 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Diffusion Models
May 30, 2022

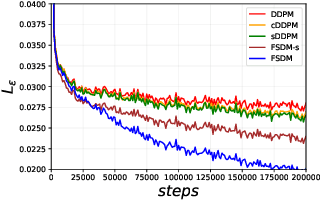
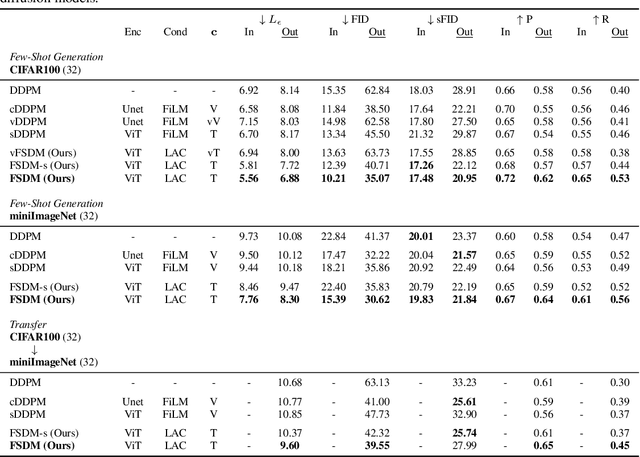
Denoising diffusion probabilistic models (DDPM) are powerful hierarchical latent variable models with remarkable sample generation quality and training stability. These properties can be attributed to parameter sharing in the generative hierarchy, as well as a parameter-free diffusion-based inference procedure. In this paper, we present Few-Shot Diffusion Models (FSDM), a framework for few-shot generation leveraging conditional DDPMs. FSDMs are trained to adapt the generative process conditioned on a small set of images from a given class by aggregating image patch information using a set-based Vision Transformer (ViT). At test time, the model is able to generate samples from previously unseen classes conditioned on as few as 5 samples from that class. We empirically show that FSDM can perform few-shot generation and transfer to new datasets. We benchmark variants of our method on complex vision datasets for few-shot learning and compare to unconditional and conditional DDPM baselines. Additionally, we show how conditioning the model on patch-based input set information improves training convergence.
Inductive Biases for Object-Centric Representations in the Presence of Complex Textures
Apr 26, 2022

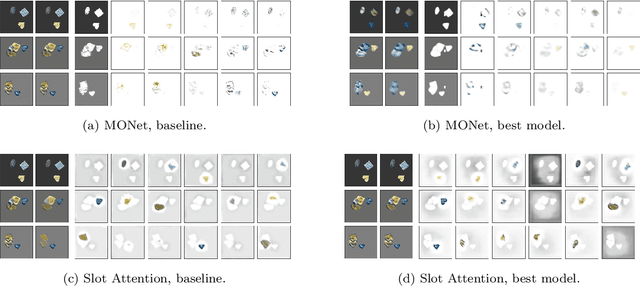
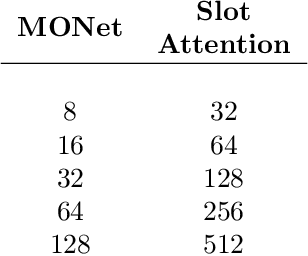
Understanding which inductive biases could be helpful for the unsupervised learning of object-centric representations of natural scenes is challenging. We use neural style transfer to generate datasets where objects have complex textures while still retaining ground-truth annotations. We find that methods that use a single module to reconstruct both the shape and visual appearance of each object learn more useful representations and achieve better object separation. In addition, we observe that adjusting the latent space size is not sufficient to improve segmentation performance. Finally, the downstream usefulness of the representations is significantly more strongly correlated with segmentation quality than with reconstruction accuracy.
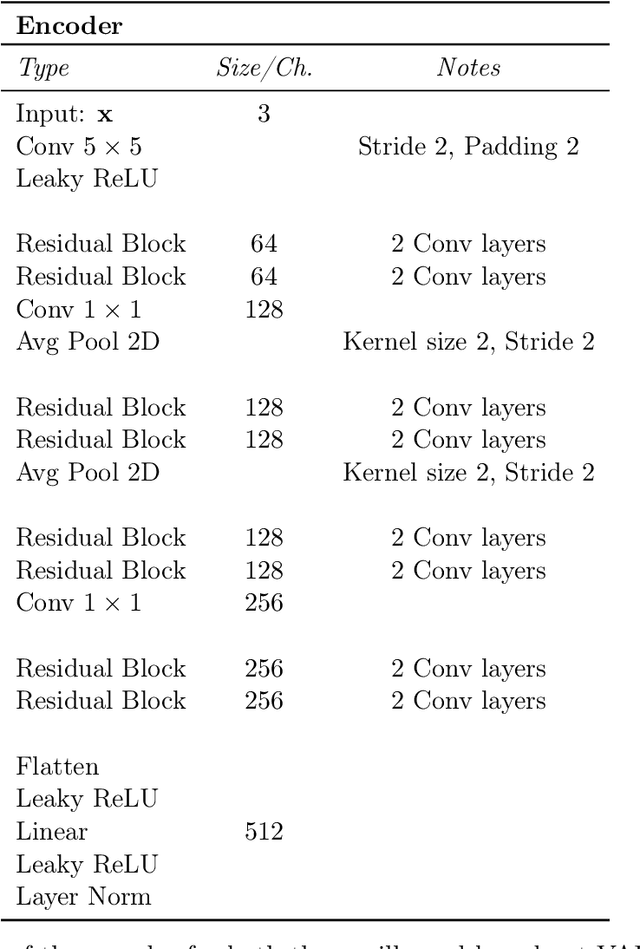
Image Super-Resolution With Deep Variational Autoencoders
Mar 17, 2022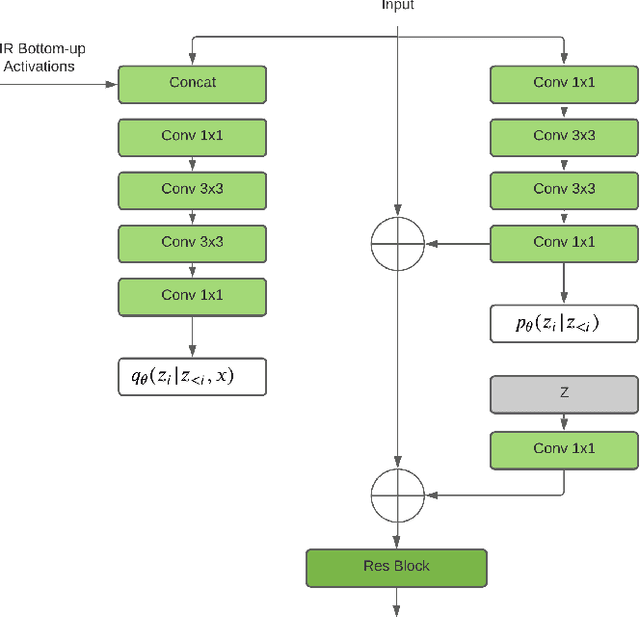
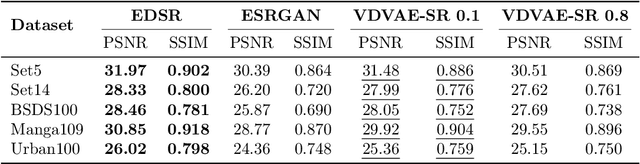
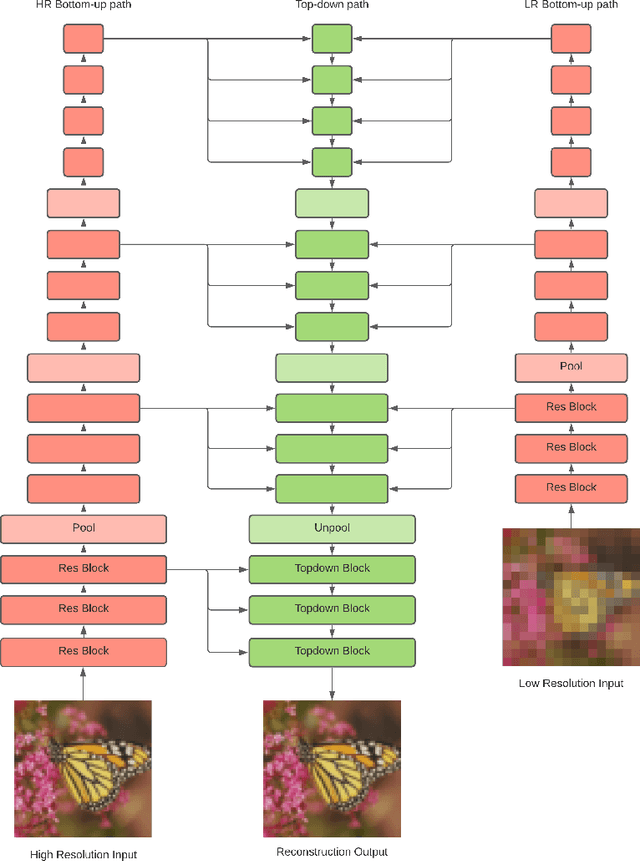
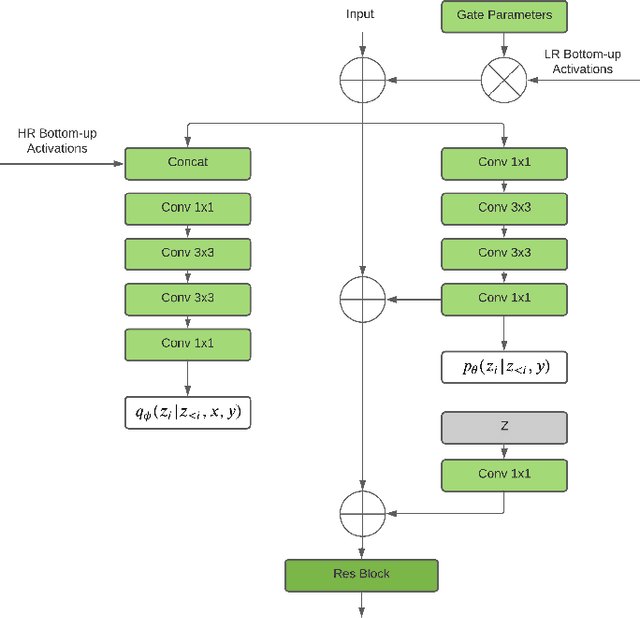
Image super-resolution (SR) techniques are used to generate a high-resolution image from a low-resolution image. Until now, deep generative models such as autoregressive models and Generative Adversarial Networks (GANs) have proven to be effective at modelling high-resolution images. Models based on Variational Autoencoders (VAEs) have often been criticized for their feeble generative performance, but with new advancements such as VDVAE (very deep VAE), there is now strong evidence that deep VAEs have the potential to outperform current state-of-the-art models for high-resolution image generation. In this paper, we introduce VDVAE-SR, a new model that aims to exploit the most recent deep VAE methodologies to improve upon image super-resolution using transfer learning on pretrained VDVAEs. Through qualitative and quantitative evaluations, we show that the proposed model is competitive with other state-of-the-art methods.
DermX: an end-to-end framework for explainable automated dermatological diagnosis
Feb 14, 2022

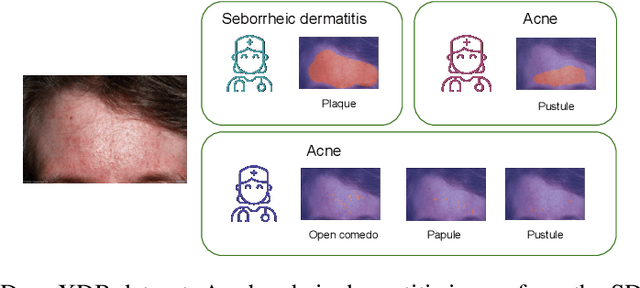
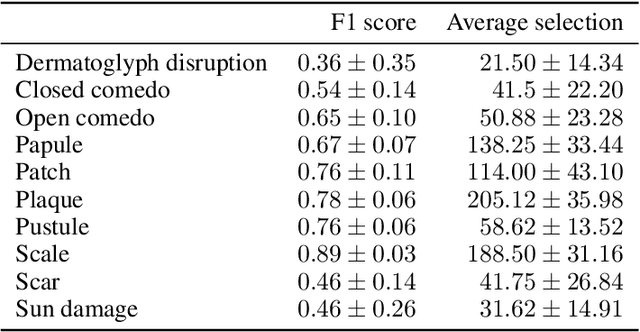
Dermatological diagnosis automation is essential in addressing the high prevalence of skin diseases and critical shortage of dermatologists. Despite approaching expert-level diagnosis performance, convolutional neural network (ConvNet) adoption in clinical practice is impeded by their limited explainability, and by subjective, expensive explainability validations. We introduce DermX and DermX+, an end-to-end framework for explainable automated dermatological diagnosis. DermX is a clinically-inspired explainable dermatological diagnosis ConvNet, trained using DermXDB, a 554 images dataset annotated by eight dermatologists with diagnoses and supporting explanations. DermX+ extends DermX with guided attention training for explanation attention maps. Both methods achieve near-expert diagnosis performance, with DermX, DermX+, and dermatologist F1 scores of 0.79, 0.79, and 0.87, respectively. We assess the explanation plausibility in terms of identification and localization, by comparing model-selected with dermatologist-selected explanations, and gradient-weighted class-activation maps with dermatologist explanation maps. Both DermX and DermX+ obtain an identification F1 score of 0.78. The localization F1 score is 0.39 for DermX and 0.35 for DermX+. Explanation faithfulness is assessed through contrasting samples, DermX obtaining 0.53 faithfulness and DermX+ 0.25. These results show that explainability does not necessarily come at the expense of predictive power, as our high-performance models provide both plausible and faithful explanations for their diagnoses.
Hierarchical Few-Shot Generative Models
Oct 23, 2021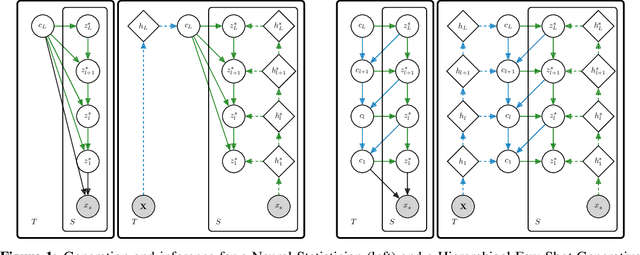
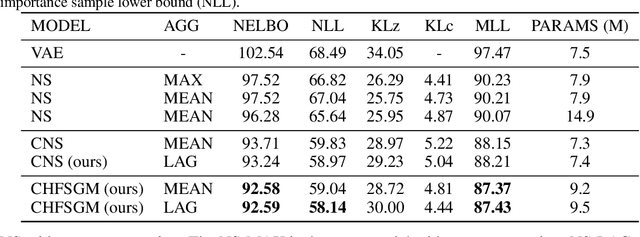
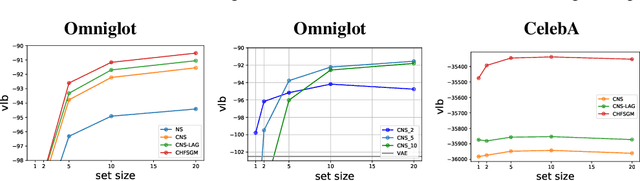
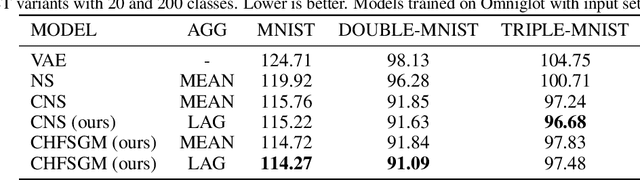
A few-shot generative model should be able to generate data from a distribution by only observing a limited set of examples. In few-shot learning the model is trained on data from many sets from different distributions sharing some underlying properties such as sets of characters from different alphabets or sets of images of different type objects. We study a latent variables approach that extends the Neural Statistician to a fully hierarchical approach with an attention-based point to set-level aggregation. We extend the previous work to iterative data sampling, likelihood-based model comparison, and adaptation-free out of distribution generalization. Our results show that the hierarchical formulation better captures the intrinsic variability within the sets in the small data regime. With this work we generalize deep latent variable approaches to few-shot learning, taking a step towards large-scale few-shot generation with a formulation that readily can work with current state-of-the-art deep generative models.
Calibrated Uncertainty for Molecular Property Prediction using Ensembles of Message Passing Neural Networks
Jul 13, 2021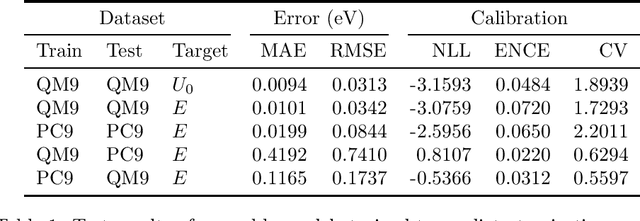
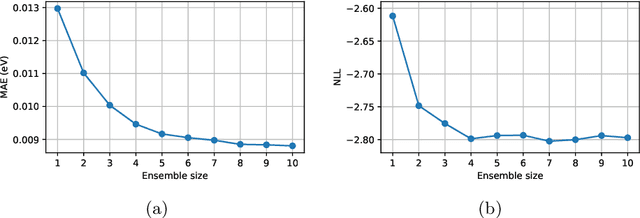
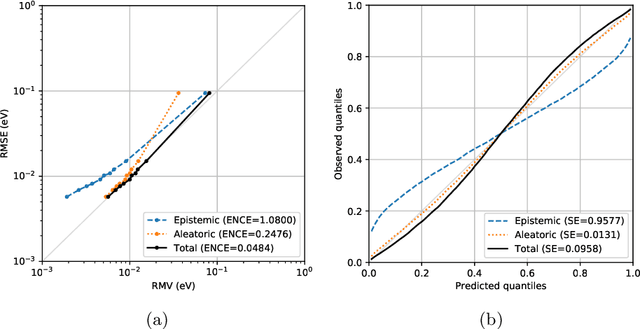
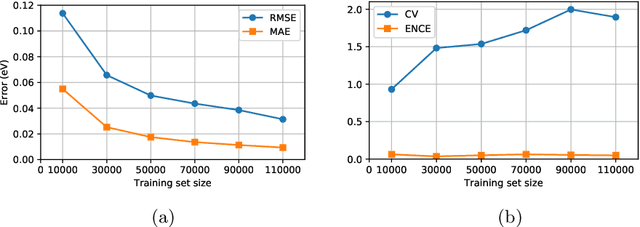
Data-driven methods based on machine learning have the potential to accelerate analysis of atomic structures. However, machine learning models can produce overconfident predictions and it is therefore crucial to detect and handle uncertainty carefully. Here, we extend a message passing neural network designed specifically for predicting properties of molecules and materials with a calibrated probabilistic predictive distribution. The method presented in this paper differs from the previous work by considering both aleatoric and epistemic uncertainty in a unified framework, and by re-calibrating the predictive distribution on unseen data. Through computer experiments, we show that our approach results in accurate models for predicting molecular formation energies with calibrated uncertainty in and out of the training data distribution on two public molecular benchmark datasets, QM9 and PC9. The proposed method provides a general framework for training and evaluating neural network ensemble models that are able to produce accurate predictions of properties of molecules with calibrated uncertainty.
Representation Learning for Out-Of-Distribution Generalization in Reinforcement Learning
Jul 12, 2021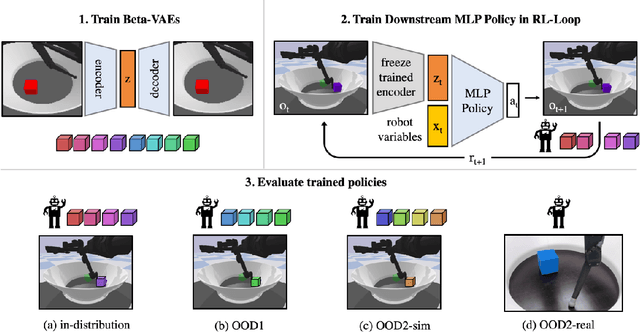
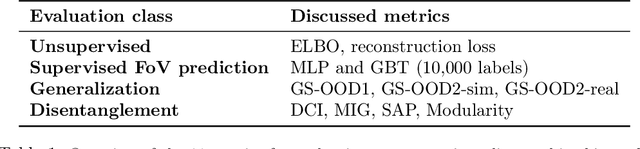
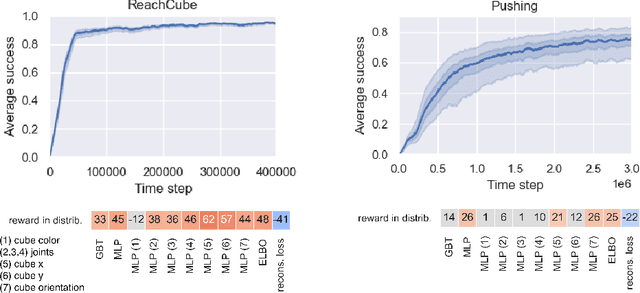
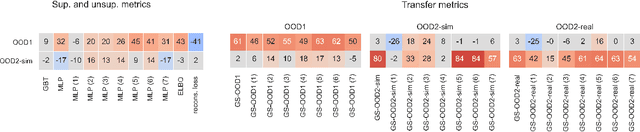
Learning data representations that are useful for various downstream tasks is a cornerstone of artificial intelligence. While existing methods are typically evaluated on downstream tasks such as classification or generative image quality, we propose to assess representations through their usefulness in downstream control tasks, such as reaching or pushing objects. By training over 10,000 reinforcement learning policies, we extensively evaluate to what extent different representation properties affect out-of-distribution (OOD) generalization. Finally, we demonstrate zero-shot transfer of these policies from simulation to the real world, without any domain randomization or fine-tuning. This paper aims to establish the first systematic characterization of the usefulness of learned representations for real-world OOD downstream tasks.
Generalization and Robustness Implications in Object-Centric Learning
Jul 01, 2021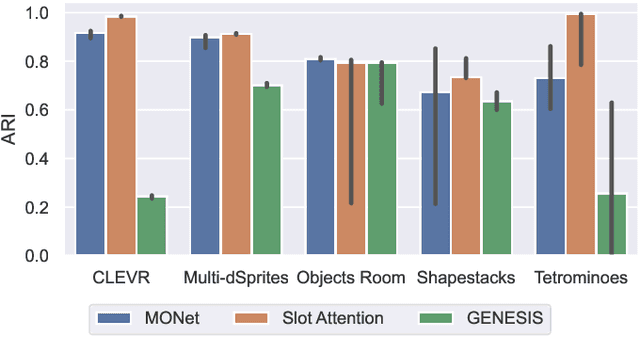
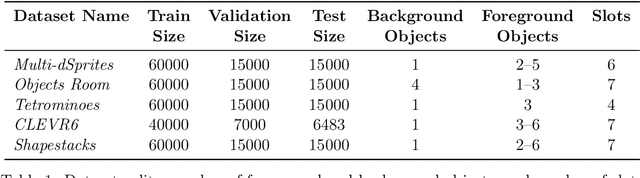

The idea behind object-centric representation learning is that natural scenes can better be modeled as compositions of objects and their relations as opposed to distributed representations. This inductive bias can be injected into neural networks to potentially improve systematic generalization and learning efficiency of downstream tasks in scenes with multiple objects. In this paper, we train state-of-the-art unsupervised models on five common multi-object datasets and evaluate segmentation accuracy and downstream object property prediction. In addition, we study systematic generalization and robustness by investigating the settings where either single objects are out-of-distribution -- e.g., having unseen colors, textures, and shapes -- or global properties of the scene are altered -- e.g., by occlusions, cropping, or increasing the number of objects. From our experimental study, we find object-centric representations to be generally useful for downstream tasks and robust to shifts in the data distribution, especially if shifts affect single objects.
On the Transfer of Disentangled Representations in Realistic Settings
Oct 27, 2020



Learning meaningful representations that disentangle the underlying structure of the data generating process is considered to be of key importance in machine learning. While disentangled representations were found to be useful for diverse tasks such as abstract reasoning and fair classification, their scalability and real-world impact remain questionable. We introduce a new high-resolution dataset with 1M simulated images and over 1,800 annotated real-world images of the same robotic setup. In contrast to previous work, this new dataset exhibits correlations, a complex underlying structure, and allows to evaluate transfer to unseen simulated and real-world settings where the encoder i) remains in distribution or ii) is out of distribution. We propose new architectures in order to scale disentangled representation learning to realistic high-resolution settings and conduct a large-scale empirical study of disentangled representations on this dataset. We observe that disentanglement is a good predictor for out-of-distribution (OOD) task performance.
Optimal Variance Control of the Score Function Gradient Estimator for Importance Weighted Bounds
Aug 05, 2020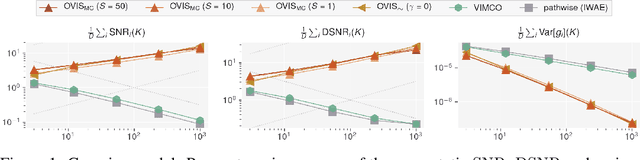
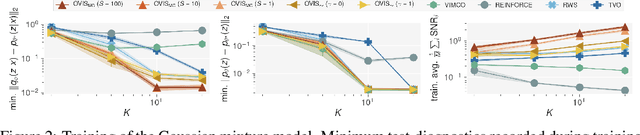
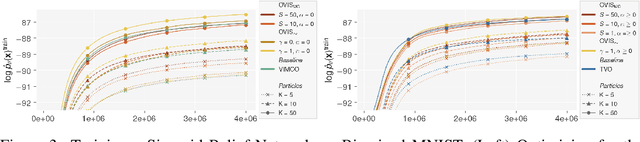
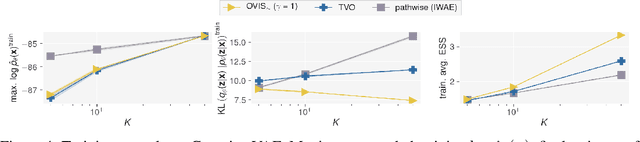
This paper introduces novel results for the score function gradient estimator of the importance weighted variational bound (IWAE). We prove that in the limit of large $K$ (number of importance samples) one can choose the control variate such that the Signal-to-Noise ratio (SNR) of the estimator grows as $\sqrt{K}$. This is in contrast to the standard pathwise gradient estimator where the SNR decreases as $1/\sqrt{K}$. Based on our theoretical findings we develop a novel control variate that extends on VIMCO. Empirically, for the training of both continuous and discrete generative models, the proposed method yields superior variance reduction, resulting in an SNR for IWAE that increases with $K$ without relying on the reparameterization trick. The novel estimator is competitive with state-of-the-art reparameterization-free gradient estimators such as Reweighted Wake-Sleep (RWS) and the thermodynamic variational objective (TVO) when training generative models.