 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazy-MDPs: Towards Interpretable Reinforcement Learning by Learning When to Act
Mar 16, 2022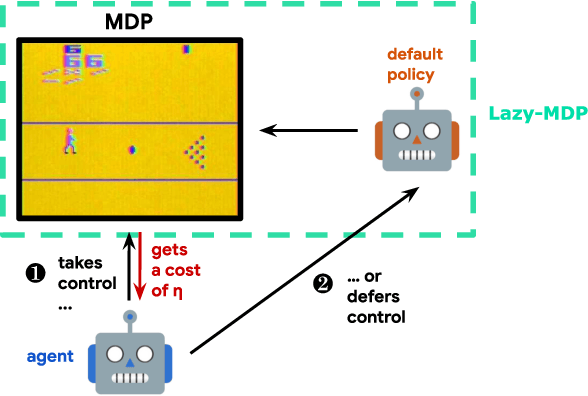
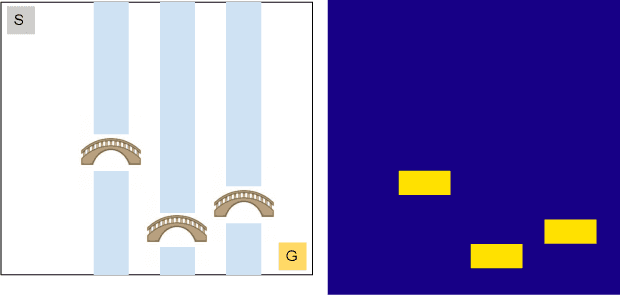
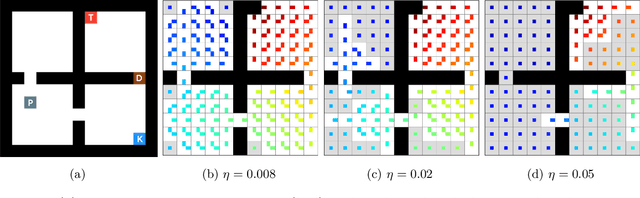
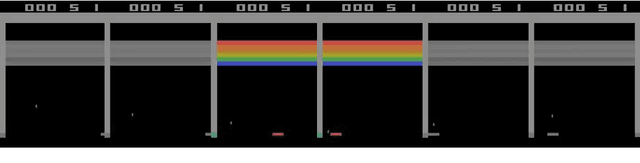
Traditionally, Reinforcement Learning (RL) aims at deciding how to act optimally for an artificial agent. We argue that deciding when to act is equally important. As humans, we drift from default, instinctive or memorized behaviors to focused, thought-out behaviors when required by the situation. To enhance RL agents with this aptitude, we propose to augment the standard Markov Decision Process and make a new mode of action available: being lazy, which defers decision-making to a default policy. In addition, we penalize non-lazy actions in order to encourage minimal effort and have agents focus on critical decisions only. We name the resulting formalism lazy-MDPs. We study the theoretical properties of lazy-MDPs, expressing value functions and characterizing optimal solutions. Then we empirically demonstrate that policies learned in lazy-MDPs generally come with a form of interpretability: by construction, they show us the states where the agent takes control over the default policy. We deem those states and corresponding actions important since they explain the difference in performance between the default and the new, lazy policy. With suboptimal policies as default (pretrained or random), we observe that agents are able to get competitive performance in Atari games while only taking control in a limited subset of states.
* AAMAS 2022 (14 pages extended version, added Sec. 7.4 and appendix K)
RLDS: an Ecosystem to Generate, Share and Use Datasets in Reinforcement Learning
Nov 04, 2021
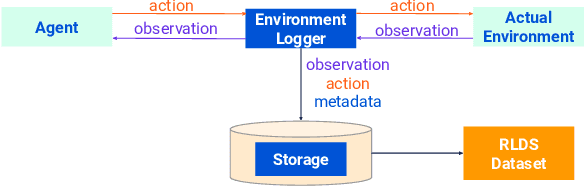

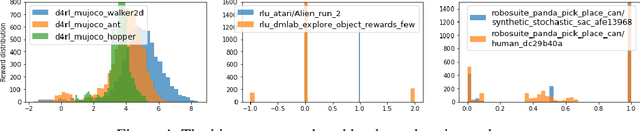
We introduce RLDS (Reinforcement Learning Datasets), an ecosystem for recording, replaying, manipulating, annotating and sharing data in the context of Sequential Decision Making (SDM) including Reinforcement Learning (RL), Learning from Demonstrations, Offline RL or Imitation Learning. RLDS enables not only reproducibility of existing research and easy generation of new datasets, but also accelerates novel research. By providing a standard and lossless format of datasets it enables to quickly test new algorithms on a wider range of tasks. The RLDS ecosystem makes it easy to share datasets without any loss of information and to be agnostic to the underlying original format when applying various data processing pipelines to large collections of datasets. Besides, RLDS provides tools for collecting data generated by either synthetic agents or humans, as well as for inspecting and manipulating the collected data. Ultimately, integration with TFDS facilitates the sharing of RL datasets with the research community.
Continuous Control with Action Quantization from Demonstrations
Oct 19, 2021
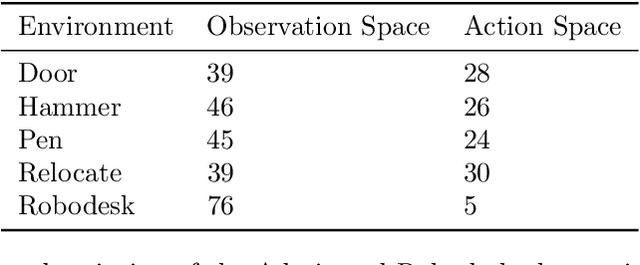

In Reinforcement Learning (RL), discrete actions, as opposed to continuous actions, result in less complex exploration problems and the immediate computation of the maximum of the action-value function which is central to dynamic programming-based methods. In this paper, we propose a novel method: Action Quantization from Demonstrations (AQuaDem) to learn a discretization of continuous action spaces by leveraging the priors of demonstrations. This dramatically reduces the exploration problem, since the actions faced by the agent not only are in a finite number but also are plausible in light of the demonstrator's behavior. By discretizing the action space we can apply any discrete action deep RL algorithm to the continuous control problem. We evaluate the proposed method on three different setups: RL with demonstrations, RL with play data --demonstrations of a human playing in an environment but not solving any specific task-- and Imitation Learning. For all three setups, we only consider human data, which is more challenging than synthetic data. We found that AQuaDem consistently outperforms state-of-the-art continuous control methods, both in terms of performance and sample efficiency. We provide visualizations and videos in the paper's website: https://google-research.github.io/aquadem.
Generalization in Mean Field Games by Learning Master Policies
Sep 20, 2021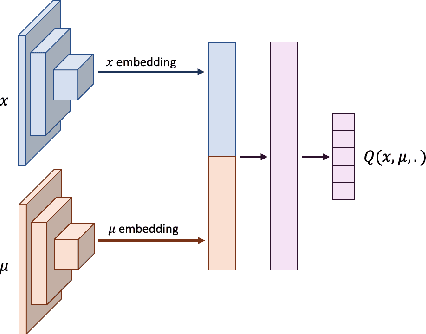
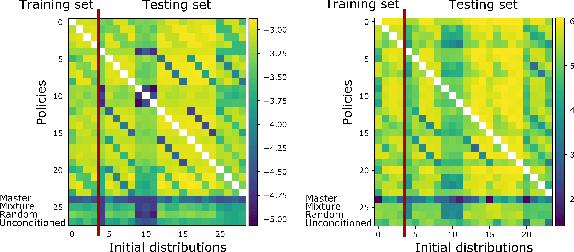

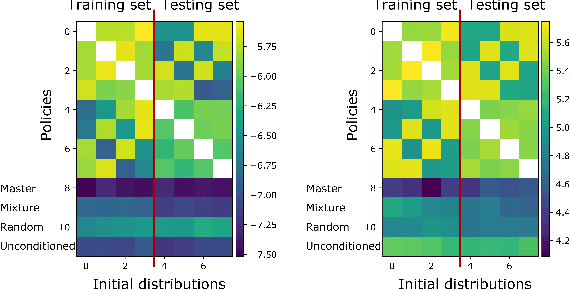
Mean Field Games (MFGs) can potentially scale multi-agent systems to extremely large populations of agents. Yet, most of the literature assumes a single initial distribution for the agents, which limits the practical applications of MFGs. Machine Learning has the potential to solve a wider diversity of MFG problems thanks to generalizations capacities. We study how to leverage these generalization properties to learn policies enabling a typical agent to behave optimally against any population distribution. In reference to the Master equation in MFGs, we coin the term ``Master policies'' to describe them and we prove that a single Master policy provides a Nash equilibrium, whatever the initial distribution. We propose a method to learn such Master policies. Our approach relies on three ingredients: adding the current population distribution as part of the observation, approximating Master policies with neural networks, and training via Reinforcement Learning and Fictitious Play. We illustrate on numerical examples not only the efficiency of the learned Master policy but also its generalization capabilities beyond the distributions used for training.
Learning Natural Language Generation from Scratch
Sep 20, 2021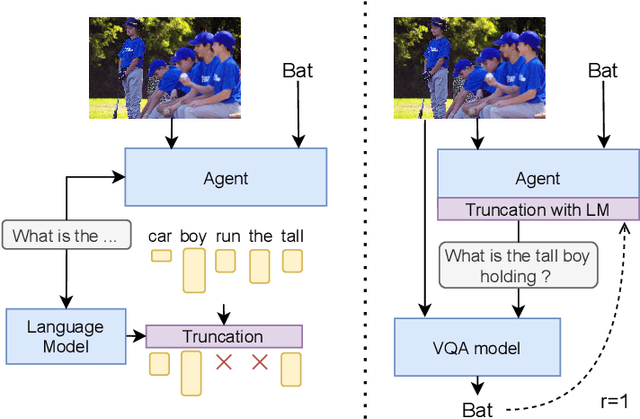
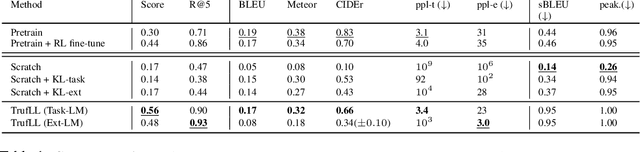

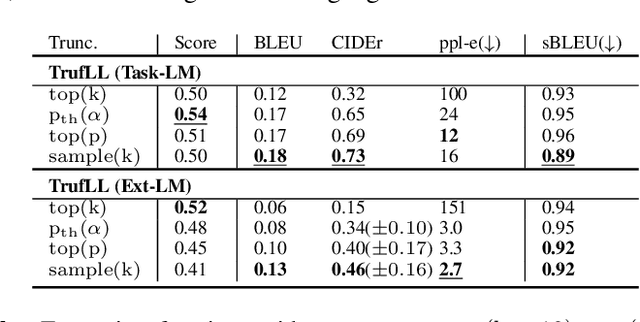
This paper introduces TRUncated ReinForcement Learning for Language (TrufLL), an original ap-proach to train conditional language models from scratch by only using reinforcement learning (RL). AsRL methods unsuccessfully scale to large action spaces, we dynamically truncate the vocabulary spaceusing a generic language model. TrufLL thus enables to train a language agent by solely interacting withits environment without any task-specific prior knowledge; it is only guided with a task-agnostic languagemodel. Interestingly, this approach avoids the dependency to labelled datasets and inherently reduces pre-trained policy flaws such as language or exposure biases. We evaluate TrufLL on two visual questiongeneration tasks, for which we report positive results over performance and language metrics, which wethen corroborate with a human evaluation. To our knowledge, it is the first approach that successfullylearns a language generation policy (almost) from scratch.
Implicitly Regularized RL with Implicit Q-Values
Aug 16, 2021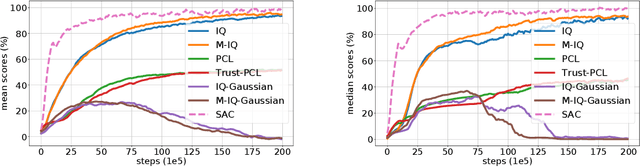
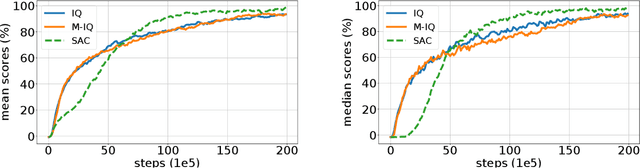

The $Q$-function is a central quantity in many Reinforcement Learning (RL) algorithms for which RL agents behave following a (soft)-greedy policy w.r.t. to $Q$. It is a powerful tool that allows action selection without a model of the environment and even without explicitly modeling the policy. Yet, this scheme can only be used in discrete action tasks, with small numbers of actions, as the softmax cannot be computed exactly otherwise. Especially the usage of function approximation, to deal with continuous action spaces in modern actor-critic architectures, intrinsically prevents the exact computation of a softmax. We propose to alleviate this issue by parametrizing the $Q$-function implicitly, as the sum of a log-policy and of a value function. We use the resulting parametrization to derive a practical off-policy deep RL algorithm, suitable for large action spaces, and that enforces the softmax relation between the policy and the $Q$-value. We provide a theoretical analysis of our algorithm: from an Approximate Dynamic Programming perspective, we show its equivalence to a regularized version of value iteration, accounting for both entropy and Kullback-Leibler regularization, and that enjoys beneficial error propagation results. We then evaluate our algorithm on classic control tasks, where its results compete with state-of-the-art methods.
Offline Reinforcement Learning as Anti-Exploration
Jun 11, 2021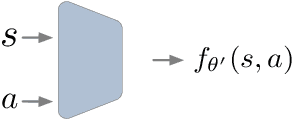
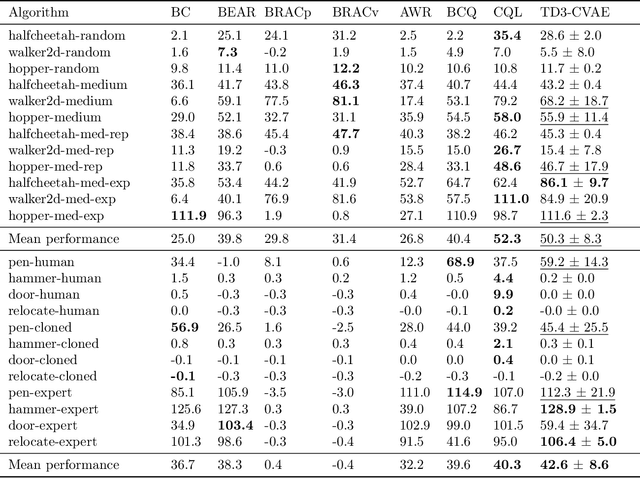
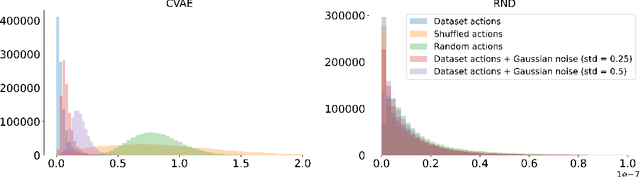
Offline Reinforcement Learning (RL) aims at learning an optimal control from a fixed dataset, without interactions with the system. An agent in this setting should avoid selecting actions whose consequences cannot be predicted from the data. This is the converse of exploration in RL, which favors such actions. We thus take inspiration from the literature on bonus-based exploration to design a new offline RL agent. The core idea is to subtract a prediction-based exploration bonus from the reward, instead of adding it for exploration. This allows the policy to stay close to the support of the dataset. We connect this approach to a more common regularization of the learned policy towards the data. Instantiated with a bonus based on the prediction error of a variational autoencoder, we show that our agent is competitive with the state of the art on a set of continuous control locomotion and manipulation tasks.
There Is No Turning Back: A Self-Supervised Approach for Reversibility-Aware Reinforcement Learning
Jun 09, 2021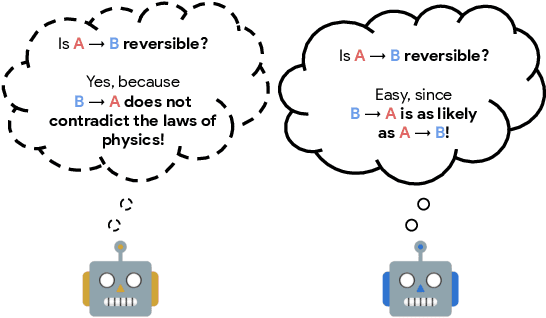
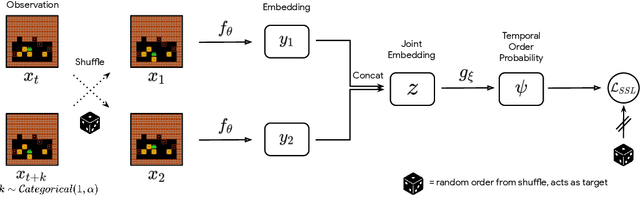
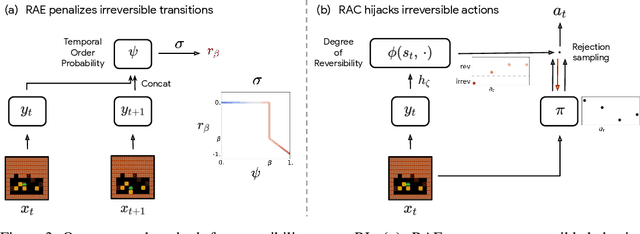
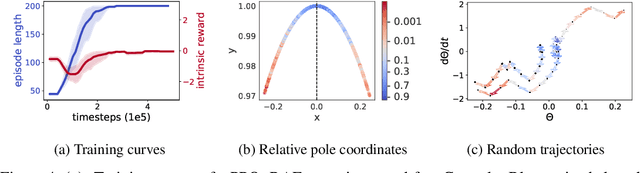
We propose to learn to distinguish reversible from irreversible actions for better informed decision-making in Reinforcement Learning (RL). From theoretical considerations, we show that approximate reversibility can be learned through a simple surrogate task: ranking randomly sampled trajectory events in chronological order. Intuitively, pairs of events that are always observed in the same order are likely to be separated by an irreversible sequence of actions. Conveniently, learning the temporal order of events can be done in a fully self-supervised way, which we use to estimate the reversibility of actions from experience, without any priors. We propose two different strategies that incorporate reversibility in RL agents, one strategy for exploration (RAE) and one strategy for control (RAC). We demonstrate the potential of reversibility-aware agents in several environments, including the challenging Sokoban game. In synthetic tasks, we show that we can learn control policies that never fail and reduce to zero the side-effects of interactions, even without access to the reward function.
Concave Utility Reinforcement Learning: the Mean-field Game viewpoint
Jun 09, 2021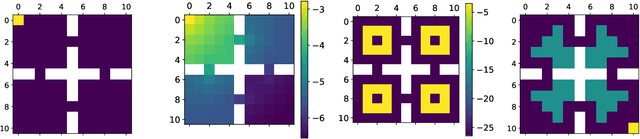
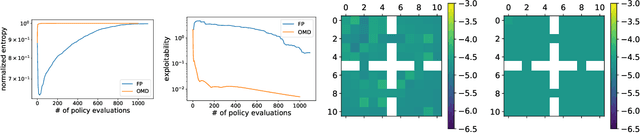
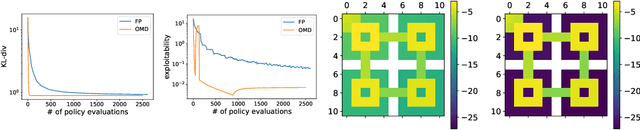

Concave Utility Reinforcement Learning (CURL) extends RL from linear to concave utilities in the occupancy measure induced by the agent's policy. This encompasses not only RL but also imitation learning and exploration, among others. Yet, this more general paradigm invalidates the classical Bellman equations, and calls for new algorithms. Mean-field Games (MFGs) are a continuous approximation of many-agent RL. They consider the limit case of a continuous distribution of identical agents, anonymous with symmetric interests, and reduce the problem to the study of a single representative agent in interaction with the full population. Our core contribution consists in showing that CURL is a subclass of MFGs. We think this important to bridge together both communities. It also allows to shed light on aspects of both fields: we show the equivalence between concavity in CURL and monotonicity in the associated MFG, between optimality conditions in CURL and Nash equilibrium in MFG, or that Fictitious Play (FP) for this class of MFGs is simply Frank-Wolfe, bringing the first convergence rate for discrete-time FP for MFGs. We also experimentally demonstrate that, using algorithms recently introduced for solving MFGs, we can address the CURL problem more efficiently.
What Matters for Adversarial Imitation Learning?
Jun 01, 2021

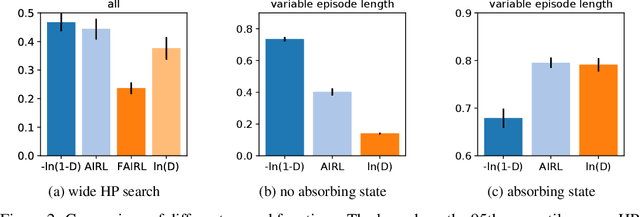

Adversarial imitation learning has become a popular framework for imitation in continuous control. Over the years, several variations of its components were proposed to enhance the performance of the learned policies as well as the sample complexity of the algorithm. In practice, these choices are rarely tested all together in rigorous empirical studies. It is therefore difficult to discuss and understand what choices, among the high-level algorithmic options as well as low-level implementation details, matter. To tackle this issue, we implement more than 50 of these choices in a generic adversarial imitation learning framework and investigate their impacts in a large-scale study (>500k trained agents) with both synthetic and human-generated demonstrations. While many of our findings confirm common practices, some of them are surprising or even contradict prior work. In particular, our results suggest that artificial demonstrations are not a good proxy for human data and that the very common practice of evaluating imitation algorithms only with synthetic demonstrations may lead to algorithms which perform poorly in the more realistic scenarios with human demonstrations.