 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Mathematics Research with AI-Driven Formal Proof Search
May 21, 2026Large language models (LLMs) increasingly excel at mathematical reasoning, but their unreliability limits their utility in mathematics research. A mitigation is using LLMs to generate formal proofs in languages like Lean. We perform the first large-scale evaluation of this method's ability to solve open problems. Our most capable agent autonomously resolved 9 of 353 open Erdős problems at the per-problem cost of a few hundred dollars, proved 44/492 OEIS conjectures, and is being deployed in combinatorics, optimization, graph theory, algebraic geometry, and quantum optics research. A basic agent alternating LLM-based generation with Lean-based verification replicated the Erdős successes but proved costlier on the hardest problems. These findings demonstrate the power of AI-aided formal proof search and shed light on the agent designs that enable it.
An Improved Last-Iterate Convergence Rate for Anchored Gradient Descent Ascent
Apr 04, 2026We analyze the last-iterate convergence of the Anchored Gradient Descent Ascent algorithm for smooth convex-concave min-max problems. While previous work established a last-iterate rate of $\mathcal{O}(1/t^{2-2p})$ for the squared gradient norm, where $p \in (1/2, 1)$, it remained an open problem whether the improved exact $\mathcal{O}(1/t)$ rate is achievable. In this work, we resolve this question in the affirmative. This result was discovered autonomously by an AI system capable of writing formal proofs in Lean. The Lean proof can be accessed at https://github.com/google-deepmind/formal-conjectures/pull/3675/commits/a13226b49fd3b897f4c409194f3bcbeb96a08515
ArchAgent: Agentic AI-driven Computer Architecture Discovery
Feb 25, 2026Agile hardware design flows are a critically needed force multiplier to meet the exploding demand for compute. Recently, agentic generative AI systems have demonstrated significant advances in algorithm design, improving code efficiency, and enabling discovery across scientific domains. Bridging these worlds, we present ArchAgent, an automated computer architecture discovery system built on AlphaEvolve. We show ArchAgent's ability to automatically design/implement state-of-the-art (SoTA) cache replacement policies (architecting new mechanisms/logic, not only changing parameters), broadly within the confines of an established cache replacement policy design competition. In two days without human intervention, ArchAgent generated a policy achieving a 5.3% IPC speedup improvement over the prior SoTA on public multi-core Google Workload Traces. On the heavily-explored single-core SPEC06 workloads, it generated a policy in just 18 days showing a 0.9% IPC speedup improvement over the existing SoTA (a similar "winning margin" as reported by the existing SoTA). ArchAgent achieved these gains 3-5x faster than prior human-developed SoTA policies. Agentic flows also enable "post-silicon hyperspecialization" where agents tune runtime-configurable parameters exposed in hardware policies to further align the policies with a specific workload (mix). Exploiting this, we demonstrate a 2.4% IPC speedup improvement over prior SoTA on SPEC06 workloads. Finally, we outline broader implications for computer architecture research in the era of agentic AI. For example, we demonstrate the phenomenon of "simulator escapes", where the agentic AI flow discovered and exploited a loophole in a popular microarchitectural simulator - a consequence of the fact that these research tools were designed for a (now past) world where they were exclusively operated by humans acting in good-faith.
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Jun 16, 2025In this white paper, we present AlphaEvolve, an evolutionary coding agent that substantially enhances capabilities of state-of-the-art LLMs on highly challenging tasks such as tackling open scientific problems or optimizing critical pieces of computational infrastructure. AlphaEvolve orchestrates an autonomous pipeline of LLMs, whose task is to improve an algorithm by making direct changes to the code. Using an evolutionary approach, continuously receiving feedback from one or more evaluators, AlphaEvolve iteratively improves the algorithm, potentially leading to new scientific and practical discoveries. We demonstrate the broad applicability of this approach by applying it to a number of important computational problems. When applied to optimizing critical components of large-scale computational stacks at Google, AlphaEvolve developed a more efficient scheduling algorithm for data centers, found a functionally equivalent simplification in the circuit design of hardware accelerators, and accelerated the training of the LLM underpinning AlphaEvolve itself. Furthermore, AlphaEvolve discovered novel, provably correct algorithms that surpass state-of-the-art solutions on a spectrum of problems in mathematics and computer science, significantly expanding the scope of prior automated discovery methods (Romera-Paredes et al., 2023). Notably, AlphaEvolve developed a search algorithm that found a procedure to multiply two $4 \times 4$ complex-valued matrices using $48$ scalar multiplications; offering the first improvement, after 56 years, over Strassen's algorithm in this setting. We believe AlphaEvolve and coding agents like it can have a significant impact in improving solutions of problems across many areas of science and computation.
Graph Neural Networks for Link Prediction with Subgraph Sketching
Oct 03, 2022
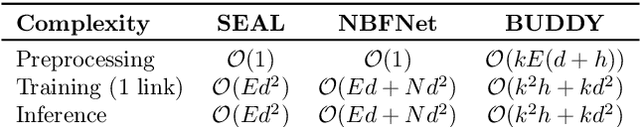
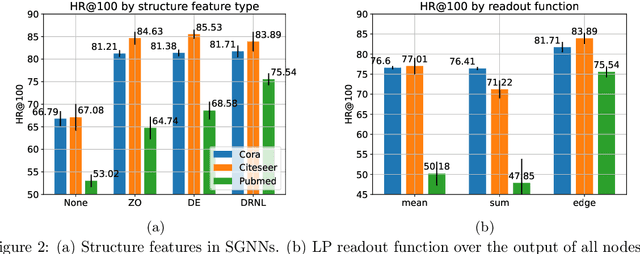
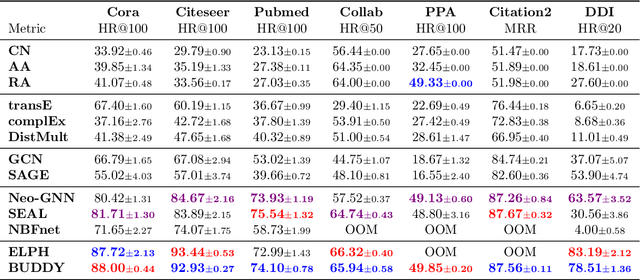
Many Graph Neural Networks (GNNs) perform poorly compared to simple heuristics on Link Prediction (LP) tasks. This is due to limitations in expressive power such as the inability to count triangles (the backbone of most LP heuristics) and because they can not distinguish automorphic nodes (those having identical structural roles). Both expressiveness issues can be alleviated by learning link (rather than node) representations and incorporating structural features such as triangle counts. Since explicit link representations are often prohibitively expensive, recent works resorted to subgraph-based methods, which have achieved state-of-the-art performance for LP, but suffer from poor efficiency due to high levels of redundancy between subgraphs. We analyze the components of subgraph GNN (SGNN) methods for link prediction. Based on our analysis, we propose a novel full-graph GNN called ELPH (Efficient Link Prediction with Hashing) that passes subgraph sketches as messages to approximate the key components of SGNNs without explicit subgraph construction. ELPH is provably more expressive than Message Passing GNNs (MPNNs). It outperforms existing SGNN models on many standard LP benchmarks while being orders of magnitude faster. However, it shares the common GNN limitation that it is only efficient when the dataset fits in GPU memory. Accordingly, we develop a highly scalable model, called BUDDY, which uses feature precomputation to circumvent this limitation without sacrificing predictive performance. Our experiments show that BUDDY also outperforms SGNNs on standard LP benchmarks while being highly scalable and faster than ELPH.
Differentiating the Black-Box: Optimization with Local Generative Surrogates
Feb 11, 2020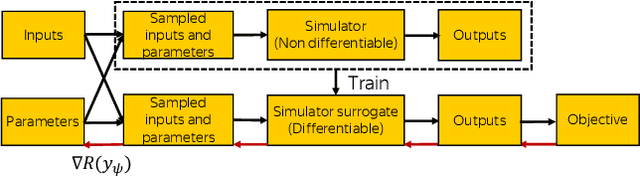
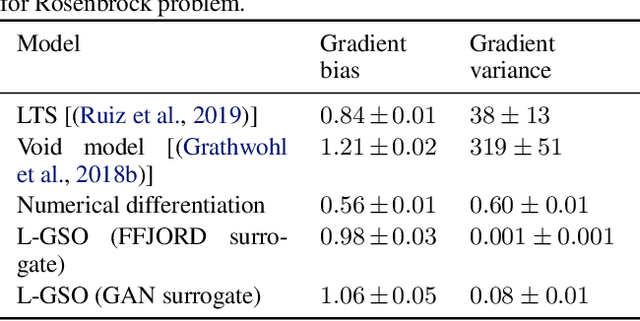
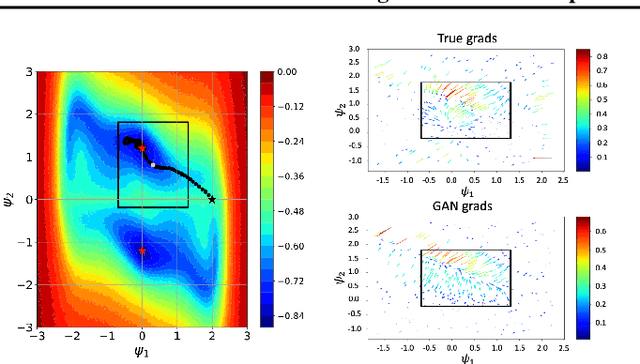

We propose a novel method for gradient-based optimization of black-box simulators using differentiable local surrogate models. In fields such as physics and engineering, many processes are modeled with non-differentiable simulators with intractable likelihoods. Optimization of these forward models is particularly challenging, especially when the simulator is stochastic. To address such cases, we introduce the use of deep generative models to iteratively approximate the simulator in local neighborhoods of the parameter space. We demonstrate that these local surrogates can be used to approximate the gradient of the simulator, and thus enable gradient-based optimization of simulator parameters. In cases where the dependence of the simulator on the parameter space is constrained to a low dimensional submanifold, we observe that our method attains minima faster than all baseline methods, including Bayesian optimization, numerical optimization, and REINFORCE driven approaches.