 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Quantized Models for Planning
Jun 10, 2021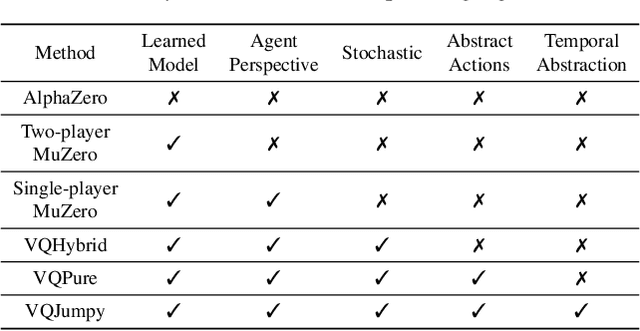
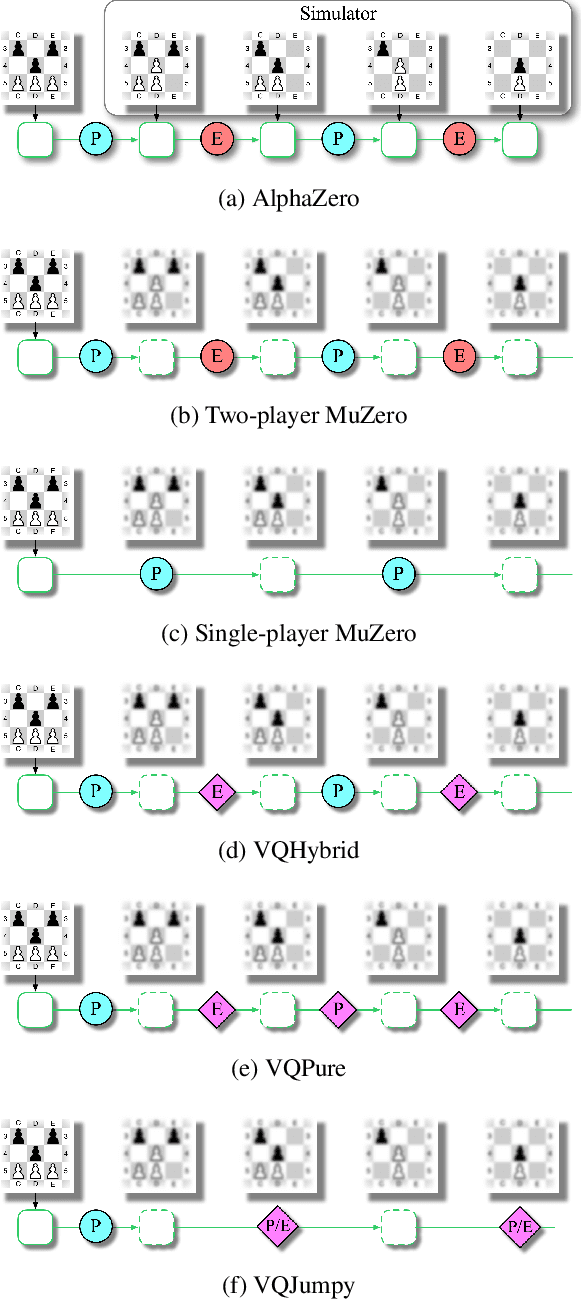
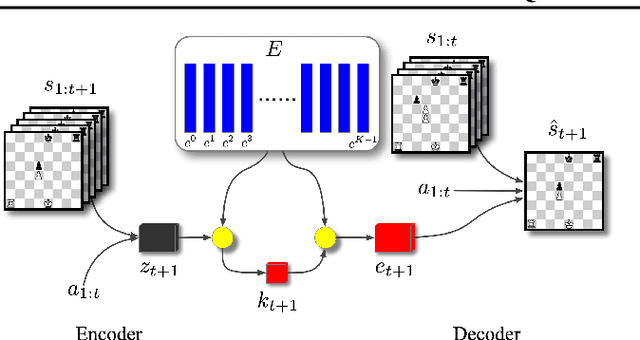
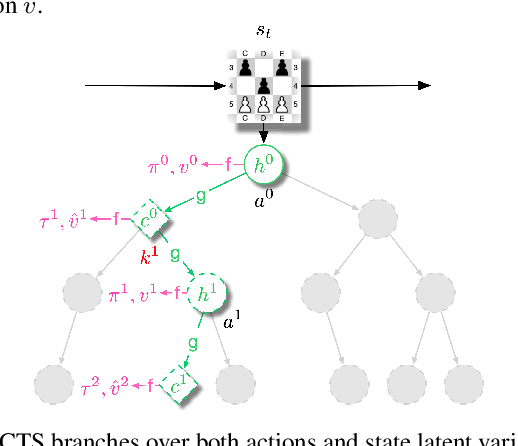
Recent developments in the field of model-based RL have proven successful in a range of environments, especially ones where planning is essential. However, such successes have been limited to deterministic fully-observed environments. We present a new approach that handles stochastic and partially-observable environments. Our key insight is to use discrete autoencoders to capture the multiple possible effects of an action in a stochastic environment. We use a stochastic variant of Monte Carlo tree search to plan over both the agent's actions and the discrete latent variables representing the environment's response. Our approach significantly outperforms an offline version of MuZero on a stochastic interpretation of chess where the opponent is considered part of the environment. We also show that our approach scales to DeepMind Lab, a first-person 3D environment with large visual observations and partial observability.
Machine Translation Decoding beyond Beam Search
Apr 12, 2021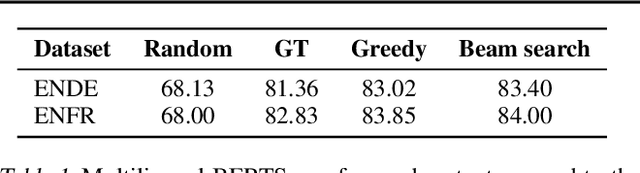
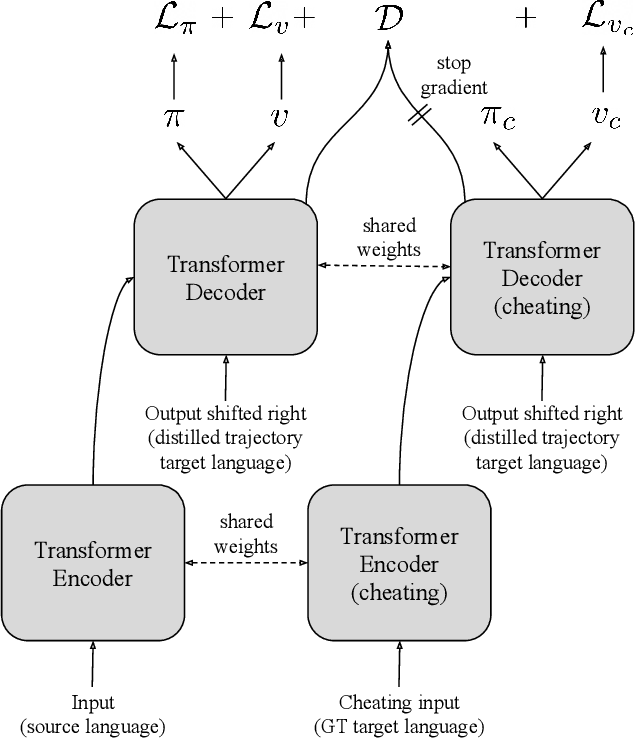
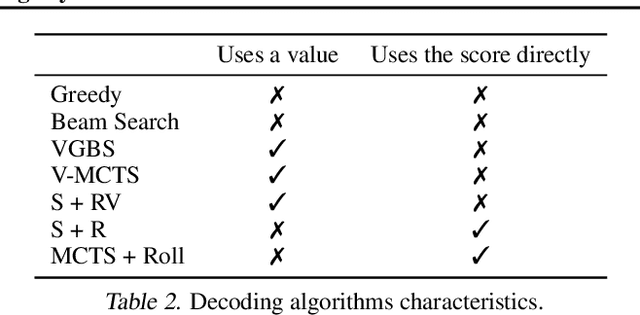
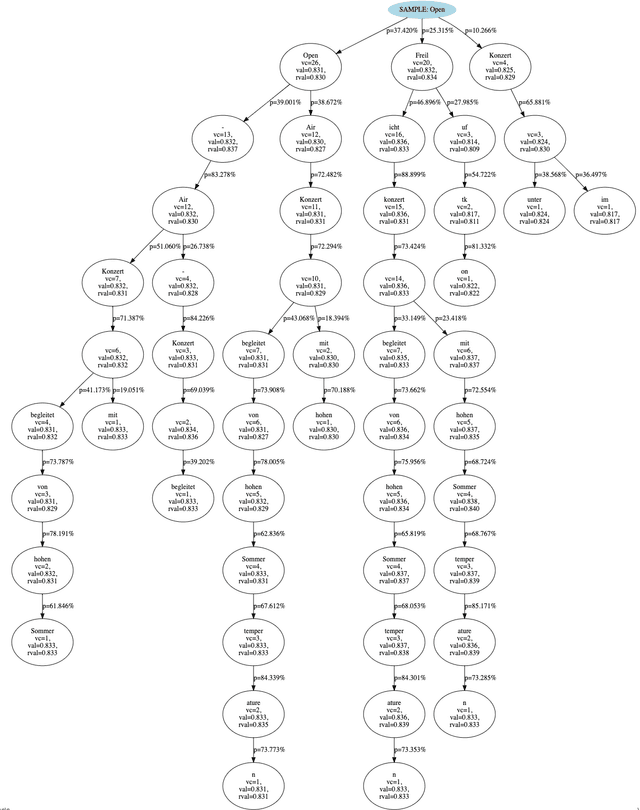
Beam search is the go-to method for decoding auto-regressive machine translation models. While it yields consistent improvements in terms of BLEU, it is only concerned with finding outputs with high model likelihood, and is thus agnostic to whatever end metric or score practitioners care about. Our aim is to establish whether beam search can be replaced by a more powerful metric-driven search technique. To this end, we explore numerous decoding algorithms, including some which rely on a value function parameterised by a neural network, and report results on a variety of metrics. Notably, we introduce a Monte-Carlo Tree Search (MCTS) based method and showcase its competitiveness. We provide a blueprint for how to use MCTS fruitfully in language applications, which opens promising future directions. We find that which algorithm is best heavily depends on the characteristics of the goal metric; we believe that our extensive experiments and analysis will inform further research in this area.
Efficient Visual Pretraining with Contrastive Detection
Mar 19, 2021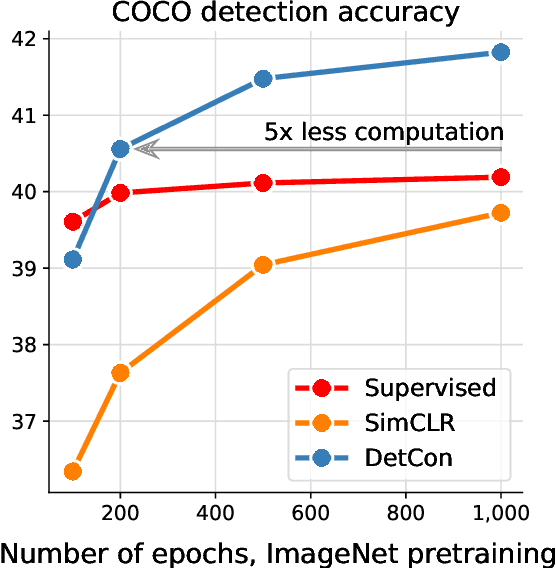
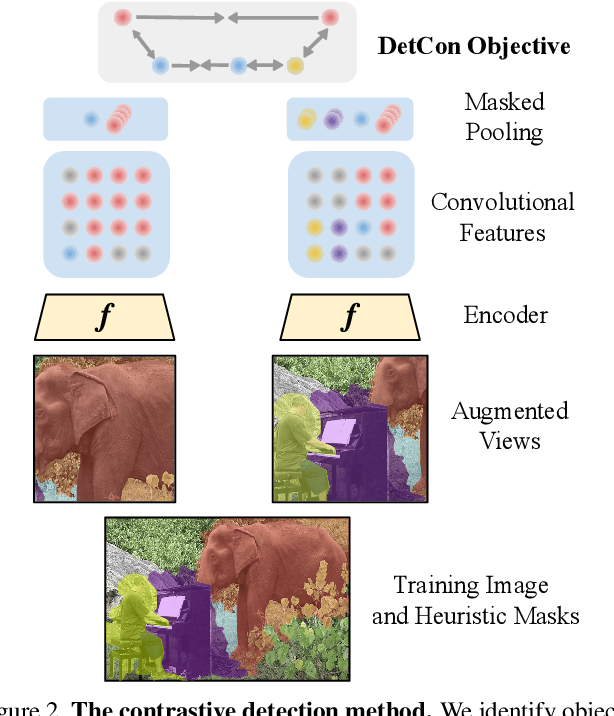
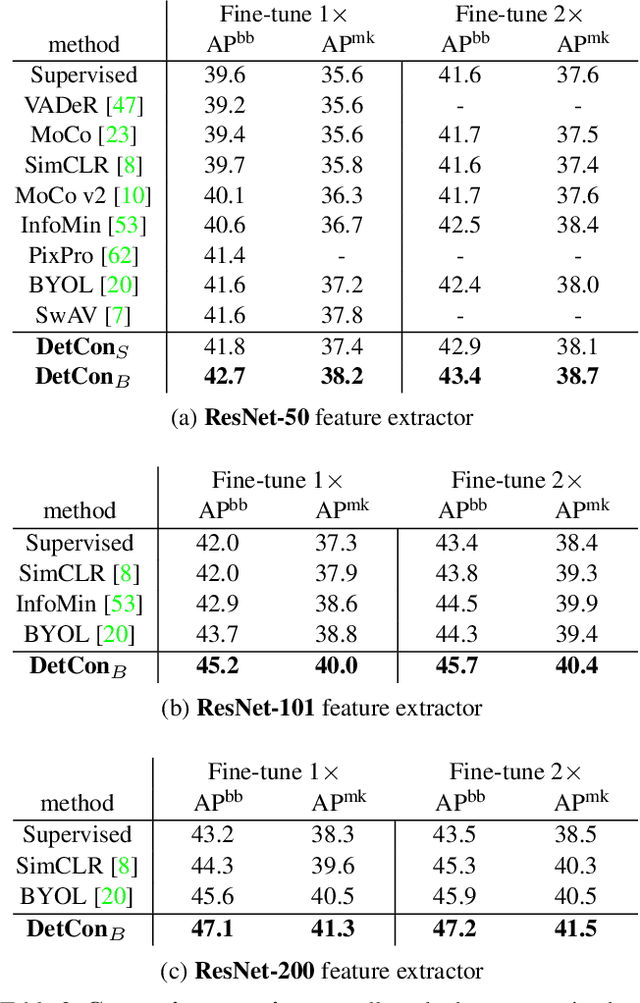

Self-supervised pretraining has been shown to yield powerful representations for transfer learning. These performance gains come at a large computational cost however, with state-of-the-art methods requiring an order of magnitude more computation than supervised pretraining. We tackle this computational bottleneck by introducing a new self-supervised objective, contrastive detection, which tasks representations with identifying object-level features across augmentations. This objective extracts a rich learning signal per image, leading to state-of-the-art transfer performance from ImageNet to COCO, while requiring up to 5x less pretraining. In particular, our strongest ImageNet-pretrained model performs on par with SEER, one of the largest self-supervised systems to date, which uses 1000x more pretraining data. Finally, our objective seamlessly handles pretraining on more complex images such as those in COCO, closing the gap with supervised transfer learning from COCO to PASCAL.
Perceiver: General Perception with Iterative Attention
Mar 04, 2021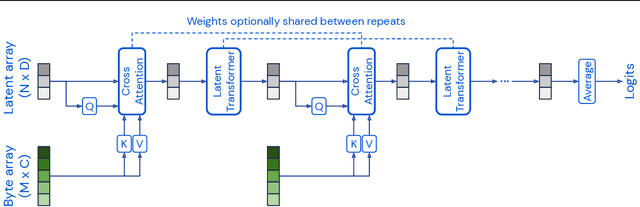

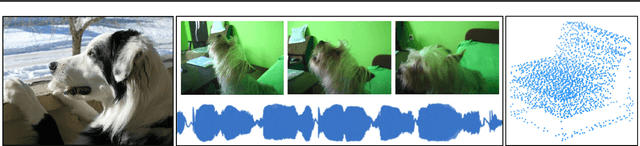
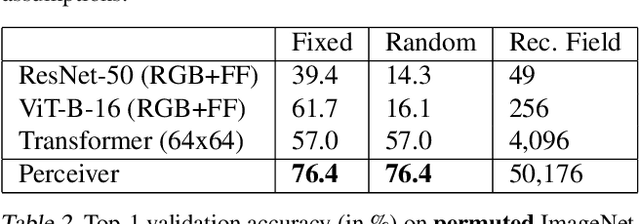
Biological systems understand the world by simultaneously processing high-dimensional inputs from modalities as diverse as vision, audition, touch, proprioception, etc. The perception models used in deep learning on the other hand are designed for individual modalities, often relying on domain-specific assumptions such as the local grid structures exploited by virtually all existing vision models. These priors introduce helpful inductive biases, but also lock models to individual modalities. In this paper we introduce the Perceiver - a model that builds upon Transformers and hence makes few architectural assumptions about the relationship between its inputs, but that also scales to hundreds of thousands of inputs, like ConvNets. The model leverages an asymmetric attention mechanism to iteratively distill inputs into a tight latent bottleneck, allowing it to scale to handle very large inputs. We show that this architecture performs competitively or beyond strong, specialized models on classification tasks across various modalities: images, point clouds, audio, video and video+audio. The Perceiver obtains performance comparable to ResNet-50 on ImageNet without convolutions and by directly attending to 50,000 pixels. It also surpasses state-of-the-art results for all modalities in AudioSet.
The MineRL 2020 Competition on Sample Efficient Reinforcement Learning using Human Priors
Jan 26, 2021
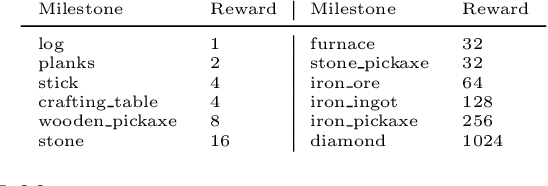
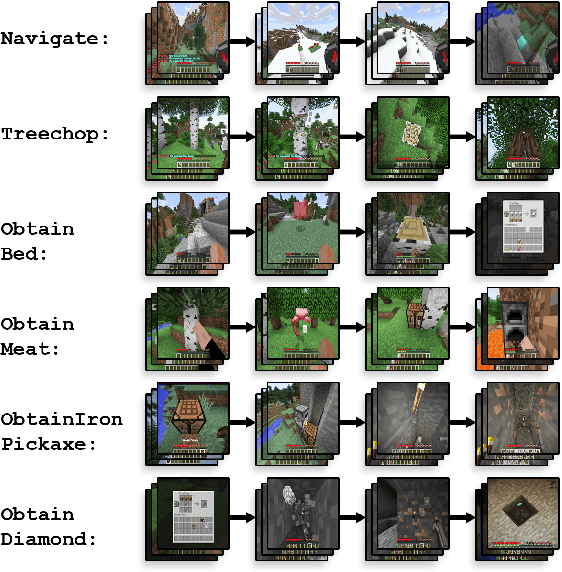
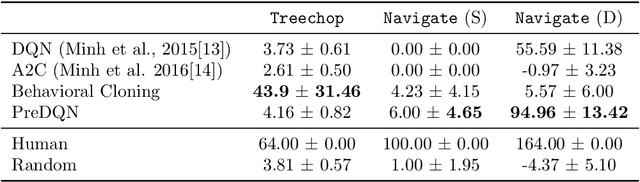
Although deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples, affording only a shrinking segment of the AI community access to their development. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we propose this second iteration of the MineRL Competition. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, participants compete under a limited environment sample-complexity budget to develop systems which solve the MineRL ObtainDiamond task in Minecraft, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures and shaders. At the end of each round, competitors submit containerized versions of their learning algorithms to the AIcrowd platform where they are trained from scratch on a hold-out dataset-environment pair for a total of 4-days on a pre-specified hardware platform. In this follow-up iteration to the NeurIPS 2019 MineRL Competition, we implement new features to expand the scale and reach of the competition. In response to the feedback of the previous participants, we introduce a second minor track focusing on solutions without access to environment interactions of any kind except during test-time. Further we aim to prompt domain agnostic submissions by implementing several novel competition mechanics including action-space randomization and desemantization of observations and actions.
Solving Mixed Integer Programs Using Neural Networks
Dec 23, 2020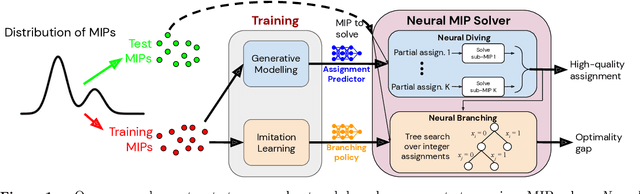
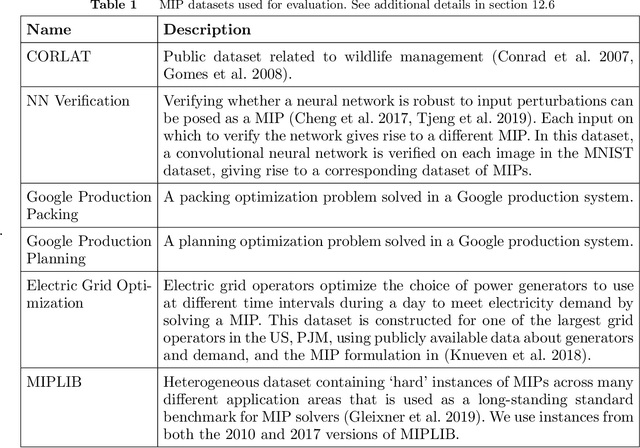
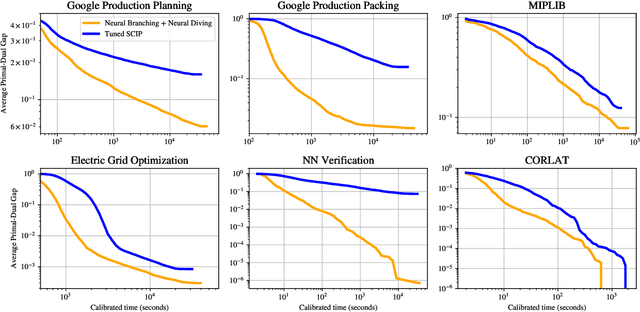
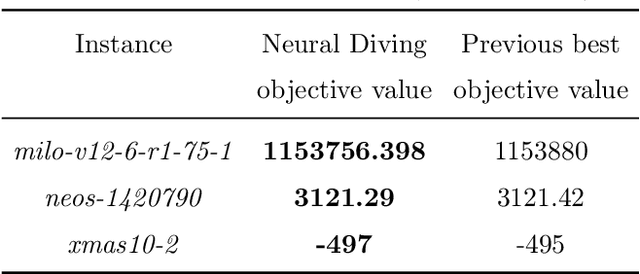
Mixed Integer Programming (MIP) solvers rely on an array of sophisticated heuristics developed with decades of research to solve large-scale MIP instances encountered in practice. Machine learning offers to automatically construct better heuristics from data by exploiting shared structure among instances in the data. This paper applies learning to the two key sub-tasks of a MIP solver, generating a high-quality joint variable assignment, and bounding the gap in objective value between that assignment and an optimal one. Our approach constructs two corresponding neural network-based components, Neural Diving and Neural Branching, to use in a base MIP solver such as SCIP. Neural Diving learns a deep neural network to generate multiple partial assignments for its integer variables, and the resulting smaller MIPs for un-assigned variables are solved with SCIP to construct high quality joint assignments. Neural Branching learns a deep neural network to make variable selection decisions in branch-and-bound to bound the objective value gap with a small tree. This is done by imitating a new variant of Full Strong Branching we propose that scales to large instances using GPUs. We evaluate our approach on six diverse real-world datasets, including two Google production datasets and MIPLIB, by training separate neural networks on each. Most instances in all the datasets combined have $10^3-10^6$ variables and constraints after presolve, which is significantly larger than previous learning approaches. Comparing solvers with respect to primal-dual gap averaged over a held-out set of instances, the learning-augmented SCIP is 2x to 10x better on all datasets except one on which it is $10^5$x better, at large time limits. To the best of our knowledge, ours is the first learning approach to demonstrate such large improvements over SCIP on both large-scale real-world application datasets and MIPLIB.
AlignNet: Unsupervised Entity Alignment
Jul 21, 2020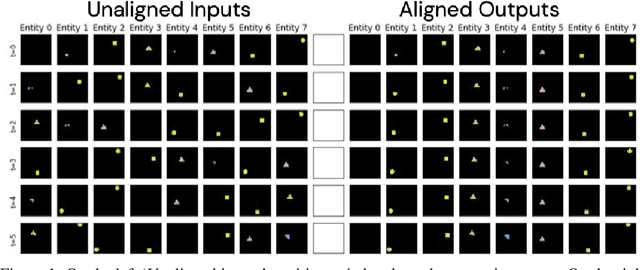

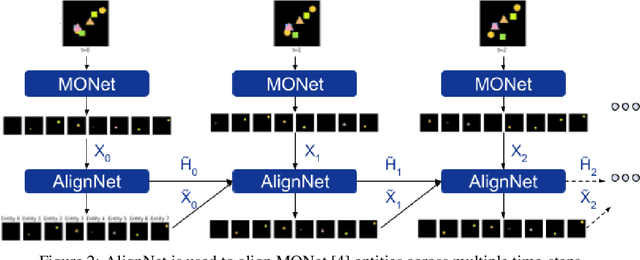
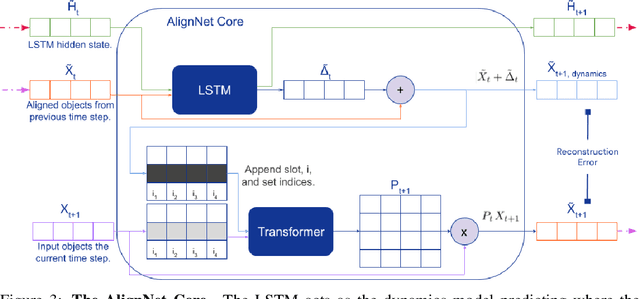
Recently developed deep learning models are able to learn to segment scenes into component objects without supervision. This opens many new and exciting avenues of research, allowing agents to take objects (or entities) as inputs, rather that pixels. Unfortunately, while these models provide excellent segmentation of a single frame, they do not keep track of how objects segmented at one time-step correspond (or align) to those at a later time-step. The alignment (or correspondence) problem has impeded progress towards using object representations in downstream tasks. In this paper we take steps towards solving the alignment problem, presenting the AlignNet, an unsupervised alignment module.
Strong Generalization and Efficiency in Neural Programs
Jul 08, 2020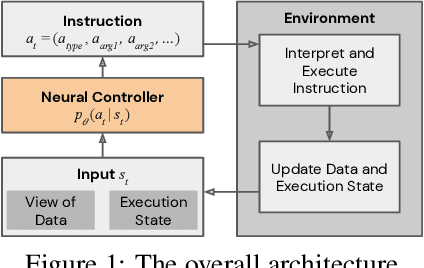

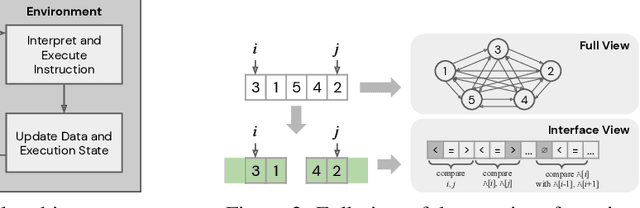
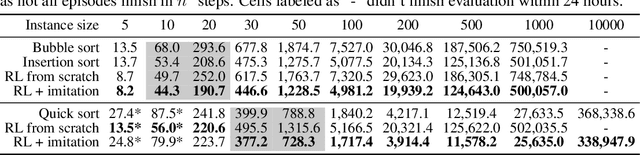
We study the problem of learning efficient algorithms that strongly generalize in the framework of neural program induction. By carefully designing the input / output interfaces of the neural model and through imitation, we are able to learn models that produce correct results for arbitrary input sizes, achieving strong generalization. Moreover, by using reinforcement learning, we optimize for program efficiency metrics, and discover new algorithms that surpass the teacher used in imitation. With this, our approach can learn to outperform custom-written solutions for a variety of problems, as we tested it on sorting, searching in ordered lists and the NP-complete 0/1 knapsack problem, which sets a notable milestone in the field of Neural Program Induction. As highlights, our learned model can perform sorting perfectly on any input data size we tested on, with $O(n log n)$ complexity, whilst outperforming hand-coded algorithms, including quick sort, in number of operations even for list sizes far beyond those seen during training.
Pointer Graph Networks
Jun 11, 2020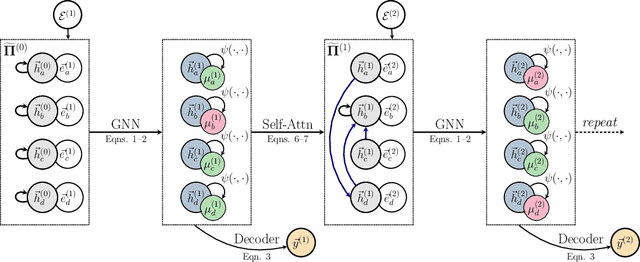


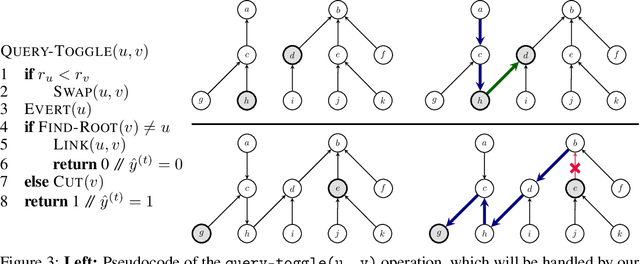
Graph neural networks (GNNs) are typically applied to static graphs that are assumed to be known upfront. This static input structure is often informed purely by insight of the machine learning practitioner, and might not be optimal for the actual task the GNN is solving. In absence of reliable domain expertise, one might resort to inferring the latent graph structure, which is often difficult due to the vast search space of possible graphs. Here we introduce Pointer Graph Networks (PGNs) which augment sets or graphs with additional inferred edges for improved model expressivity. PGNs allow each node to dynamically point to another node, followed by message passing over these pointers. The sparsity of this adaptable graph structure makes learning tractable while still being sufficiently expressive to simulate complex algorithms. Critically, the pointing mechanism is directly supervised to model long-term sequences of operations on classical data structures, incorporating useful structural inductive biases from theoretical computer science. Qualitatively, we demonstrate that PGNs can learn parallelisable variants of pointer-based data structures, namely disjoint set unions and link/cut trees. PGNs generalise out-of-distribution to 5x larger test inputs on dynamic graph connectivity tasks, outperforming unrestricted GNNs and Deep Sets.
Retrospective Analysis of the 2019 MineRL Competition on Sample Efficient Reinforcement Learning
Mar 27, 2020To facilitate research in the direction of sample-efficient reinforcement learning, we held the MineRL Competition on Sample-Efficient Reinforcement Learning Using Human Priors at the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS 2019). The primary goal of this competition was to promote the development of algorithms that use human demonstrations alongside reinforcement learning to reduce the number of samples needed to solve complex, hierarchical, and sparse environments. We describe the competition and provide an overview of the top solutions, each of which uses deep reinforcement learning and/or imitation learning. We also discuss the impact of our organizational decisions on the competition as well as future directions for improvement.