 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJam-ALT: A Formatting-Aware Lyrics Transcription Benchmark
Nov 23, 2023



Current automatic lyrics transcription (ALT) benchmarks focus exclusively on word content and ignore the finer nuances of written lyrics including formatting and punctuation, which leads to a potential misalignment with the creative products of musicians and songwriters as well as listeners' experiences. For example, line breaks are important in conveying information about rhythm, emotional emphasis, rhyme, and high-level structure. To address this issue, we introduce Jam-ALT, a new lyrics transcription benchmark based on the JamendoLyrics dataset. Our contribution is twofold. Firstly, a complete revision of the transcripts, geared specifically towards ALT evaluation by following a newly created annotation guide that unifies the music industry's guidelines, covering aspects such as punctuation, line breaks, spelling, background vocals, and non-word sounds. Secondly, a suite of evaluation metrics designed, unlike the traditional word error rate, to capture such phenomena. We hope that the proposed benchmark contributes to the ALT task, enabling more precise and reliable assessments of transcription systems and enhancing the user experience in lyrics applications such as subtitle renderings for live captioning or karaoke.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023



This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.
Music Demixing Challenge at ISMIR 2021
Aug 31, 2021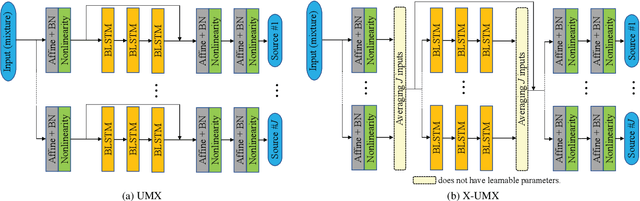
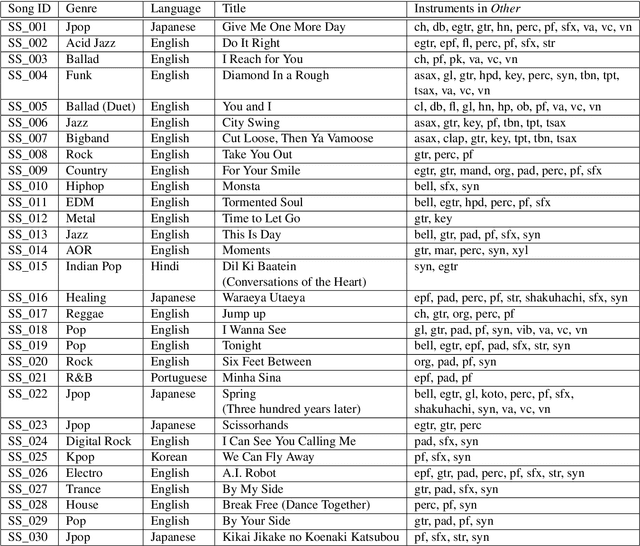
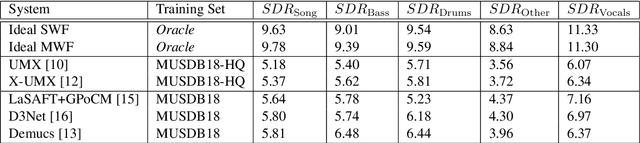
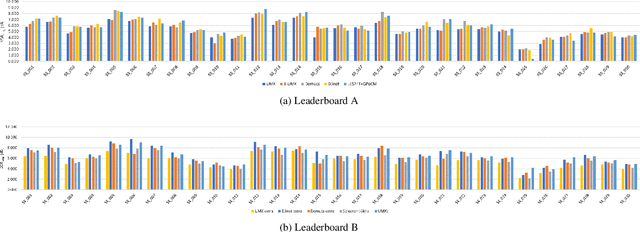
Music source separation has been intensively studied in the last decade and tremendous progress with the advent of deep learning could be observed. Evaluation campaigns such as MIREX or SiSEC connected state-of-the-art models and corresponding papers, which can help researchers integrate the best practices into their models. In recent years, however, it has become increasingly difficult to measure real-world performance as the music separation community had to rely on a limited amount of test data and was biased towards specific genres and mixing styles. To address these issues, we designed the Music Demixing (MDX) Challenge on a crowd-based machine learning competition platform where the task is to separate stereo songs into four instrument stems (Vocals, Drums, Bass, Other). The main differences compared with the past challenges are 1) the competition is designed to more easily allow machine learning practitioners from other disciplines to participate and 2) evaluation is done on a hidden test set created by music professionals dedicated exclusively to the challenge to assure the transparency of the challenge, i.e., the test set is not included in the training set. In this paper, we provide the details of the datasets, baselines, evaluation metrics, evaluation results, and technical challenges for future competitions.