 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoGraph: Capturing Emotion Correlations using Graph Networks
Aug 21, 2020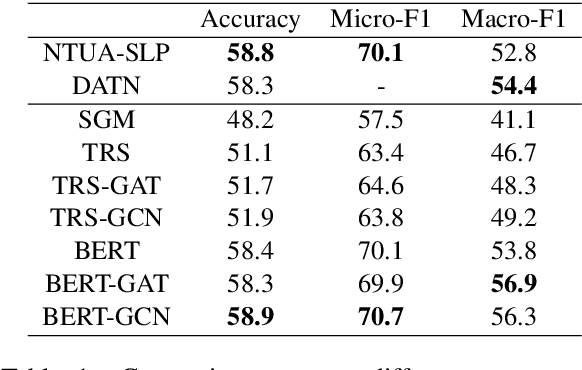
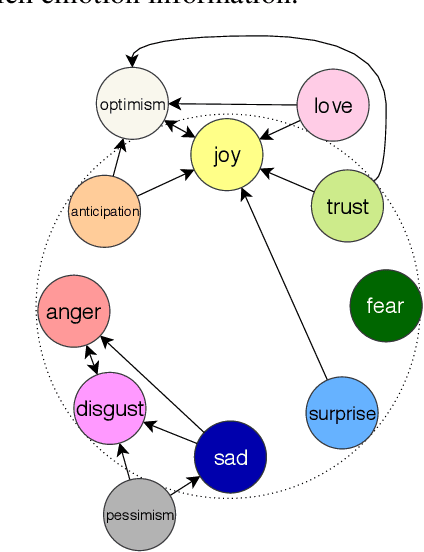
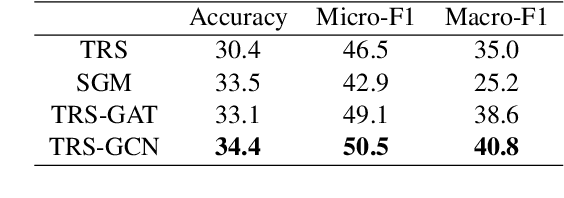
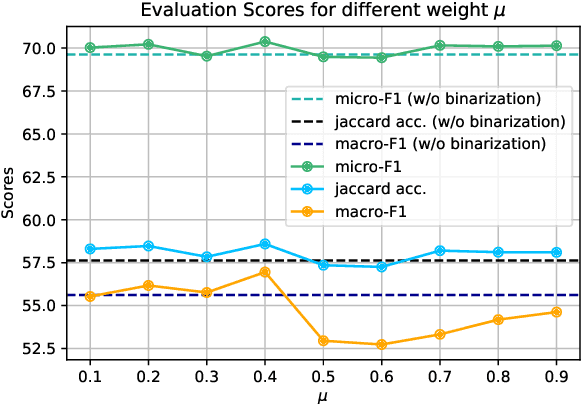
Most emotion recognition methods tackle the emotion understanding task by considering individual emotion independently while ignoring their fuzziness nature and the interconnections among them. In this paper, we explore how emotion correlations can be captured and help different classification tasks. We propose EmoGraph that captures the dependencies among different emotions through graph networks. These graphs are constructed by leveraging the co-occurrence statistics among different emotion categories. Empirical results on two multi-label classification datasets demonstrate that EmoGraph outperforms strong baselines, especially for macro-F1. An additional experiment illustrates the captured emotion correlations can also benefit a single-label classification task.
Language Models as Few-Shot Learner for Task-Oriented Dialogue Systems
Aug 20, 2020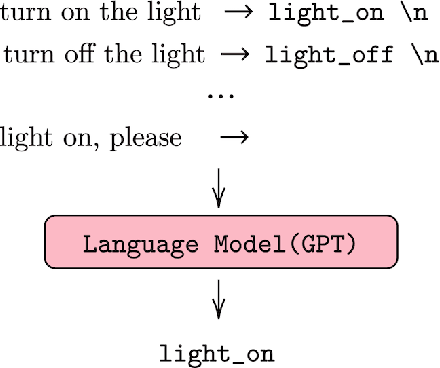
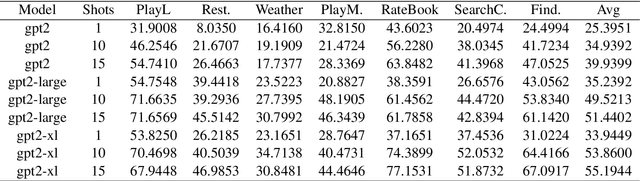
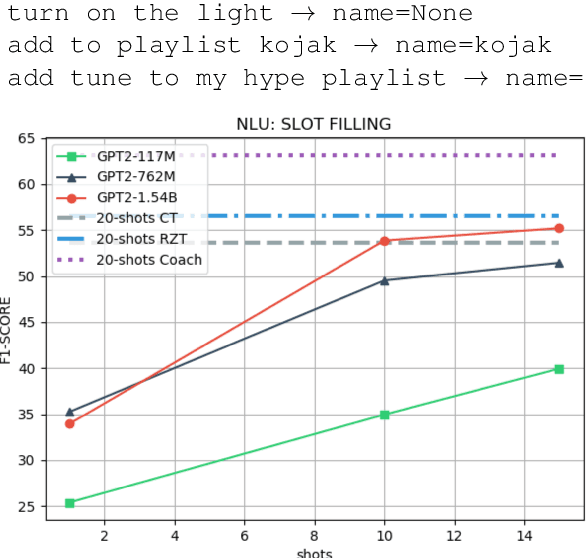
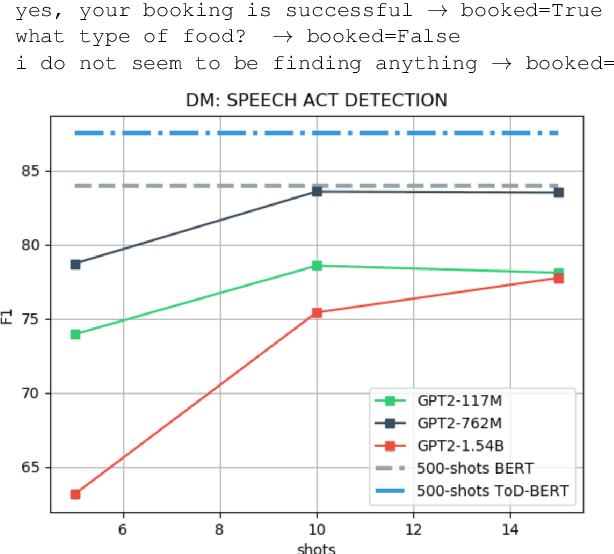
Task-oriented dialogue systems use four connected modules, namely, Natural Language Understanding (NLU), a Dialogue State Tracking (DST), Dialogue Policy (DP) and Natural Language Generation (NLG). A research challenge is to learn each module with the least amount of samples (i.e., few-shots) given the high cost related to the data collection. The most common and effective technique to solve this problem is transfer learning, where large language models, either pre-trained on text or task-specific data, are fine-tuned on the few samples. These methods require fine-tuning steps and a set of parameters for each task. Differently, language models, such as GPT-2 (Radford et al., 2019) and GPT-3 (Brown et al., 2020), allow few-shot learning by priming the model with few examples. In this paper, we evaluate the priming few-shot ability of language models in the NLU, DST, DP and NLG tasks. Importantly, we highlight the current limitations of this approach, and we discuss the possible implication for future work.
Misinformation Has High Perplexity
Jun 10, 2020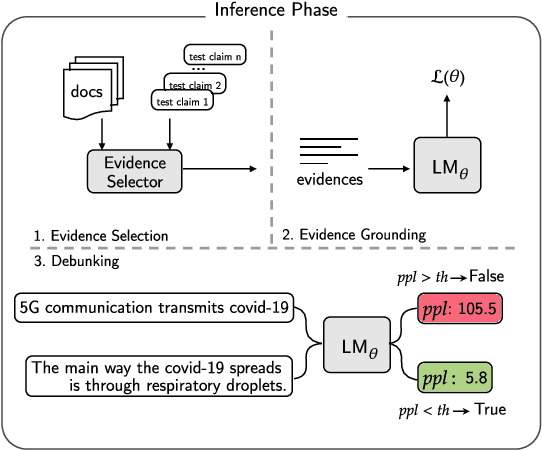


Debunking misinformation is an important and time-critical task as there could be adverse consequences when misinformation is not quashed promptly. However, the usual supervised approach to debunking via misinformation classification requires human-annotated data and is not suited to the fast time-frame of newly emerging events such as the COVID-19 outbreak. In this paper, we postulate that misinformation itself has higher perplexity compared to truthful statements, and propose to leverage the perplexity to debunk false claims in an unsupervised manner. First, we extract reliable evidence from scientific and news sources according to sentence similarity to the claims. Second, we prime a language model with the extracted evidence and finally evaluate the correctness of given claims based on the perplexity scores at debunking time. We construct two new COVID-19-related test sets, one is scientific, and another is political in content, and empirically verify that our system performs favorably compared to existing systems. We are releasing these datasets publicly to encourage more research in debunking misinformation on COVID-19 and other topics.
CAiRE-COVID: A Question Answering and Multi-Document Summarization System for COVID-19 Research
May 04, 2020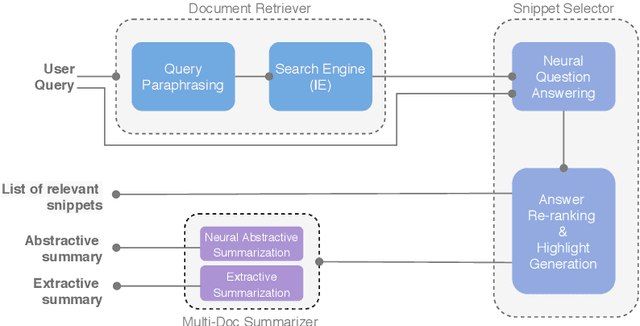
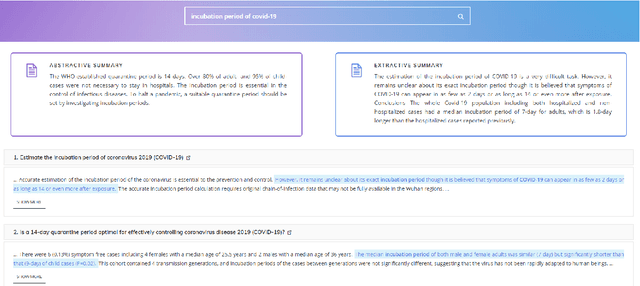
To address the need for refined information in COVID-19 pandemic, we propose a deep learning-based system that uses state-of-the-art natural language processing (NLP) question answering (QA) techniques combined with summarization for mining the available scientific literature. Our system leverages the Information Retrieval (IR) system and QA models to extract relevant snippets from the existing literature given a query. Fluent summaries are also provided to help understand the content in a more efficient way. In this paper, we describe our CAiRE-COVID system architecture and methodology for building the system. To bootstrap the further study, the code for our system is available at https://github.com/HLTCHKUST/CAiRE-COVID
Meta-Transfer Learning for Code-Switched Speech Recognition
Apr 29, 2020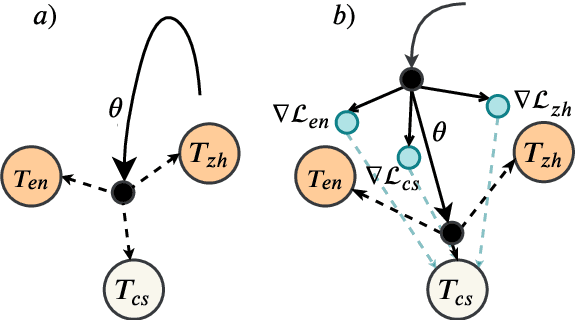
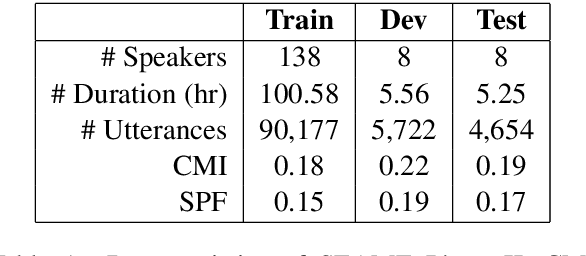
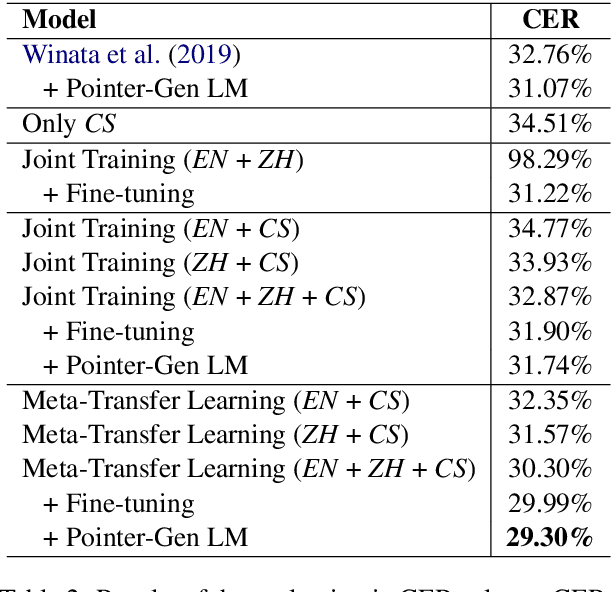
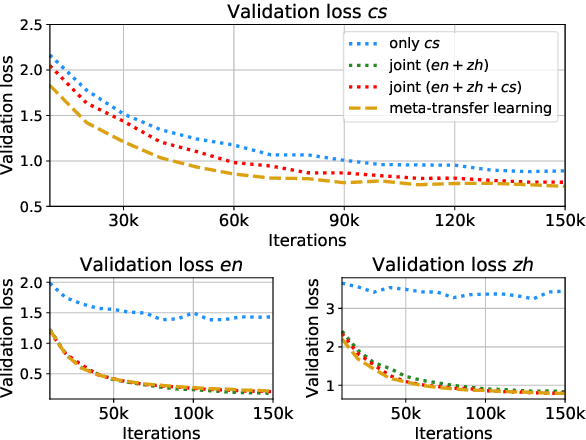
An increasing number of people in the world today speak a mixed-language as a result of being multilingual. However, building a speech recognition system for code-switching remains difficult due to the availability of limited resources and the expense and significant effort required to collect mixed-language data. We therefore propose a new learning method, meta-transfer learning, to transfer learn on a code-switched speech recognition system in a low-resource setting by judiciously extracting information from high-resource monolingual datasets. Our model learns to recognize individual languages, and transfer them so as to better recognize mixed-language speech by conditioning the optimization on the code-switching data. Based on experimental results, our model outperforms existing baselines on speech recognition and language modeling tasks, and is faster to converge.
Exploring Fine-tuning Techniques for Pre-trained Cross-lingual Models via Continual Learning
Apr 29, 2020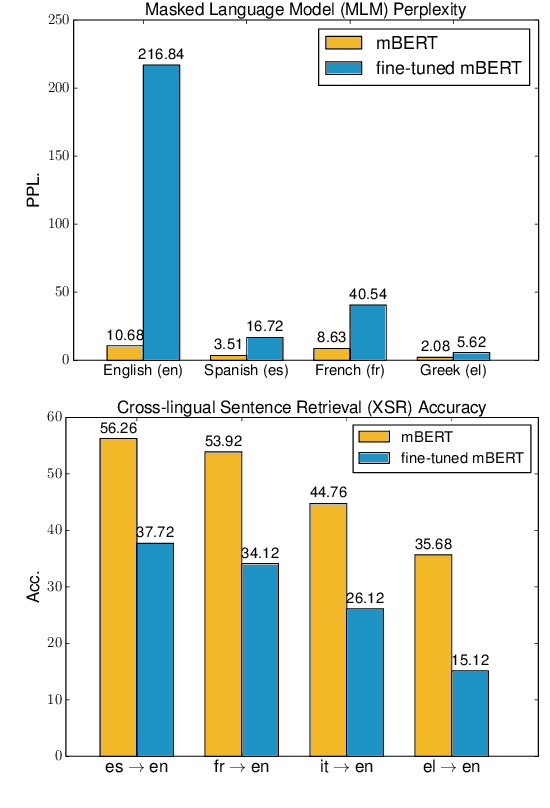
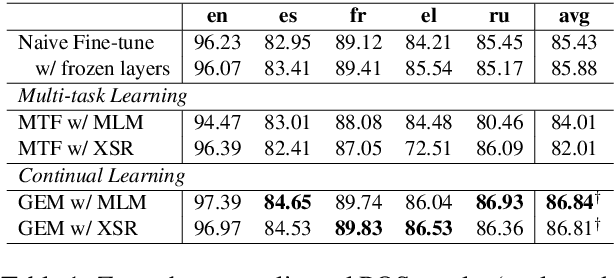
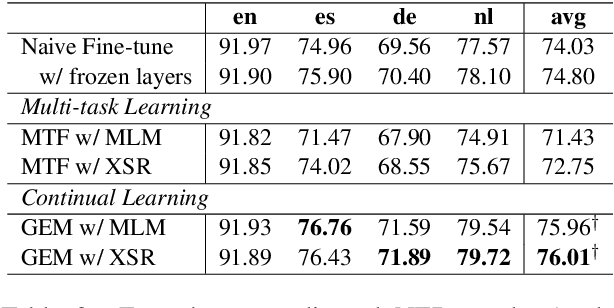
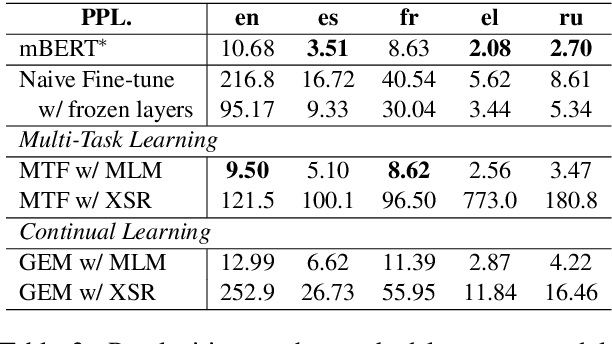
Recently, fine-tuning pre-trained cross-lingual models (e.g., multilingual BERT) to downstream cross-lingual tasks has shown promising results. However, the fine-tuning process inevitably changes the parameters of the pre-trained model and weakens its cross-lingual ability, which could lead to sub-optimal performances. To alleviate this issue, we leverage the idea of continual learning to preserve the original cross-lingual ability of the pre-trained model when we fine-tune it to downstream cross-lingual tasks. The experiment on the cross-lingual sentence retrieval task shows that our fine-tuning approach can better preserve the cross-lingual ability of the pre-trained model. In addition, our method achieves better performance than other fine-tuning baselines on zero-shot cross-lingual part-of-speech tagging and named entity recognition tasks.
Kungfupanda at SemEval-2020 Task 12: BERT-Based Multi-Task Learning for Offensive Language Detection
Apr 28, 2020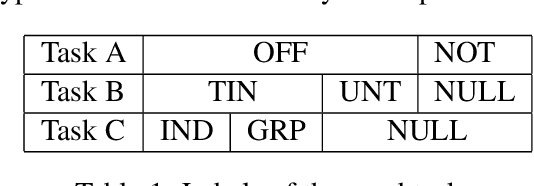
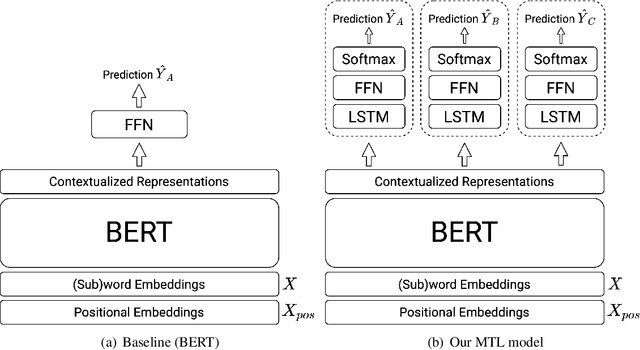
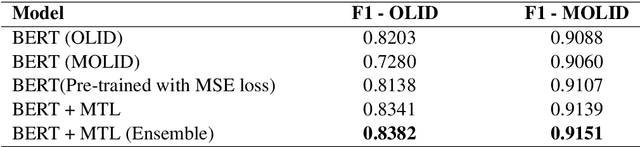
Nowadays, offensive content in social media has become a serious problem, and automatically detecting offensive language is an essential task. In this paper, we build an offensive language detection system, which combines multi-task learning with BERT-based models. Using a pre-trained language model such as BERT, we can effectively learn the representations for noisy text in social media. Besides, to boost the performance of offensive language detection, we leverage the supervision signals from other related tasks. In the OffensEval-2020 competition, our model achieves 91.51% F1 score in English Sub-task A, which is comparable to the first place (92.23%F1). An empirical analysis is provided to explain the effectiveness of our approaches.
Coach: A Coarse-to-Fine Approach for Cross-domain Slot Filling
Apr 24, 2020
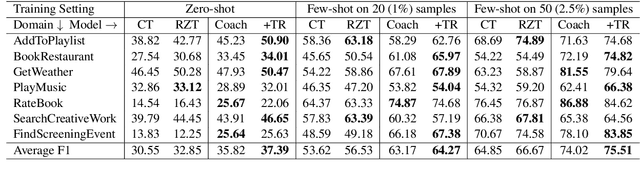
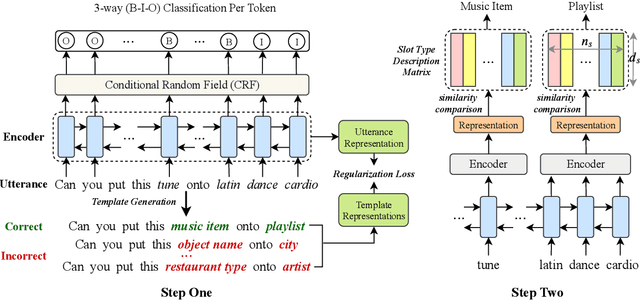
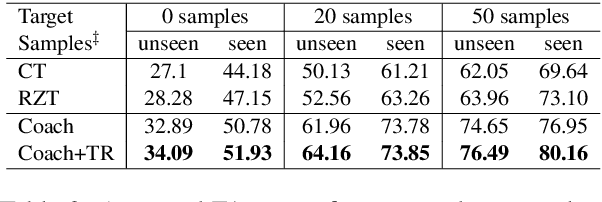
As an essential task in task-oriented dialog systems, slot filling requires extensive training data in a certain domain. However, such data are not always available. Hence, cross-domain slot filling has naturally arisen to cope with this data scarcity problem. In this paper, we propose a Coarse-to-fine approach (Coach) for cross-domain slot filling. Our model first learns the general pattern of slot entities by detecting whether the tokens are slot entities or not. It then predicts the specific types for the slot entities. In addition, we propose a template regularization approach to improve the adaptation robustness by regularizing the representation of utterances based on utterance templates. Experimental results show that our model significantly outperforms state-of-the-art approaches in slot filling. Furthermore, our model can also be applied to the cross-domain named entity recognition task, and it achieves better adaptation performance than other existing baselines. The code is available at https://github.com/zliucr/coach.
XPersona: Evaluating Multilingual Personalized Chatbot
Apr 08, 2020
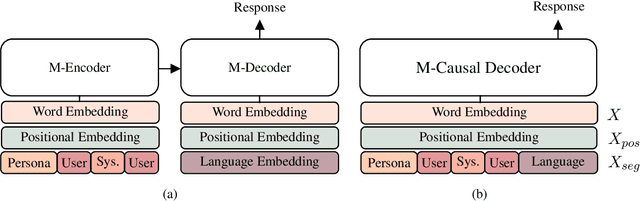
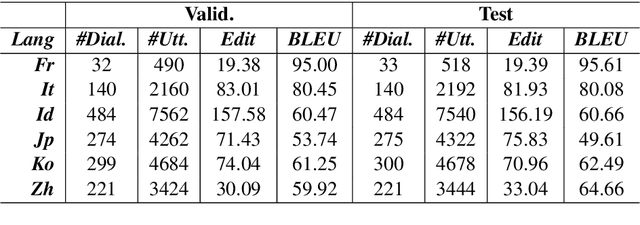
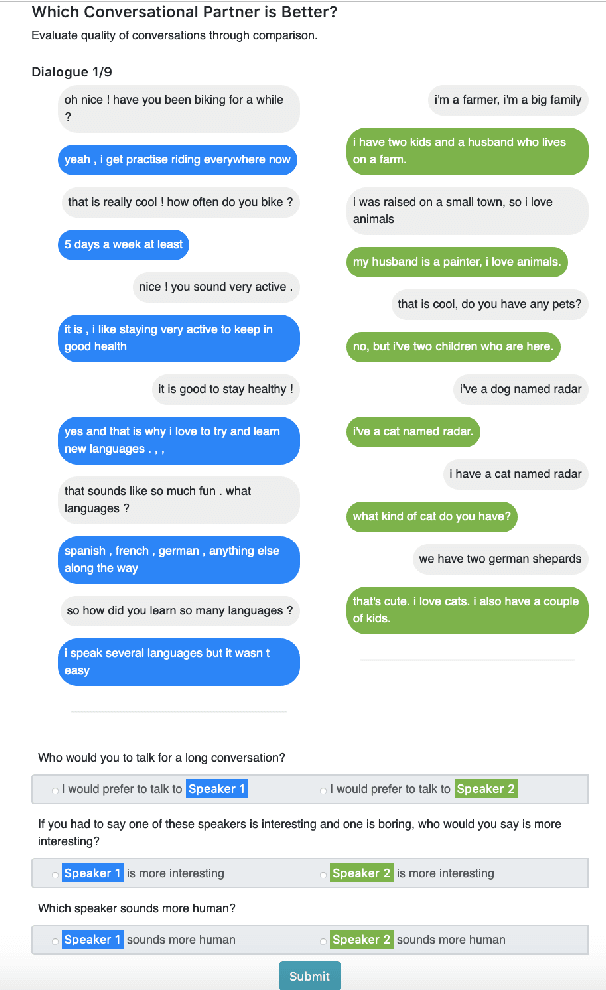
Personalized dialogue systems are an essential step toward better human-machine interaction. Existing personalized dialogue agents rely on properly designed conversational datasets, which are mostly monolingual (e.g., English), which greatly limits the usage of conversational agents in other languages. In this paper, we propose a multi-lingual extension of Persona-Chat, namely XPersona. Our dataset includes persona conversations in six different languages other than English for building and evaluating multilingual personalized agents. We experiment with both multilingual and cross-lingual trained baselines, and evaluate them against monolingual and translation-pipeline models using both automatic and human evaluation. Experimental results show that the multilingual trained models outperform the translation-pipeline and that they are on par with the monolingual models, with the advantage of having a single model across multiple languages. On the other hand, the state-of-the-art cross-lingual trained models achieve inferior performance to the other models, showing that cross-lingual conversation modeling is a challenging task. We hope that our dataset and baselines will accelerate research in multilingual dialogue systems.
Exploring Versatile Generative Language Model Via Parameter-Efficient Transfer Learning
Apr 08, 2020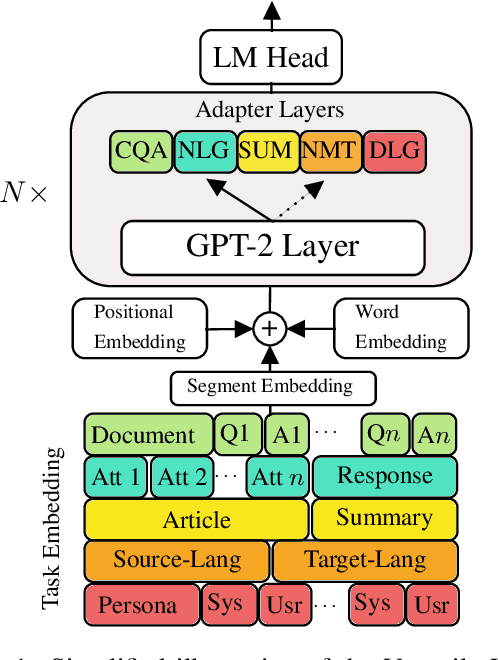
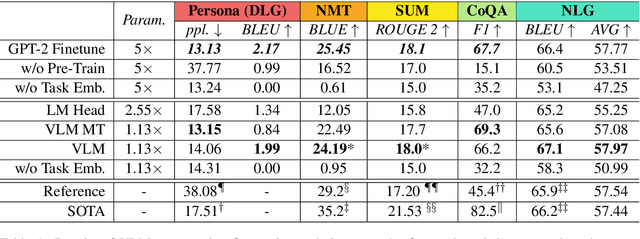
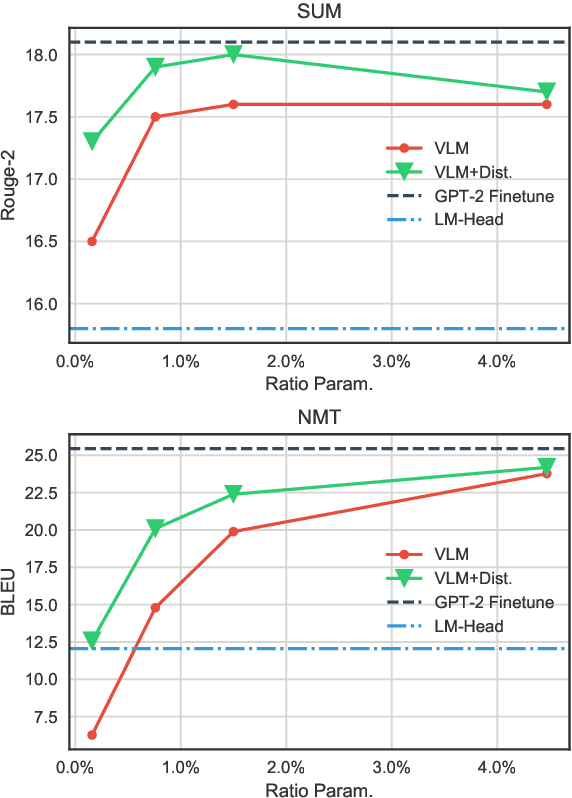
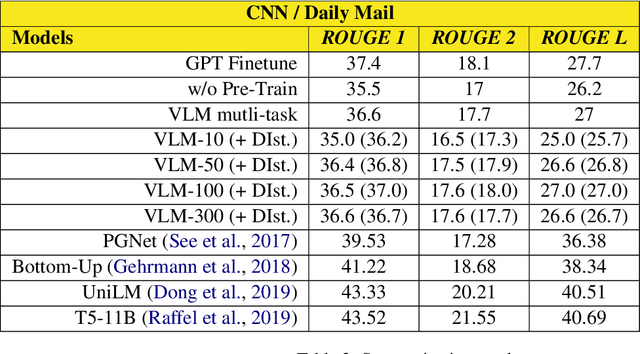
Fine-tuning pre-trained generative language models to down-stream language generation tasks has shown promising results. However, this comes with the cost of having a single, large model for each task, which is not ideal in low-memory/power scenarios (e.g., mobile). In this paper, we propose an effective way to fine-tune multiple down-stream generation tasks simultaneously using a single, large pre-trained model. The experiments on five diverse language generation tasks show that by just using an additional 2-3% parameters for each task, our model can maintain or even improve the performance of fine-tuning the whole model.