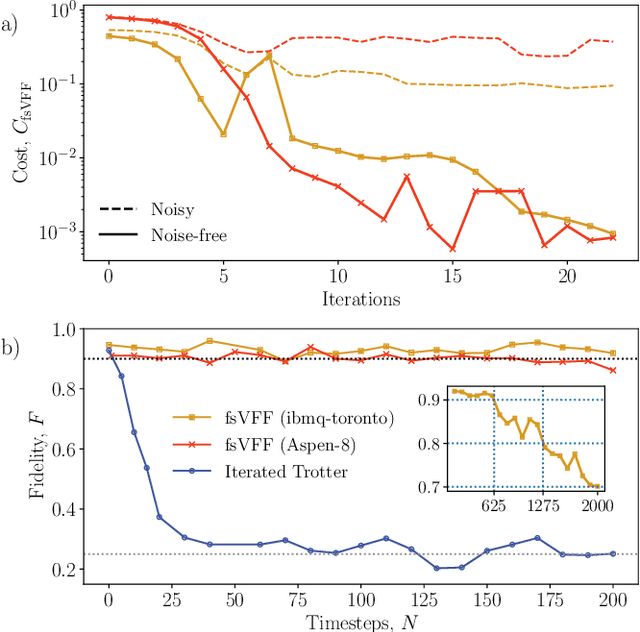
Moderate-size quantum computers are now publicly accessible over the cloud, opening the exciting possibility of performing dynamical simulations of quantum systems. However, while rapidly improving, these devices have short coherence times, limiting the depth of algorithms that may be successfully implemented. Here we demonstrate that, despite these limitations, it is possible to implement long-time, high fidelity simulations on current hardware. Specifically, we simulate an XY-model spin chain on the Rigetti and IBM quantum computers, maintaining a fidelity of at least 0.9 for over 600 time steps. This is a factor of 150 longer than is possible using the iterated Trotter method. Our simulations are performed using a new algorithm that we call the fixed state Variational Fast Forwarding (fsVFF) algorithm. This algorithm decreases the circuit depth and width required for a quantum simulation by finding an approximate diagonalization of a short time evolution unitary. Crucially, fsVFF only requires finding a diagonalization on the subspace spanned by the initial state, rather than on the total Hilbert space as with previous methods, substantially reducing the required resources.
Connecting ansatz expressibility to gradient magnitudes and barren plateaus
Jan 06, 2021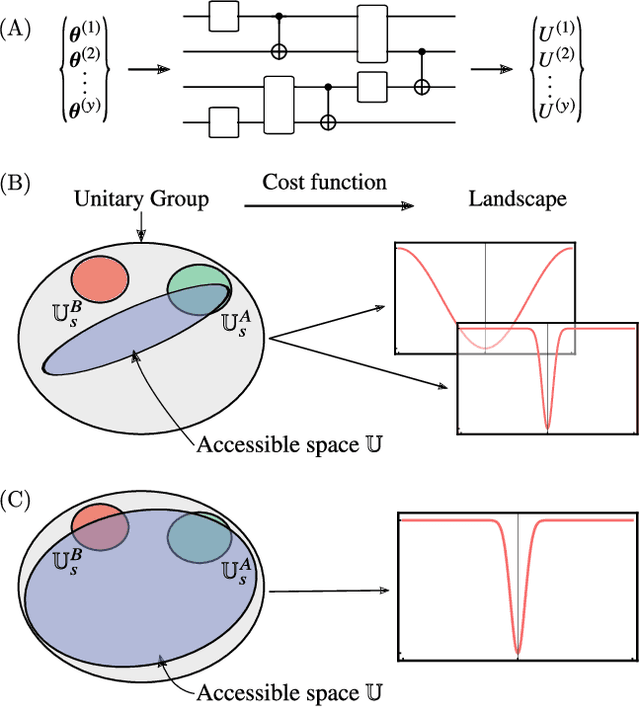
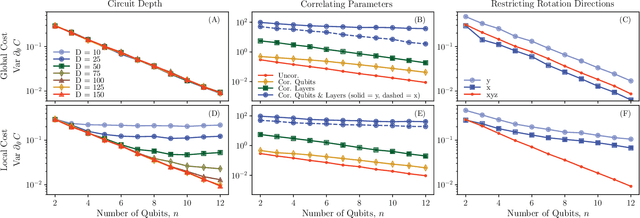
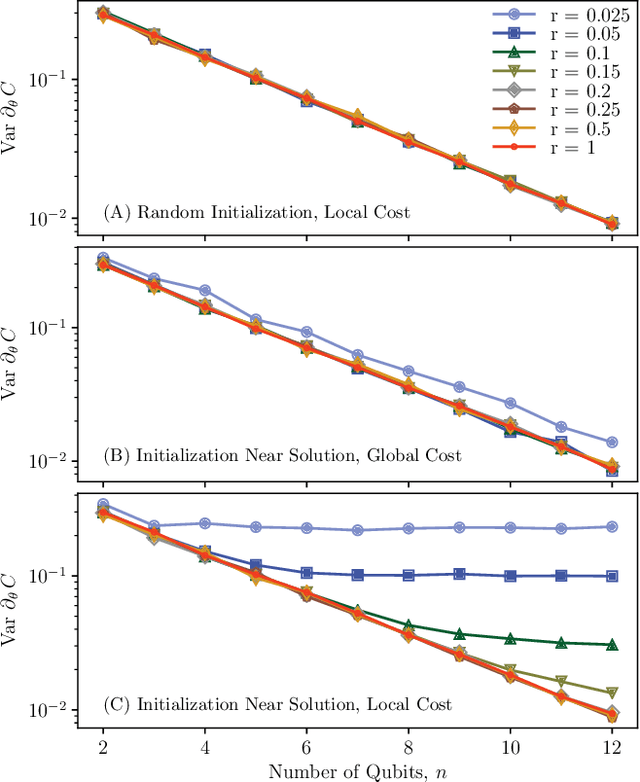
Parameterized quantum circuits serve as ans\"{a}tze for solving variational problems and provide a flexible paradigm for programming near-term quantum computers. Ideally, such ans\"{a}tze should be highly expressive so that a close approximation of the desired solution can be accessed. On the other hand, the ansatz must also have sufficiently large gradients to allow for training. Here, we derive a fundamental relationship between these two essential properties: expressibility and trainability. This is done by extending the well established barren plateau phenomenon, which holds for ans\"{a}tze that form exact 2-designs, to arbitrary ans\"{a}tze. Specifically, we calculate the variance in the cost gradient in terms of the expressibility of the ansatz, as measured by its distance from being a 2-design. Our resulting bounds indicate that highly expressive ans\"{a}tze exhibit flatter cost landscapes and therefore will be harder to train. Furthermore, we provide numerics illustrating the effect of expressiblity on gradient scalings, and we discuss the implications for designing strategies to avoid barren plateaus.
Variational Quantum Algorithms
Dec 16, 2020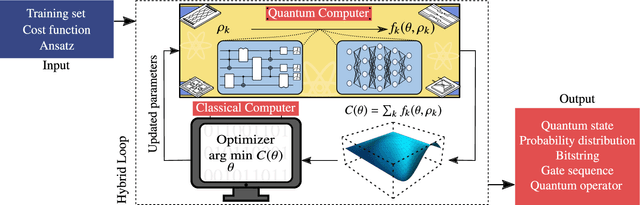
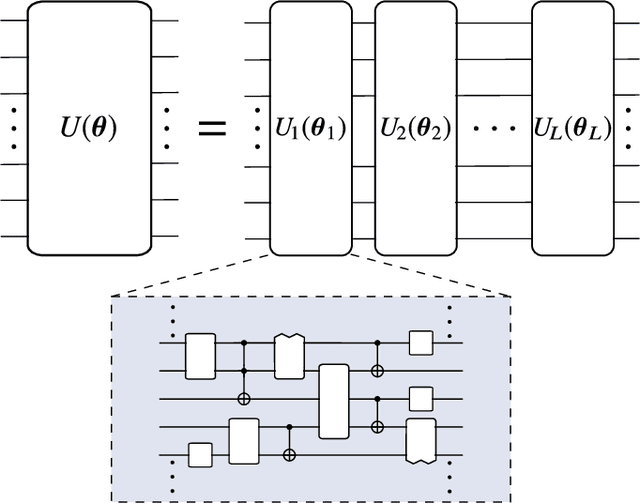
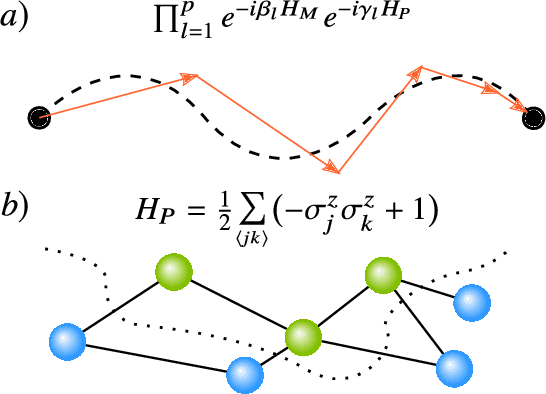
Applications such as simulating large quantum systems or solving large-scale linear algebra problems are immensely challenging for classical computers due their extremely high computational cost. Quantum computers promise to unlock these applications, although fault-tolerant quantum computers will likely not be available for several years. Currently available quantum devices have serious constraints, including limited qubit numbers and noise processes that limit circuit depth. Variational Quantum Algorithms (VQAs), which employ a classical optimizer to train a parametrized quantum circuit, have emerged as a leading strategy to address these constraints. VQAs have now been proposed for essentially all applications that researchers have envisioned for quantum computers, and they appear to the best hope for obtaining quantum advantage. Nevertheless, challenges remain including the trainability, accuracy, and efficiency of VQAs. In this review article we present an overview of the field of VQAs. Furthermore, we discuss strategies to overcome their challenges as well as the exciting prospects for using them as a means to obtain quantum advantage.