 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSER: Communication-efficient SGD with Error Reset
Jul 29, 2020
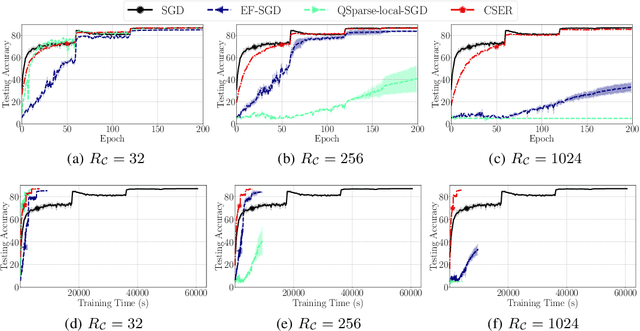

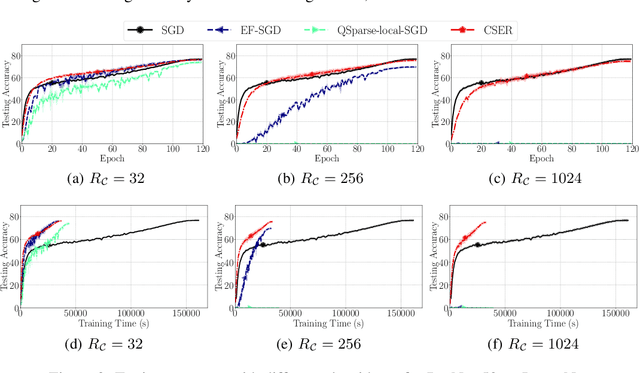
The scalability of Distributed Stochastic Gradient Descent (SGD) is today limited by communication bottlenecks. We propose a novel SGD variant: Communication-efficient SGD with Error Reset, or CSER. The key idea in CSER is first a new technique called "error reset" that adapts arbitrary compressors for SGD, producing bifurcated local models with periodic reset of resulting local residual errors. Second we introduce partial synchronization for both the gradients and the models, leveraging advantages from them. We prove the convergence of CSER for smooth non-convex problems. Empirical results show that when combined with highly aggressive compressors, the CSER algorithms: i) cause no loss of accuracy, and ii) accelerate the training by nearly $10\times$ for CIFAR-100, and by $4.5\times$ for ImageNet.
Bayesian Coresets: An Optimization Perspective
Jul 01, 2020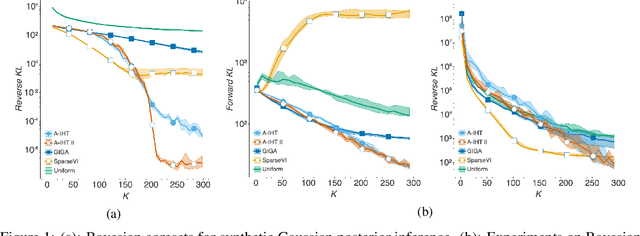
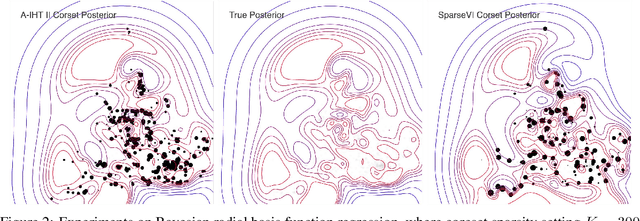
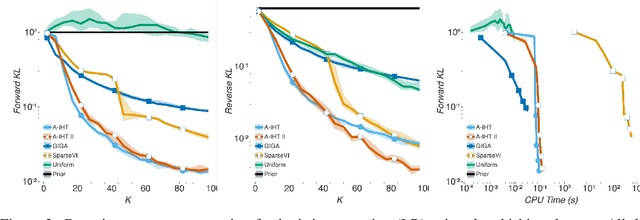
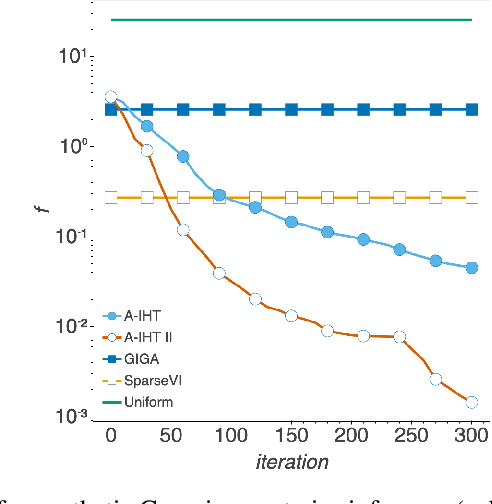
Bayesian coresets have emerged as a promising approach for implementing scalable Bayesian inference. The Bayesian coreset problem involves selecting a (weighted) subset of the data samples, such that posterior inference using the selected subset closely approximates posterior inference using the full dataset. This manuscript revisits Bayesian coresets through the lens of sparsity constrained optimization. Leveraging recent advances in accelerated optimization methods, we propose and analyze a novel algorithm for coreset selection. We provide explicit convergence rate guarantees and present an empirical evaluation on a variety of benchmark datasets to highlight our proposed algorithm's superior performance compared to state of the art on speed and accuracy.
Does Adversarial Transferability Indicate Knowledge Transferability?
Jun 25, 2020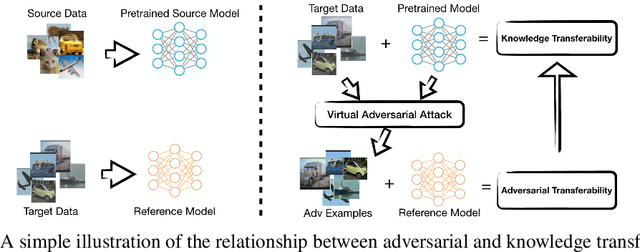
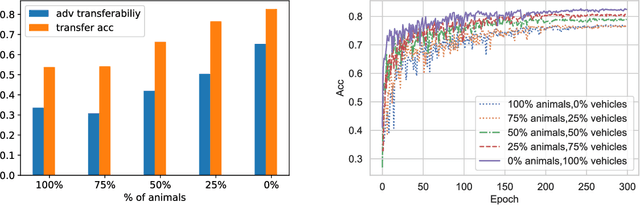
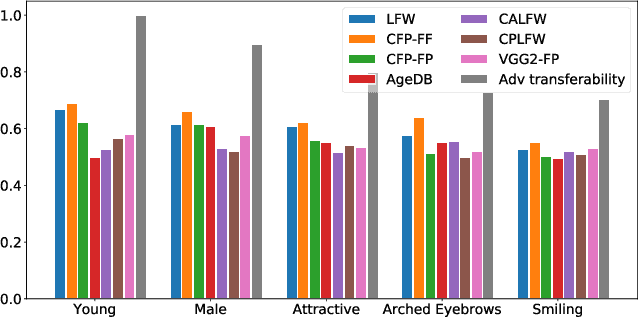
Despite the immense success that deep neural networks (DNNs) have achieved, adversarial examples, which are perturbed inputs that aim to mislead DNNs to make mistakes have recently led to great concern. On the other hand, adversarial examples exhibit interesting phenomena, such as adversarial transferability. DNNs also exhibit knowledge transfer, which is critical to improving learning efficiency and learning in domains that lack high-quality training data. In this paper, we aim to turn the existence and pervasiveness of adversarial examples into an advantage. Given that adversarial transferability is easy to measure while it can be challenging to estimate the effectiveness of knowledge transfer, does adversarial transferability indicate knowledge transferability? We first theoretically analyze the relationship between adversarial transferability and knowledge transferability and outline easily checkable sufficient conditions that identify when adversarial transferability indicates knowledge transferability. In particular, we show that composition with an affine function is sufficient to reduce the difference between two models when adversarial transferability between them is high. We provide empirical evaluation for different transfer learning scenarios on diverse datasets, including CIFAR-10, STL-10, CelebA, and Taskonomy-data - showing a strong positive correlation between the adversarial transferability and knowledge transferability, thus illustrating that our theoretical insights are predictive of practice.
Fair Performance Metric Elicitation
Jun 23, 2020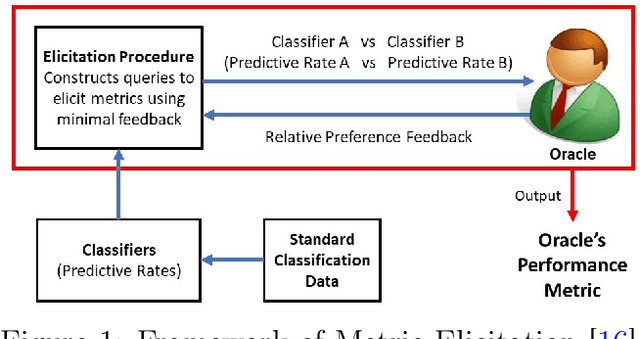


What is a fair performance metric? We consider the choice of fairness metrics through the lens of metric elicitation -- a principled framework for selecting performance metrics that best reflect implicit preferences. The use of metric elicitation enables a practitioner to tune the performance and fairness metrics to the task, context, and population at hand. Specifically, we propose a novel strategy to elicit fair performance metrics for multiclass classification problems with multiple sensitive groups that also includes selecting the trade-off between performance and fairness. The proposed elicitation strategy requires only relative preference feedback and is robust to both finite sample and feedback noise.
Rich-Item Recommendations for Rich-Users via GCNN: Exploiting Dynamic and Static Side Information
Jan 28, 2020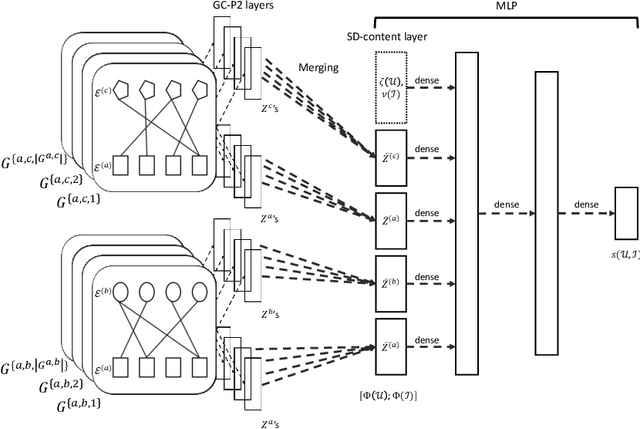
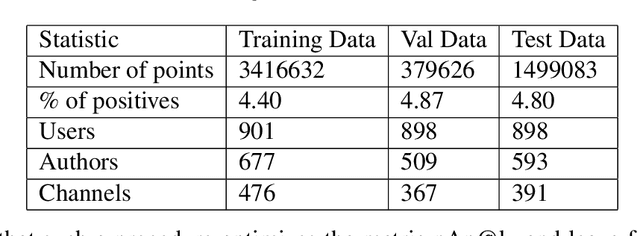
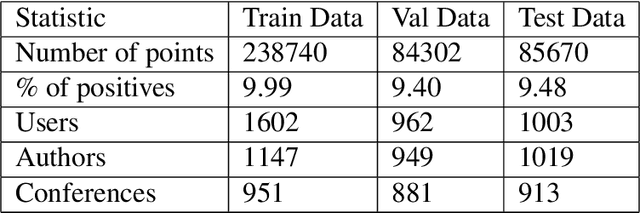
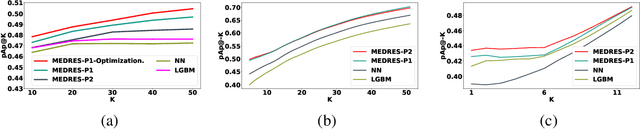
We study the standard problem of recommending relevant items to users; a user is someone who seeks recommendation, and an item is something which should be recommended. In today's modern world, both users and items are 'rich' multi-faceted entities but existing literature, for ease of modeling, views these facets in silos. In this paper, we provide a general formulation of the recommendation problem that captures the complexities of modern systems and encompasses most of the existing recommendation system formulations. In our formulation, each user and item is modeled via a set of static entities and a dynamic component. The relationships between entities are captured by multiple weighted bipartite graphs. To effectively exploit these complex interactions for recommendations, we propose MEDRES -- a multiple graph-CNN based novel deep-learning architecture. In addition, we propose a new metric, pAp@k, that is critical for a variety of classification+ranking scenarios. We also provide an optimization algorithm that directly optimizes the proposed metric and trains MEDRES in an end-to-end framework. We demonstrate the effectiveness of our method on two benchmarks as well as on a message recommendation system deployed in Microsoft Teams where it improves upon the existing production-grade model by 3%.
Towards A Controllable Disentanglement Network
Jan 22, 2020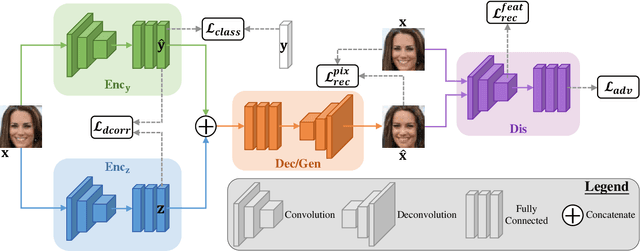
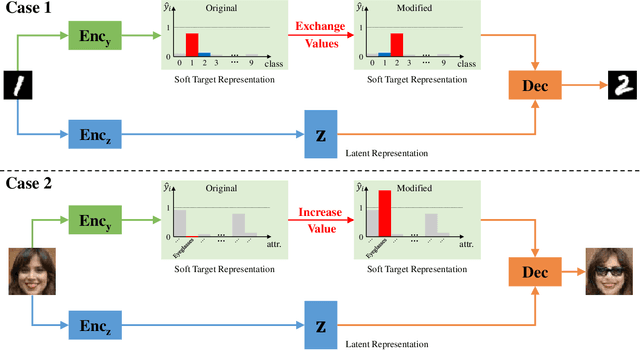


This paper addresses two crucial problems of learning disentangled image representations, namely controlling the degree of disentanglement during image editing, and balancing the disentanglement strength and the reconstruction quality. To encourage disentanglement, we devise a distance covariance based decorrelation regularization. Further, for the reconstruction step, our model leverages a soft target representation combined with the latent image code. By exploring the real-valued space of the soft target representation, we are able to synthesize novel images with the designated properties. To improve the perceptual quality of images generated by autoencoder (AE)-based models, we extend the encoder-decoder architecture with the generative adversarial network (GAN) by collapsing the AE decoder and the GAN generator into one. We also design a classification based protocol to quantitatively evaluate the disentanglement strength of our model. Experimental results showcase the benefits of the proposed model.
Learning Controllable Disentangled Representations with Decorrelation Regularization
Dec 25, 2019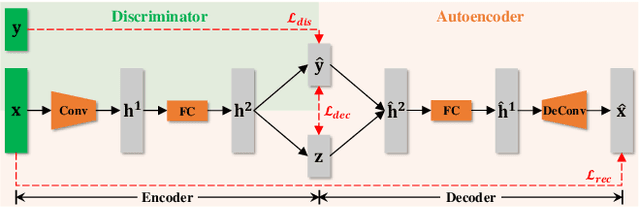
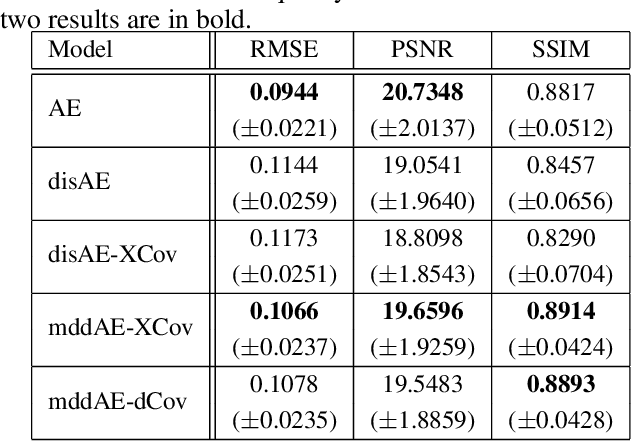
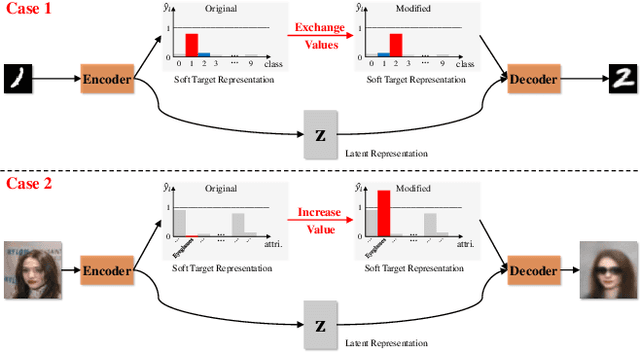
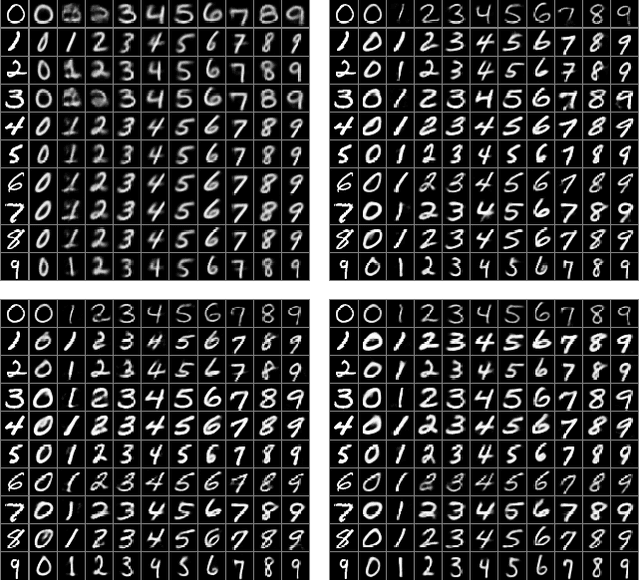
A crucial problem in learning disentangled image representations is controlling the degree of disentanglement during image editing, while preserving the identity of objects. In this work, we propose a simple yet effective model with the encoder-decoder architecture to address this challenge. To encourage disentanglement, we devise a distance covariance based decorrelation regularization. Further, for the reconstruction step, our model leverages a soft target representation combined with the latent image code. By exploiting the real-valued space of the soft target representations, we are able to synthesize novel images with the designated properties. We also design a classification based protocol to quantitatively evaluate the disentanglement strength of our model. Experimental results show that the proposed model competently disentangles factors of variation, and is able to manipulate face images to synthesize the desired attributes.
Local AdaAlter: Communication-Efficient Stochastic Gradient Descent with Adaptive Learning Rates
Nov 20, 2019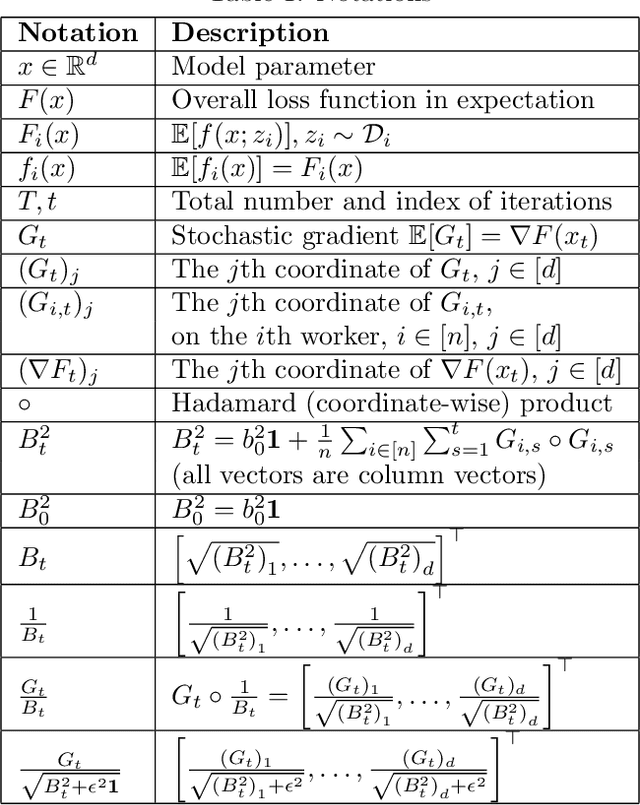
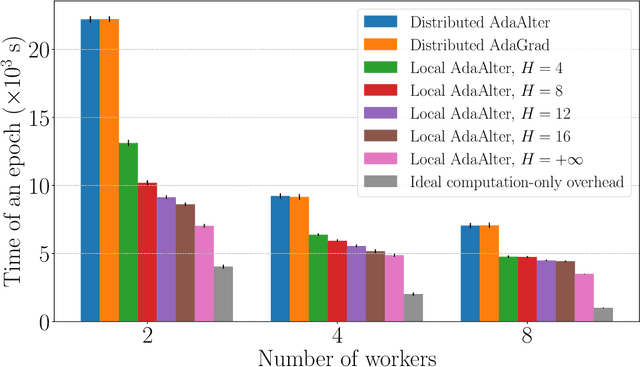
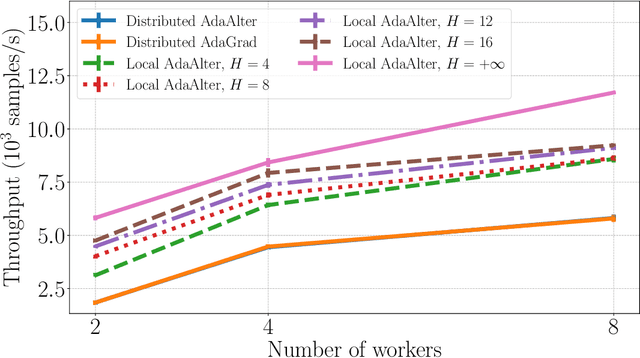
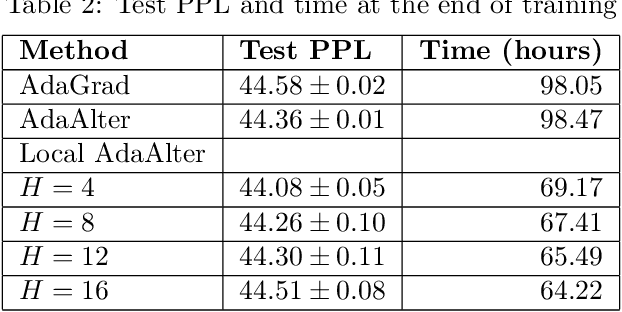
Recent years have witnessed the growth of large-scale distributed machine learning algorithms -- specifically designed to accelerate model training by distributing computation across multiple machines. When scaling distributed training in this way, the communication overhead is often the bottleneck. In this paper, we study the local distributed Stochastic Gradient Descent~(SGD) algorithm, which reduces the communication overhead by decreasing the frequency of synchronization. While SGD with adaptive learning rates is a widely adopted strategy for training neural networks, it remains unknown how to implement adaptive learning rates in local SGD. To this end, we propose a novel SGD variant with reduced communication and adaptive learning rates, with provable convergence. Empirical results show that the proposed algorithm has fast convergence and efficiently reduces the communication overhead.
Learning Sparse Distributions using Iterative Hard Thresholding
Nov 07, 2019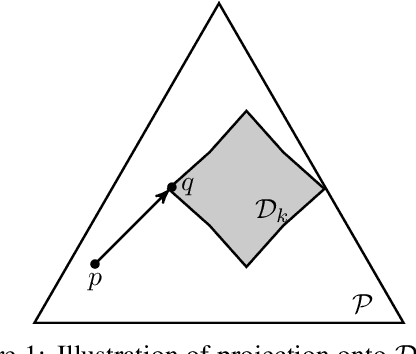
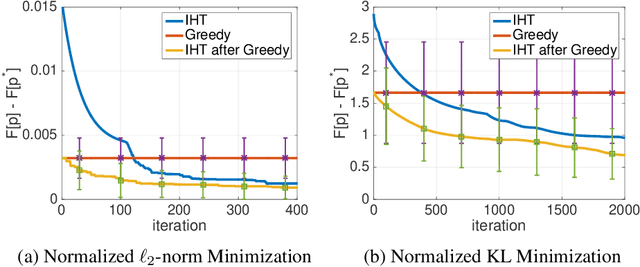
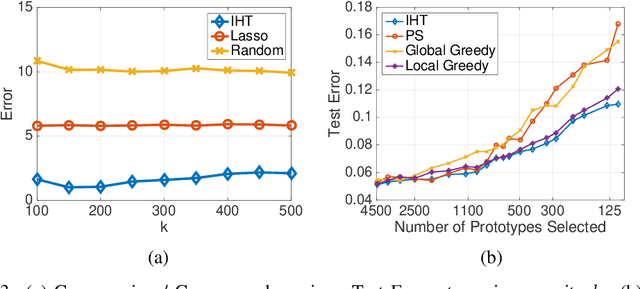
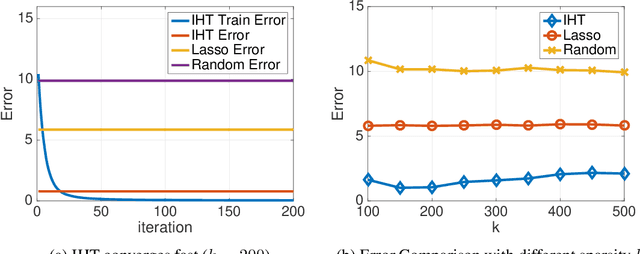
Iterative hard thresholding (IHT) is a projected gradient descent algorithm, known to achieve state of the art performance for a wide range of structured estimation problems, such as sparse inference. In this work, we consider IHT as a solution to the problem of learning sparse discrete distributions. We study the hardness of using IHT on the space of measures. As a practical alternative, we propose a greedy approximate projection which simultaneously captures appropriate notions of sparsity in distributions, while satisfying the simplex constraint, and investigate the convergence behavior of the resulting procedure in various settings. Our results show, both in theory and practice, that IHT can achieve state of the art results for learning sparse distributions.
Consistent Classification with Generalized Metrics
Aug 24, 2019
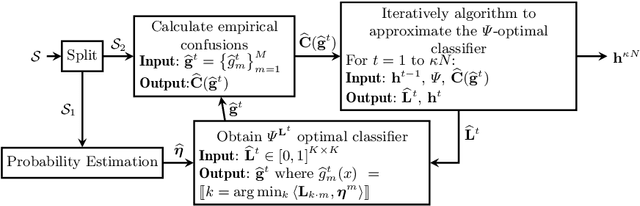
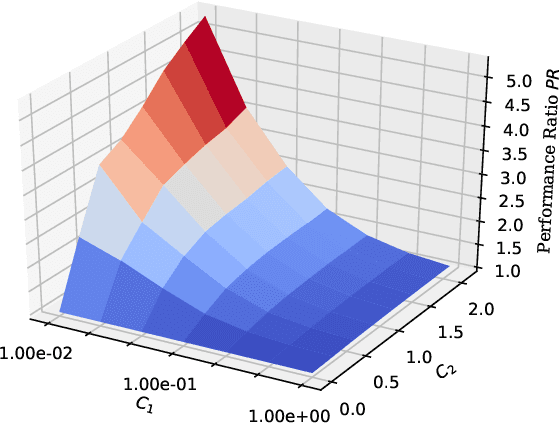
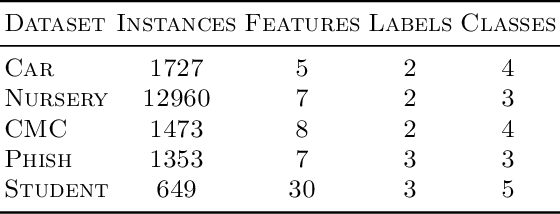
We propose a framework for constructing and analyzing multiclass and multioutput classification metrics, i.e., involving multiple, possibly correlated multiclass labels. Our analysis reveals novel insights on the geometry of feasible confusion tensors -- including necessary and sufficient conditions for the equivalence between optimizing an arbitrary non-decomposable metric and learning a weighted classifier. Further, we analyze averaging methodologies commonly used to compute multioutput metrics and characterize the corresponding Bayes optimal classifiers. We show that the plug-in estimator based on this characterization is consistent and is easily implemented as a post-processing rule. Empirical results on synthetic and benchmark datasets support the theoretical findings.