 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChanges in Commuter Behavior from COVID-19 Lockdowns in the Atlanta Metropolitan Area
Feb 27, 2023



This paper analyzes the impact of COVID-19 related lockdowns in the Atlanta, Georgia metropolitan area by examining commuter patterns in three periods: prior to, during, and after the pandemic lockdown. A cellular phone location dataset is utilized in a novel pipeline to infer the home and work locations of thousands of users from the Density-based Spatial Clustering of Applications with Noise (DBSCAN) algorithm. The coordinates derived from the clustering are put through a reverse geocoding process from which word embeddings are extracted in order to categorize the industry of each work place based on the workplace name and Point of Interest (POI) mapping. Frequencies of commute from home locations to work locations are analyzed in and across all three time periods. Public health and economic factors are discussed to explain potential reasons for the observed changes in commuter patterns.
Privacy and Bias Analysis of Disclosure Avoidance Systems
Jan 28, 2023



Disclosure avoidance (DA) systems are used to safeguard the confidentiality of data while allowing it to be analyzed and disseminated for analytic purposes. These methods, e.g., cell suppression, swapping, and k-anonymity, are commonly applied and may have significant societal and economic implications. However, a formal analysis of their privacy and bias guarantees has been lacking. This paper presents a framework that addresses this gap: it proposes differentially private versions of these mechanisms and derives their privacy bounds. In addition, the paper compares their performance with traditional differential privacy mechanisms in terms of accuracy and fairness on US Census data release and classification tasks. The results show that, contrary to popular beliefs, traditional differential privacy techniques may be superior in terms of accuracy and fairness to differential private counterparts of widely used DA mechanisms.
Two-Stage Learning For the Flexible Job Shop Scheduling Problem
Jan 23, 2023



The Flexible Job-shop Scheduling Problem (FJSP) is an important combinatorial optimization problem that arises in manufacturing and service settings. FJSP is composed of two subproblems, an assignment problem that assigns tasks to machines, and a scheduling problem that determines the starting times of tasks on their chosen machines. Solving FJSP instances of realistic size and composition is an ongoing challenge even under simplified, deterministic assumptions. Motivated by the inevitable randomness and uncertainties in supply chains, manufacturing, and service operations, this paper investigates the potential of using a deep learning framework to generate fast and accurate approximations for FJSP. In particular, this paper proposes a two-stage learning framework 2SLFJSP that explicitly models the hierarchical nature of FJSP decisions, uses a confidence-aware branching scheme to generate appropriate instances for the scheduling stage from the assignment predictions and leverages a novel symmetry-breaking formulation to improve learnability. 2SL-FJSP is evaluated on instances from the FJSP benchmark library. Results show that 2SL-FJSP can generate high-quality solutions in milliseconds, outperforming a state-of-the-art reinforcement learning approach recently proposed in the literature, and other heuristics commonly used in practice.
Compact Optimization Learning for AC Optimal Power Flow
Jan 21, 2023This paper reconsiders end-to-end learning approaches to the Optimal Power Flow (OPF). Existing methods, which learn the input/output mapping of the OPF, suffer from scalability issues due to the high dimensionality of the output space. This paper first shows that the space of optimal solutions can be significantly compressed using principal component analysis (PCA). It then proposes Compact Learning, a new method that learns in a subspace of the principal components before translating the vectors into the original output space. This compression reduces the number of trainable parameters substantially, improving scalability and effectiveness. Compact Learning is evaluated on a variety of test cases from the PGLib with up to 30,000 buses. The paper also shows that the output of Compact Learning can be used to warm-start an exact AC solver to restore feasibility, while bringing significant speed-ups.
Confidence-Aware Graph Neural Networks for Learning Reliability Assessment Commitments
Nov 28, 2022



Reliability Assessment Commitment (RAC) Optimization is increasingly important in grid operations due to larger shares of renewable generations in the generation mix and increased prediction errors. Independent System Operators (ISOs) also aim at using finer time granularities, longer time horizons, and possibly stochastic formulations for additional economic and reliability benefits. The goal of this paper is to address the computational challenges arising in extending the scope of RAC formulations. It presents RACLEARN that (1) uses Graph Neural Networks (GNN) to predict generator commitments and active line constraints, (2) associates a confidence value to each commitment prediction, (3) selects a subset of the high-confidence predictions, which are (4) repaired for feasibility, and (5) seeds a state-of-the-art optimization algorithm with the feasible predictions and the active constraints. Experimental results on exact RAC formulations used by the Midcontinent Independent System Operator (MISO) and an actual transmission network (8965 transmission lines, 6708 buses, 1890 generators, and 6262 load units) show that the RACLEARN framework can speed up RAC optimization by factors ranging from 2 to 4 with negligible loss in solution quality.
Fairness Increases Adversarial Vulnerability
Nov 23, 2022



The remarkable performance of deep learning models and their applications in consequential domains (e.g., facial recognition) introduces important challenges at the intersection of equity and security. Fairness and robustness are two desired notions often required in learning models. Fairness ensures that models do not disproportionately harm (or benefit) some groups over others, while robustness measures the models' resilience against small input perturbations. This paper shows the existence of a dichotomy between fairness and robustness, and analyzes when achieving fairness decreases the model robustness to adversarial samples. The reported analysis sheds light on the factors causing such contrasting behavior, suggesting that distance to the decision boundary across groups as a key explainer for this behavior. Extensive experiments on non-linear models and different architectures validate the theoretical findings in multiple vision domains. Finally, the paper proposes a simple, yet effective, solution to construct models achieving good tradeoffs between fairness and robustness.
Just-In-Time Learning for Operational Risk Assessment in Power Grids
Sep 26, 2022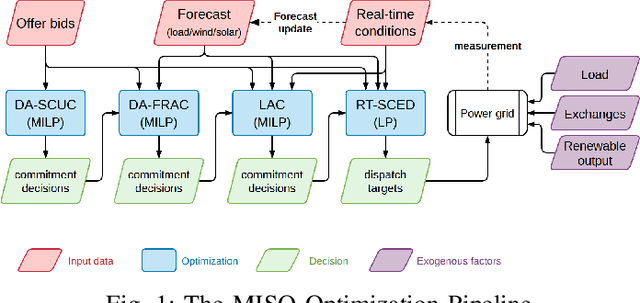
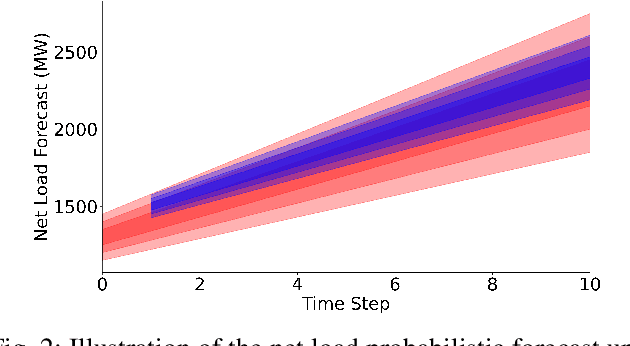
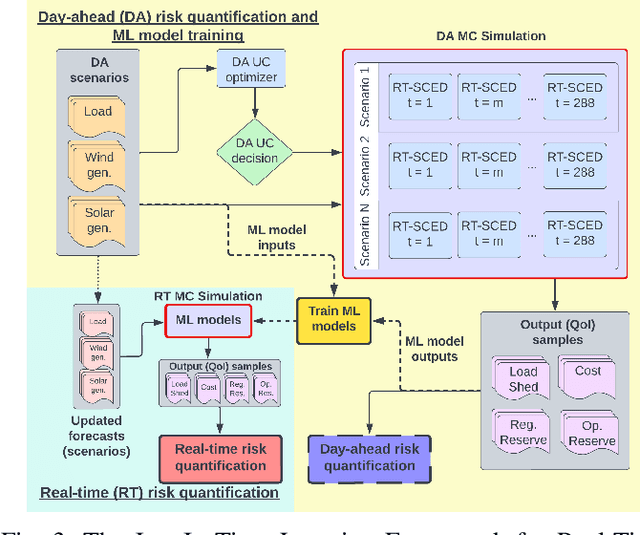
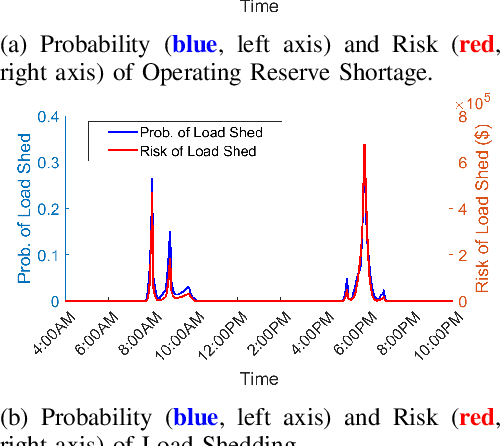
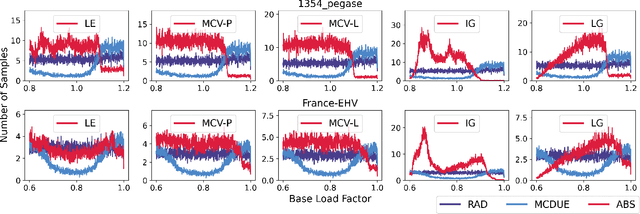
In a grid with a significant share of renewable generation, operators will need additional tools to evaluate the operational risk due to the increased volatility in load and generation. The computational requirements of the forward uncertainty propagation problem, which must solve numerous security-constrained economic dispatch (SCED) optimizations, is a major barrier for such real-time risk assessment. This paper proposes a Just-In-Time Risk Assessment Learning Framework (JITRALF) as an alternative. JITRALF trains risk surrogates, one for each hour in the day, using Machine Learning (ML) to predict the quantities needed to estimate risk, without explicitly solving the SCED problem. This significantly reduces the computational burden of the forward uncertainty propagation and allows for fast, real-time risk estimation. The paper also proposes a novel, asymmetric loss function and shows that models trained using the asymmetric loss perform better than those using symmetric loss functions. JITRALF is evaluated on the French transmission system for assessing the risk of insufficient operating reserves, the risk of load shedding, and the expected operating cost.
Self-Supervised Primal-Dual Learning for Constrained Optimization
Aug 18, 2022
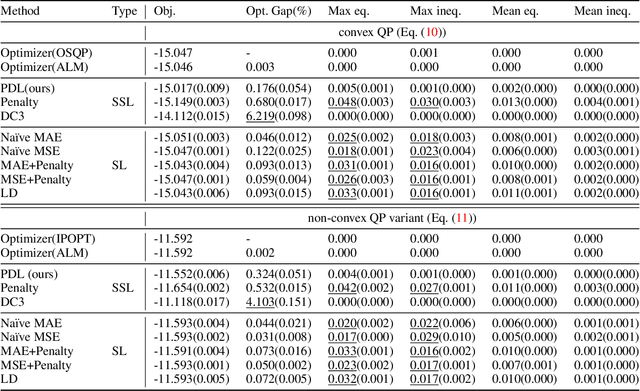
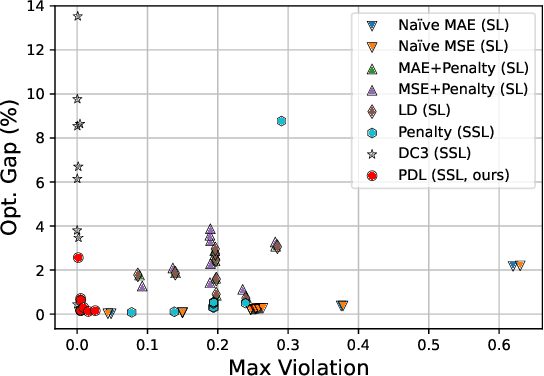
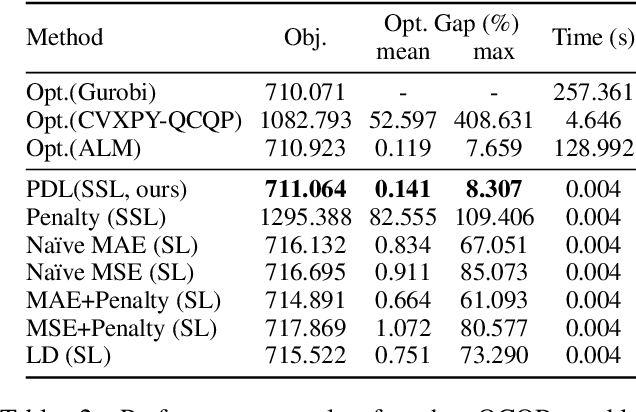
This paper studies how to train machine-learning models that directly approximate the optimal solutions of constrained optimization problems. This is an empirical risk minimization under constraints, which is challenging as training must balance optimality and feasibility conditions. Supervised learning methods often approach this challenge by training the model on a large collection of pre-solved instances. This paper takes a different route and proposes the idea of Primal-Dual Learning (PDL), a self-supervised training method that does not require a set of pre-solved instances or an optimization solver for training and inference. Instead, PDL mimics the trajectory of an Augmented Lagrangian Method (ALM) and jointly trains primal and dual neural networks. Being a primal-dual method, PDL uses instance-specific penalties of the constraint terms in the loss function used to train the primal network. Experiments show that, on a set of nonlinear optimization benchmarks, PDL typically exhibits negligible constraint violations and minor optimality gaps, and is remarkably close to the ALM optimization. PDL also demonstrated improved or similar performance in terms of the optimality gaps, constraint violations, and training times compared to existing approaches.
Active Bucketized Learning for ACOPF Optimization Proxies
Aug 16, 2022
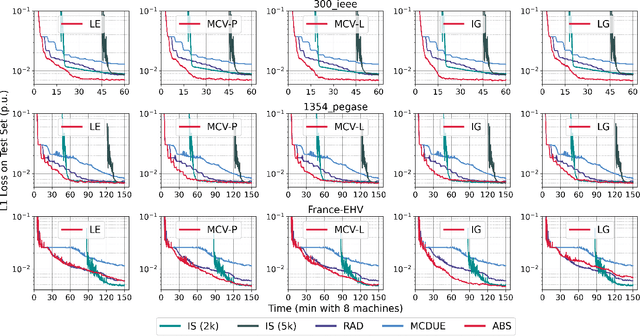
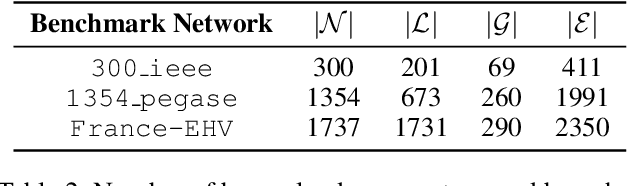
This paper considers optimization proxies for Optimal Power Flow (OPF), i.e., machine-learning models that approximate the input/output relationship of OPF. Recent work has focused on showing that such proxies can be of high fidelity. However, their training requires significant data, each instance necessitating the (offline) solving of an OPF for a sample of the input distribution. To meet the requirements of market-clearing applications, this paper proposes Active Bucketized Sampling (ABS), a novel active learning framework that aims at training the best possible OPF proxy within a time limit. ABS partitions the input distribution into buckets and uses an acquisition function to determine where to sample next. It relies on an adaptive learning rate that increases and decreases over time. Experimental results demonstrate the benefits of ABS.
Learning Regionally Decentralized AC Optimal Power Flows with ADMM
May 08, 2022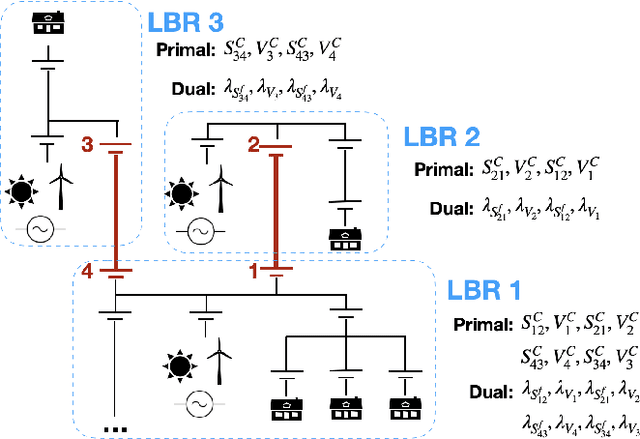

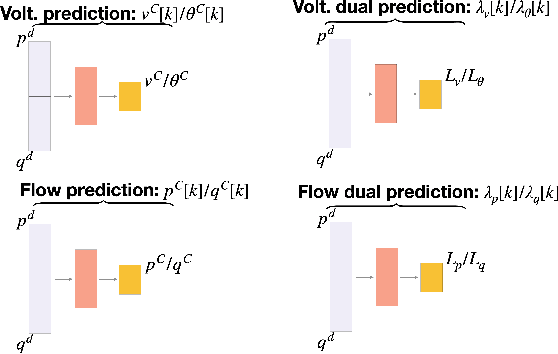

One potential future for the next generation of smart grids is the use of decentralized optimization algorithms and secured communications for coordinating renewable generation (e.g., wind/solar), dispatchable devices (e.g., coal/gas/nuclear generations), demand response, battery & storage facilities, and topology optimization. The Alternating Direction Method of Multipliers (ADMM) has been widely used in the community to address such decentralized optimization problems and, in particular, the AC Optimal Power Flow (AC-OPF). This paper studies how machine learning may help in speeding up the convergence of ADMM for solving AC-OPF. It proposes a novel decentralized machine-learning approach, namely ML-ADMM, where each agent uses deep learning to learn the consensus parameters on the coupling branches. The paper also explores the idea of learning only from ADMM runs that exhibit high-quality convergence properties, and proposes filtering mechanisms to select these runs. Experimental results on test cases based on the French system demonstrate the potential of the approach in speeding up the convergence of ADMM significantly.