 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch and Learn: Learning to Use Computers from Online Videos
Oct 06, 2025Computer use agents (CUAs) need to plan task workflows grounded in diverse, ever-changing applications and environments, but learning is hindered by the scarcity of large-scale, high-quality training data in the target application. Existing datasets are domain-specific, static, and costly to annotate, while current synthetic data generation methods often yield simplistic or misaligned task demonstrations. To address these limitations, we introduce Watch & Learn (W&L), a framework that converts human demonstration videos readily available on the Internet into executable UI trajectories at scale. Instead of directly generating trajectories or relying on ad hoc reasoning heuristics, we cast the problem as an inverse dynamics objective: predicting the user's action from consecutive screen states. This formulation reduces manual engineering, is easier to learn, and generalizes more robustly across applications. Concretely, we develop an inverse dynamics labeling pipeline with task-aware video retrieval, generate over 53k high-quality trajectories from raw web videos, and demonstrate that these trajectories improve CUAs both as in-context demonstrations and as supervised training data. On the challenging OSWorld benchmark, UI trajectories extracted with W&L consistently enhance both general-purpose and state-of-the-art frameworks in-context, and deliver stronger gains for open-source models under supervised training. These results highlight web-scale human demonstration videos as a practical and scalable foundation for advancing CUAs towards real-world deployment.
On the Effects of Data Scale on Computer Control Agents
Jun 06, 2024



Autonomous agents that control computer interfaces to accomplish human tasks are emerging. Leveraging LLMs to power such agents has been of special interest, but unless fine-tuned on human-collected task demonstrations, performance is still relatively low. In this work we study whether fine-tuning alone is a viable approach for building real-world computer control agents. %In particularly, we investigate how performance measured on both high and low-level tasks in domain and out of domain scales as more training data is collected. To this end we collect and release a new dataset, AndroidControl, consisting of 15,283 demonstrations of everyday tasks with Android apps. Compared to existing datasets, each AndroidControl task instance includes both high and low-level human-generated instructions, allowing us to explore the level of task complexity an agent can handle. Moreover, AndroidControl is the most diverse computer control dataset to date, including 15,283 unique tasks over 833 Android apps, thus allowing us to conduct in-depth analysis of the model performance in and out of the domain of the training data. Using the dataset, we find that when tested in domain fine-tuned models outperform zero and few-shot baselines and scale in such a way that robust performance might feasibly be obtained simply by collecting more data. Out of domain, performance scales significantly more slowly and suggests that in particular for high-level tasks, fine-tuning on more data alone may be insufficient for achieving robust out-of-domain performance.
VQA Training Sets are Self-play Environments for Generating Few-shot Pools
May 30, 2024



Large-language models and large-vision models are increasingly capable of solving compositional reasoning tasks, as measured by breakthroughs in visual-question answering benchmarks. However, state-of-the-art solutions often involve careful construction of large pre-training and fine-tuning datasets, which can be expensive. The use of external tools, whether other ML models, search engines, or APIs, can significantly improve performance by breaking down high-level reasoning questions into sub-questions that are answerable by individual tools, but this approach has similar dataset construction costs to teach fine-tuned models how to use the available tools. We propose a technique in which existing training sets can be directly used for constructing computational environments with task metrics as rewards. This enables a model to autonomously teach itself to use itself or another model as a tool. By doing so, we augment training sets by integrating external signals. The proposed method starts with zero-shot prompts and iteratively refines them by selecting few-shot examples that maximize the task metric on the training set. Our experiments showcase how Gemini learns how to use itself, or another smaller and specialized model such as ScreenAI, to iteratively improve performance on training sets. Our approach successfully generalizes and improves upon zeroshot performance on charts, infographics, and document visual question-answering datasets
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
May 23, 2024



Autonomous agents that execute human tasks by controlling computers can enhance human productivity and application accessibility. Yet, progress in this field will be driven by realistic and reproducible benchmarks. We present AndroidWorld, a fully functioning Android environment that provides reward signals for 116 programmatic task workflows across 20 real world Android applications. Unlike existing interactive environments, which provide a static test set, AndroidWorld dynamically constructs tasks that are parameterized and expressed in natural language in unlimited ways, thus enabling testing on a much larger and realistic suite of tasks. Reward signals are derived from the computer's system state, making them durable across task variations and extensible across different apps. To demonstrate AndroidWorld's benefits and mode of operation, we introduce a new computer control agent, M3A. M3A can complete 30.6% of the AndroidWorld's tasks, leaving ample room for future work. Furthermore, we adapt a popular desktop web agent to work on Android, which we find to be less effective on mobile, suggesting future research is needed to achieve universal, cross-domain agents. Finally, we conduct a robustness analysis by testing M3A against a range of task variations on a representative subset of tasks, demonstrating that variations in task parameters can significantly alter the complexity of a task and therefore an agent's performance, highlighting the importance of testing agents under diverse conditions. AndroidWorld and the experiments in this paper are available at https://github.com/google-research/android_world.
Latent State Estimation Helps UI Agents to Reason
May 17, 2024



A common problem for agents operating in real-world environments is that the response of an environment to their actions may be non-deterministic and observed through noise. This renders environmental state and progress towards completing a task latent. Despite recent impressive demonstrations of LLM's reasoning abilities on various benchmarks, whether LLMs can build estimates of latent state and leverage them for reasoning has not been explicitly studied. We investigate this problem in the real-world domain of autonomous UI agents. We establish that appropriately prompting LLMs in a zero-shot manner can be formally understood as forming point estimates of latent state in a textual space. In the context of autonomous UI agents we then show that LLMs used in this manner are more than $76\%$ accurate at inferring various aspects of latent state, such as performed (vs. commanded) actions and task progression. Using both public and internal benchmarks and three reasoning methods (zero-shot, CoT-SC & ReAct), we show that LLM-powered agents that explicitly estimate and reason about latent state are able to successfully complete up to 1.6x more tasks than those that do not.
UINav: A maker of UI automation agents
Dec 15, 2023



An automation system that can execute natural language instructions by driving the user interface (UI) of an application can benefit users, especially when situationally or permanently impaired. Traditional automation systems (manual scripting, programming by demonstration tools, etc.) do not produce generalizable models that can tolerate changes in the UI or task workflow. Machine-learned automation agents generalize better, but either work only in simple, hand-crafted applications or rely on large pre-trained models, which may be too computationally expensive to run on mobile devices. In this paper, we propose \emph{UINav}, a demonstration-based agent maker system. UINav agents are lightweight enough to run on mobile devices, yet they achieve high success rates with a modest number of task demonstrations. To minimize the number of task demonstrations, UINav includes a referee model that allows users to receive immediate feedback on tasks where the agent is failing to best guide efforts to collect additional demonstrations. Further, UINav adopts macro actions to reduce an agent's state space, and augments human demonstrations to increase the diversity of training data. Our evaluation demonstrates that with an average of 10 demonstrations per task UINav can achieve an accuracy of 70\% or higher, and that with enough demonstrations it can achieve near-perfect success rates on 40+ different tasks.
Android in the Wild: A Large-Scale Dataset for Android Device Control
Jul 19, 2023



There is a growing interest in device-control systems that can interpret human natural language instructions and execute them on a digital device by directly controlling its user interface. We present a dataset for device-control research, Android in the Wild (AITW), which is orders of magnitude larger than current datasets. The dataset contains human demonstrations of device interactions, including the screens and actions, and corresponding natural language instructions. It consists of 715k episodes spanning 30k unique instructions, four versions of Android (v10-13),and eight device types (Pixel 2 XL to Pixel 6) with varying screen resolutions. It contains multi-step tasks that require semantic understanding of language and visual context. This dataset poses a new challenge: actions available through the user interface must be inferred from their visual appearance. And, instead of simple UI element-based actions, the action space consists of precise gestures (e.g., horizontal scrolls to operate carousel widgets). We organize our dataset to encourage robustness analysis of device-control systems, i.e., how well a system performs in the presence of new task descriptions, new applications, or new platform versions. We develop two agents and report performance across the dataset. The dataset is available at https://github.com/google-research/google-research/tree/master/android_in_the_wild.
Lexi: Self-Supervised Learning of the UI Language
Jan 23, 2023



Humans can learn to operate the user interface (UI) of an application by reading an instruction manual or how-to guide. Along with text, these resources include visual content such as UI screenshots and images of application icons referenced in the text. We explore how to leverage this data to learn generic visio-linguistic representations of UI screens and their components. These representations are useful in many real applications, such as accessibility, voice navigation, and task automation. Prior UI representation models rely on UI metadata (UI trees and accessibility labels), which is often missing, incompletely defined, or not accessible. We avoid such a dependency, and propose Lexi, a pre-trained vision and language model designed to handle the unique features of UI screens, including their text richness and context sensitivity. To train Lexi we curate the UICaption dataset consisting of 114k UI images paired with descriptions of their functionality. We evaluate Lexi on four tasks: UI action entailment, instruction-based UI image retrieval, grounding referring expressions, and UI entity recognition.
Inducing a hierarchy for multi-class classification problems
Feb 20, 2021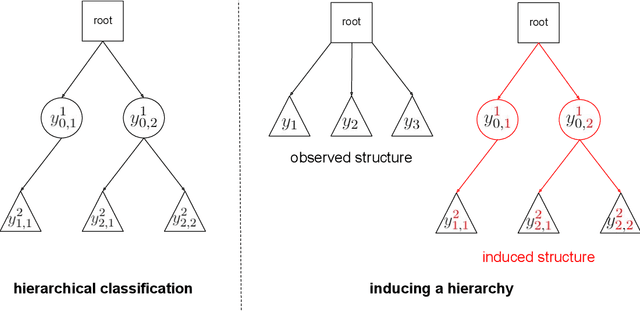
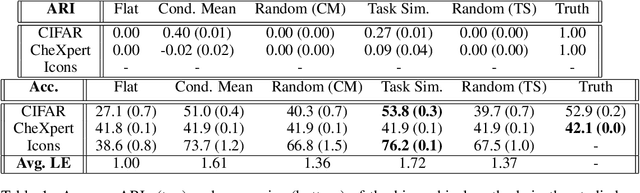
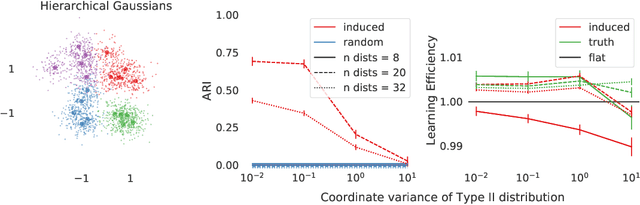
In applications where categorical labels follow a natural hierarchy, classification methods that exploit the label structure often outperform those that do not. Un-fortunately, the majority of classification datasets do not come pre-equipped with a hierarchical structure and classical flat classifiers must be employed. In this paper, we investigate a class of methods that induce a hierarchy that can similarly improve classification performance over flat classifiers. The class of methods follows the structure of first clustering the conditional distributions and subsequently using a hierarchical classifier with the induced hierarchy. We demonstrate the effectiveness of the class of methods both for discovering a latent hierarchy and for improving accuracy in principled simulation settings and three real data applications.
Bew: Towards Answering Business-Entity-Related Web Questions
Dec 10, 2020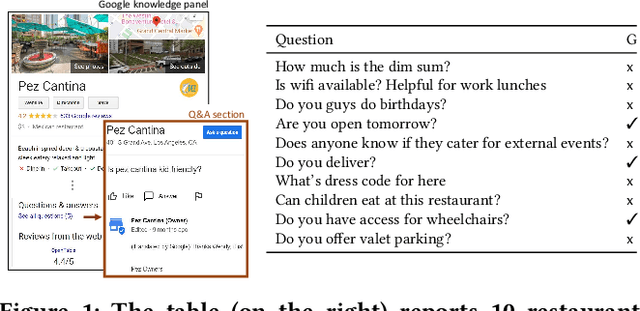
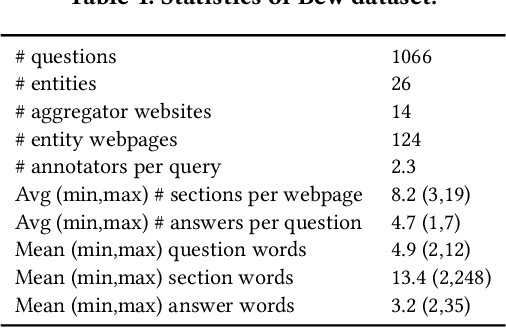
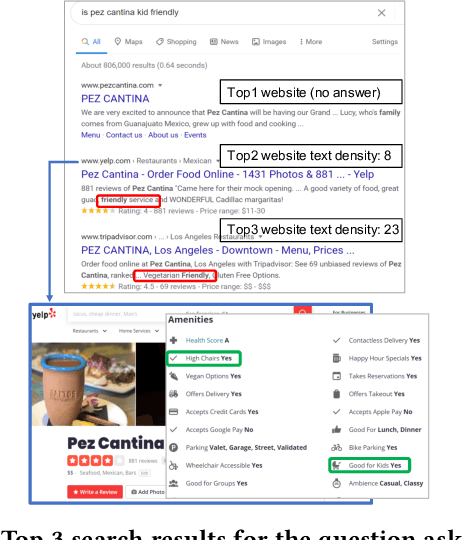
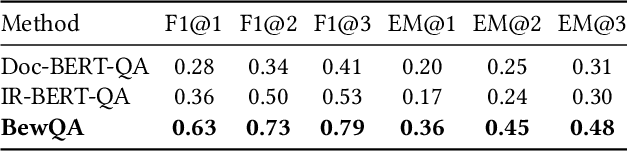
We present BewQA, a system specifically designed to answer a class of questions that we call Bew questions. Bew questions are related to businesses/services such as restaurants, hotels, and movie theaters; for example, "Until what time is happy hour?". These questions are challenging to answer because the answers are found in open-domain Web, are present in short sentences without surrounding context, and are dynamic since the webpage information can be updated frequently. Under these conditions, existing QA systems perform poorly. We present a practical approach, called BewQA, that can answer Bew queries by mining a template of the business-related webpages and using the template to guide the search. We show how we can extract the template automatically by leveraging aggregator websites that aggregate information about business entities in a domain (e.g., restaurants). We answer a given question by identifying the section from the extracted template that is most likely to contain the answer. By doing so we can extract the answers even when the answer span does not have sufficient context. Importantly, BewQA does not require any training. We crowdsource a new dataset of 1066 Bew questions and ground-truth answers in the restaurant domain. Compared to state-of-the-art QA models, BewQA has a 27 percent point improvement in F1 score. Compared to a commercial search engine, BewQA answered correctly 29% more Bew questions.