 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Coresets: An Optimization Perspective
Jul 01, 2020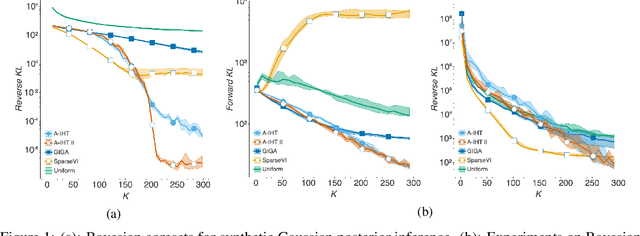
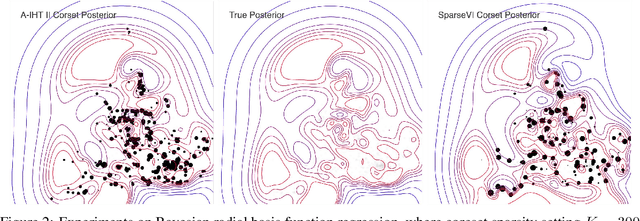
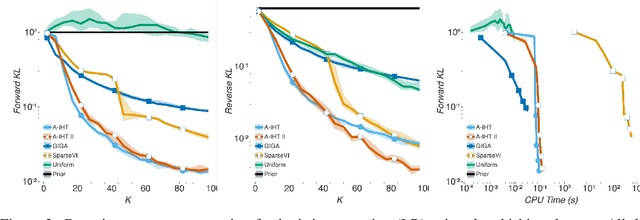
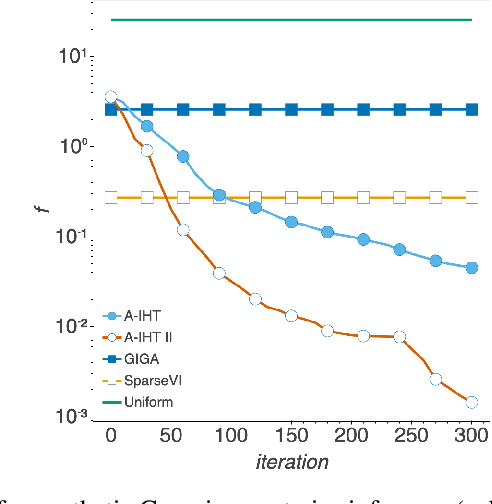
Bayesian coresets have emerged as a promising approach for implementing scalable Bayesian inference. The Bayesian coreset problem involves selecting a (weighted) subset of the data samples, such that posterior inference using the selected subset closely approximates posterior inference using the full dataset. This manuscript revisits Bayesian coresets through the lens of sparsity constrained optimization. Leveraging recent advances in accelerated optimization methods, we propose and analyze a novel algorithm for coreset selection. We provide explicit convergence rate guarantees and present an empirical evaluation on a variety of benchmark datasets to highlight our proposed algorithm's superior performance compared to state of the art on speed and accuracy.
Does Adversarial Transferability Indicate Knowledge Transferability?
Jun 25, 2020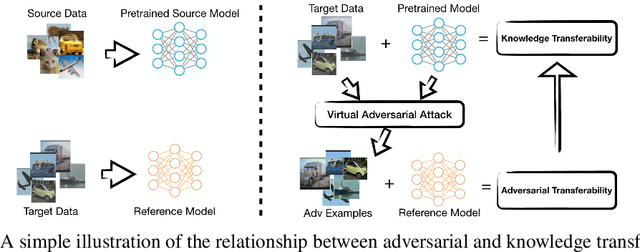
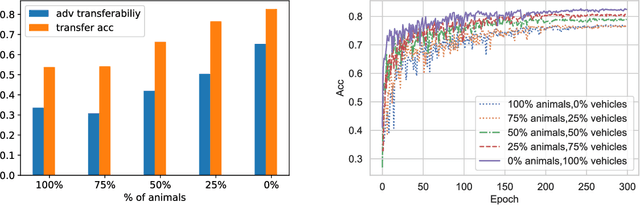
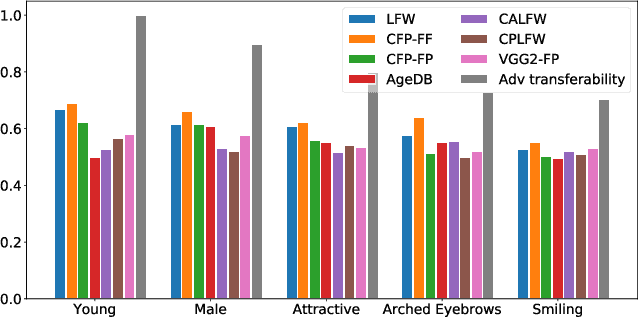
Despite the immense success that deep neural networks (DNNs) have achieved, adversarial examples, which are perturbed inputs that aim to mislead DNNs to make mistakes have recently led to great concern. On the other hand, adversarial examples exhibit interesting phenomena, such as adversarial transferability. DNNs also exhibit knowledge transfer, which is critical to improving learning efficiency and learning in domains that lack high-quality training data. In this paper, we aim to turn the existence and pervasiveness of adversarial examples into an advantage. Given that adversarial transferability is easy to measure while it can be challenging to estimate the effectiveness of knowledge transfer, does adversarial transferability indicate knowledge transferability? We first theoretically analyze the relationship between adversarial transferability and knowledge transferability and outline easily checkable sufficient conditions that identify when adversarial transferability indicates knowledge transferability. In particular, we show that composition with an affine function is sufficient to reduce the difference between two models when adversarial transferability between them is high. We provide empirical evaluation for different transfer learning scenarios on diverse datasets, including CIFAR-10, STL-10, CelebA, and Taskonomy-data - showing a strong positive correlation between the adversarial transferability and knowledge transferability, thus illustrating that our theoretical insights are predictive of practice.
Learning Sparse Distributions using Iterative Hard Thresholding
Nov 07, 2019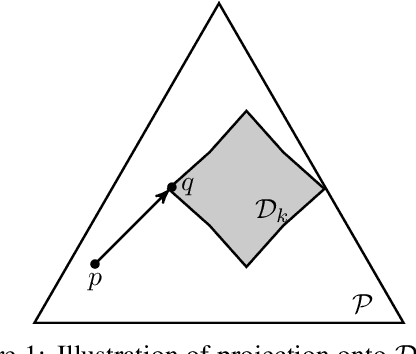
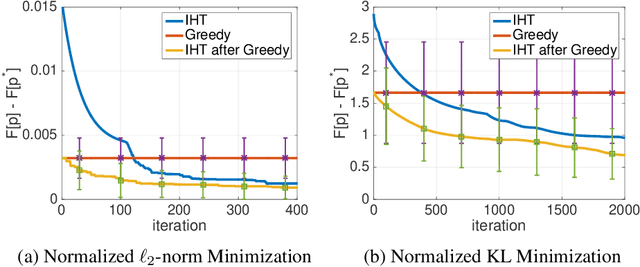
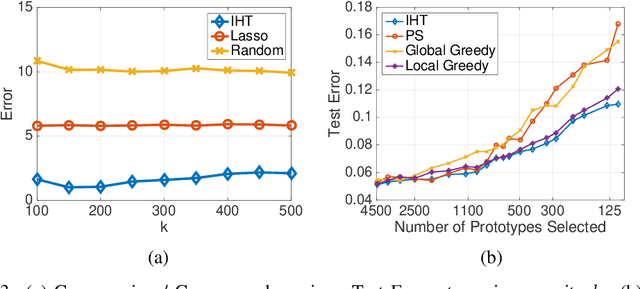
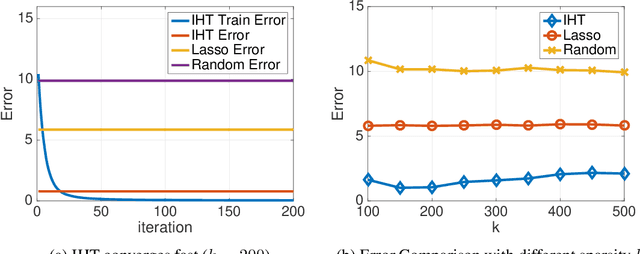
Iterative hard thresholding (IHT) is a projected gradient descent algorithm, known to achieve state of the art performance for a wide range of structured estimation problems, such as sparse inference. In this work, we consider IHT as a solution to the problem of learning sparse discrete distributions. We study the hardness of using IHT on the space of measures. As a practical alternative, we propose a greedy approximate projection which simultaneously captures appropriate notions of sparsity in distributions, while satisfying the simplex constraint, and investigate the convergence behavior of the resulting procedure in various settings. Our results show, both in theory and practice, that IHT can achieve state of the art results for learning sparse distributions.