 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Gradient Descent for Non-smooth Optimization: Convergence Results and Optimal Averaging Schemes
Dec 28, 2012Stochastic Gradient Descent (SGD) is one of the simplest and most popular stochastic optimization methods. While it has already been theoretically studied for decades, the classical analysis usually required non-trivial smoothness assumptions, which do not apply to many modern applications of SGD with non-smooth objective functions such as support vector machines. In this paper, we investigate the performance of SGD without such smoothness assumptions, as well as a running average scheme to convert the SGD iterates to a solution with optimal optimization accuracy. In this framework, we prove that after T rounds, the suboptimality of the last SGD iterate scales as O(log(T)/\sqrt{T}) for non-smooth convex objective functions, and O(log(T)/T) in the non-smooth strongly convex case. To the best of our knowledge, these are the first bounds of this kind, and almost match the minimax-optimal rates obtainable by appropriate averaging schemes. We also propose a new and simple averaging scheme, which not only attains optimal rates, but can also be easily computed on-the-fly (in contrast, the suffix averaging scheme proposed in Rakhlin et al. (2011) is not as simple to implement). Finally, we provide some experimental illustrations.
Making Gradient Descent Optimal for Strongly Convex Stochastic Optimization
Dec 09, 2012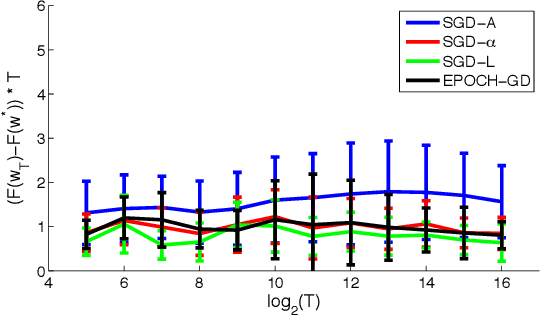
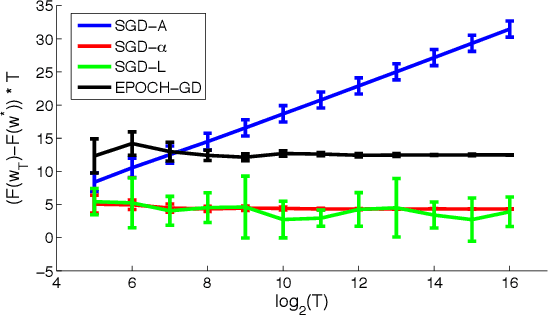
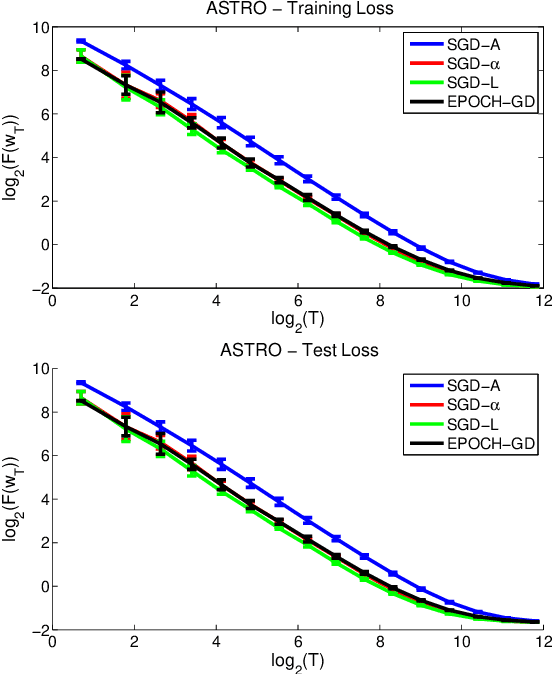
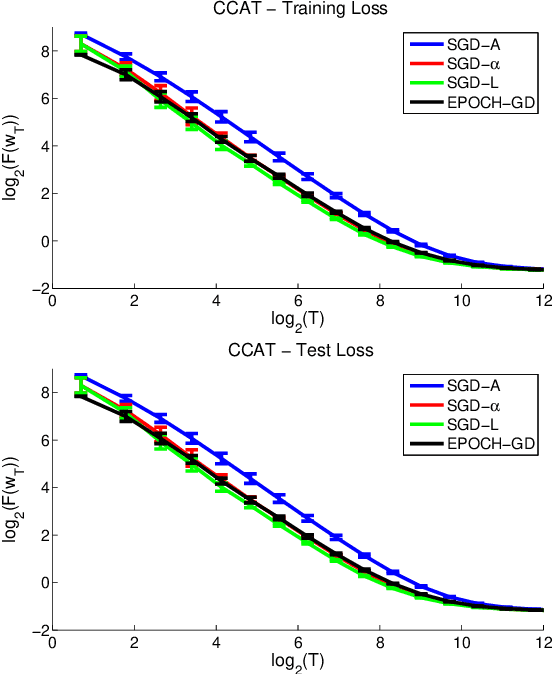
Stochastic gradient descent (SGD) is a simple and popular method to solve stochastic optimization problems which arise in machine learning. For strongly convex problems, its convergence rate was known to be O(\log(T)/T), by running SGD for T iterations and returning the average point. However, recent results showed that using a different algorithm, one can get an optimal O(1/T) rate. This might lead one to believe that standard SGD is suboptimal, and maybe should even be replaced as a method of choice. In this paper, we investigate the optimality of SGD in a stochastic setting. We show that for smooth problems, the algorithm attains the optimal O(1/T) rate. However, for non-smooth problems, the convergence rate with averaging might really be \Omega(\log(T)/T), and this is not just an artifact of the analysis. On the flip side, we show that a simple modification of the averaging step suffices to recover the O(1/T) rate, and no other change of the algorithm is necessary. We also present experimental results which support our findings, and point out open problems.
Decoupling Exploration and Exploitation in Multi-Armed Bandits
Jun 30, 2012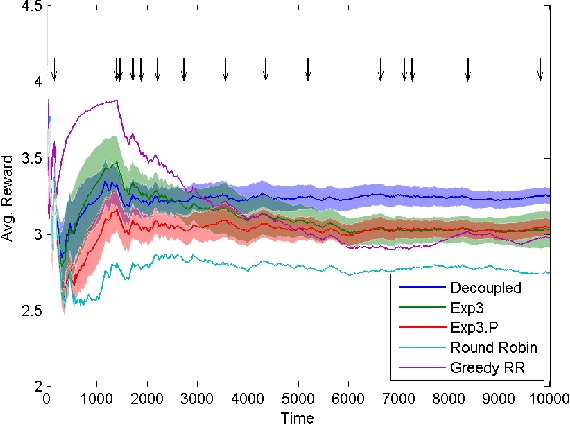
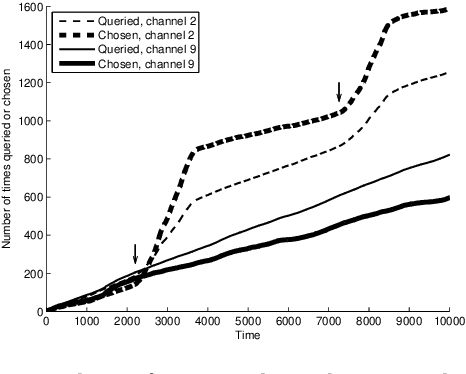
We consider a multi-armed bandit problem where the decision maker can explore and exploit different arms at every round. The exploited arm adds to the decision maker's cumulative reward (without necessarily observing the reward) while the explored arm reveals its value. We devise algorithms for this setup and show that the dependence on the number of arms, k, can be much better than the standard square root of k dependence, depending on the behavior of the arms' reward sequences. For the important case of piecewise stationary stochastic bandits, we show a significant improvement over existing algorithms. Our algorithms are based on a non-uniform sampling policy, which we show is essential to the success of any algorithm in the adversarial setup. Finally, we show some simulation results on an ultra-wide band channel selection inspired setting indicating the applicability of our algorithms.
Relax and Localize: From Value to Algorithms
Apr 04, 2012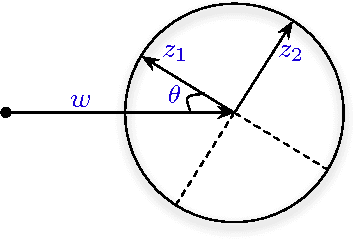
We show a principled way of deriving online learning algorithms from a minimax analysis. Various upper bounds on the minimax value, previously thought to be non-constructive, are shown to yield algorithms. This allows us to seamlessly recover known methods and to derive new ones. Our framework also captures such "unorthodox" methods as Follow the Perturbed Leader and the R^2 forecaster. We emphasize that understanding the inherent complexity of the learning problem leads to the development of algorithms. We define local sequential Rademacher complexities and associated algorithms that allow us to obtain faster rates in online learning, similarly to statistical learning theory. Based on these localized complexities we build a general adaptive method that can take advantage of the suboptimality of the observed sequence. We present a number of new algorithms, including a family of randomized methods that use the idea of a "random playout". Several new versions of the Follow-the-Perturbed-Leader algorithms are presented, as well as methods based on the Littlestone's dimension, efficient methods for matrix completion with trace norm, and algorithms for the problems of transductive learning and prediction with static experts.
Optimal Distributed Online Prediction using Mini-Batches
Jan 31, 2012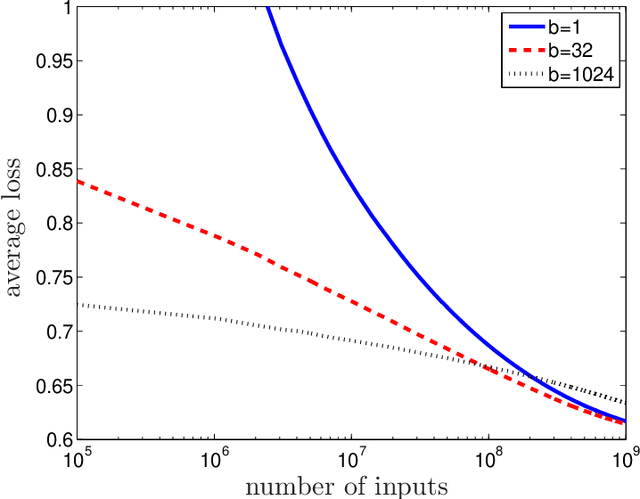
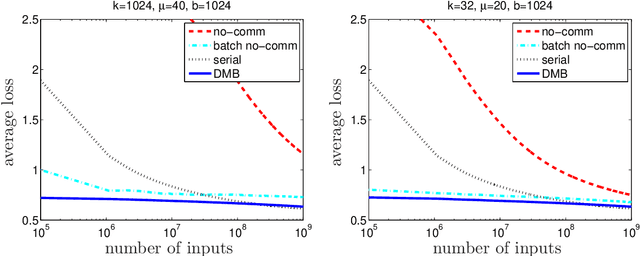
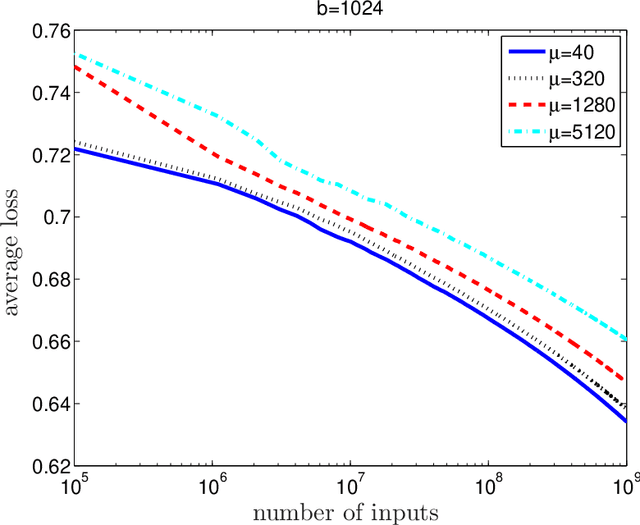
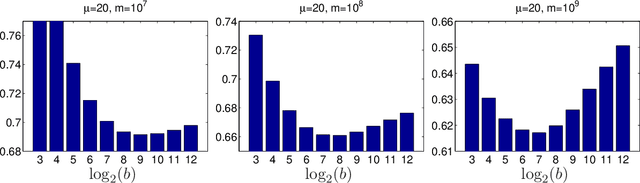
Online prediction methods are typically presented as serial algorithms running on a single processor. However, in the age of web-scale prediction problems, it is increasingly common to encounter situations where a single processor cannot keep up with the high rate at which inputs arrive. In this work, we present the \emph{distributed mini-batch} algorithm, a method of converting many serial gradient-based online prediction algorithms into distributed algorithms. We prove a regret bound for this method that is asymptotically optimal for smooth convex loss functions and stochastic inputs. Moreover, our analysis explicitly takes into account communication latencies between nodes in the distributed environment. We show how our method can be used to solve the closely-related distributed stochastic optimization problem, achieving an asymptotically linear speed-up over multiple processors. Finally, we demonstrate the merits of our approach on a web-scale online prediction problem.
From Bandits to Experts: On the Value of Side-Observations
Oct 25, 2011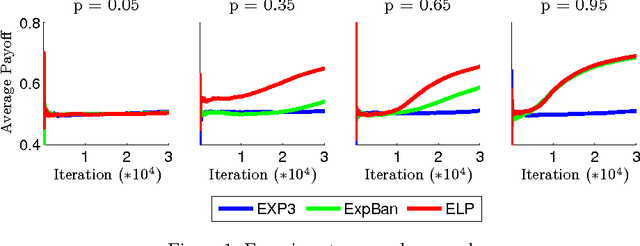
We consider an adversarial online learning setting where a decision maker can choose an action in every stage of the game. In addition to observing the reward of the chosen action, the decision maker gets side observations on the reward he would have obtained had he chosen some of the other actions. The observation structure is encoded as a graph, where node i is linked to node j if sampling i provides information on the reward of j. This setting naturally interpolates between the well-known "experts" setting, where the decision maker can view all rewards, and the multi-armed bandits setting, where the decision maker can only view the reward of the chosen action. We develop practical algorithms with provable regret guarantees, which depend on non-trivial graph-theoretic properties of the information feedback structure. We also provide partially-matching lower bounds.
A Variant of Azuma's Inequality for Martingales with Subgaussian Tails
Oct 13, 2011We provide a variant of Azuma's concentration inequality for martingales, in which the standard boundedness requirement is replaced by the milder requirement of a subgaussian tail.
Adaptively Learning the Crowd Kernel
Jun 25, 2011
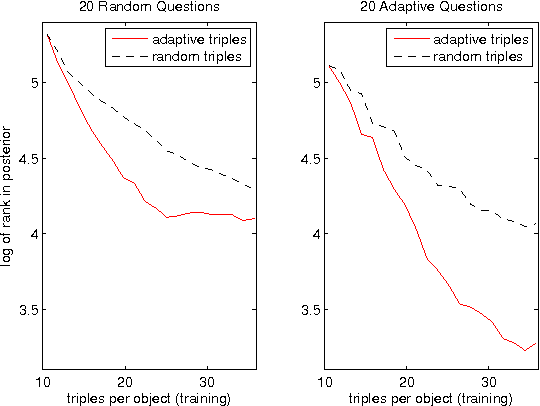


We introduce an algorithm that, given n objects, learns a similarity matrix over all n^2 pairs, from crowdsourced data alone. The algorithm samples responses to adaptively chosen triplet-based relative-similarity queries. Each query has the form "is object 'a' more similar to 'b' or to 'c'?" and is chosen to be maximally informative given the preceding responses. The output is an embedding of the objects into Euclidean space (like MDS); we refer to this as the "crowd kernel." SVMs reveal that the crowd kernel captures prominent and subtle features across a number of domains, such as "is striped" among neckties and "vowel vs. consonant" among letters.
* 9 pages, 7 figures, Accepted to the 28th International Conference on Machine Learning (ICML), 2011
Better Mini-Batch Algorithms via Accelerated Gradient Methods
Jun 22, 2011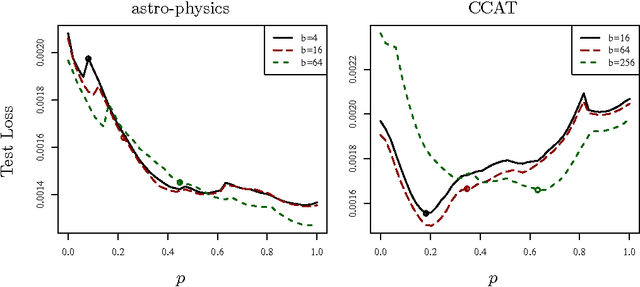
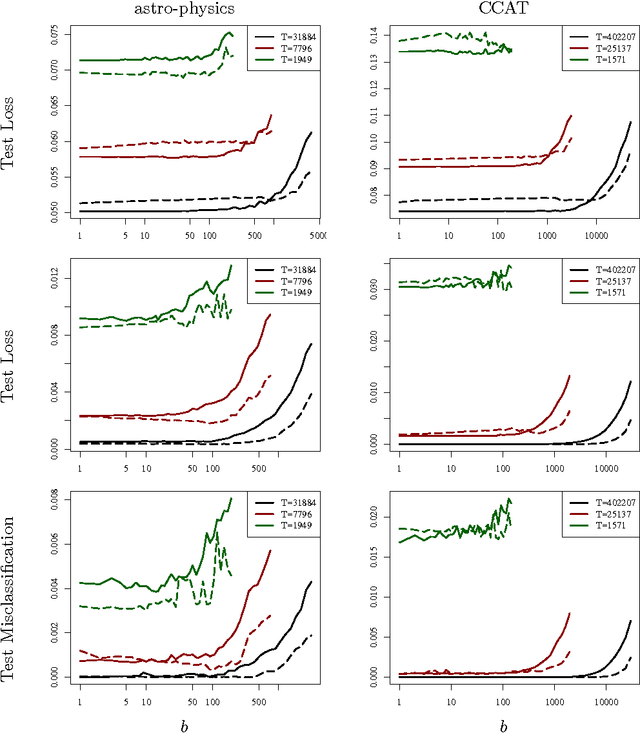
Mini-batch algorithms have been proposed as a way to speed-up stochastic convex optimization problems. We study how such algorithms can be improved using accelerated gradient methods. We provide a novel analysis, which shows how standard gradient methods may sometimes be insufficient to obtain a significant speed-up and propose a novel accelerated gradient algorithm, which deals with this deficiency, enjoys a uniformly superior guarantee and works well in practice.
Learning with the Weighted Trace-norm under Arbitrary Sampling Distributions
Jun 21, 2011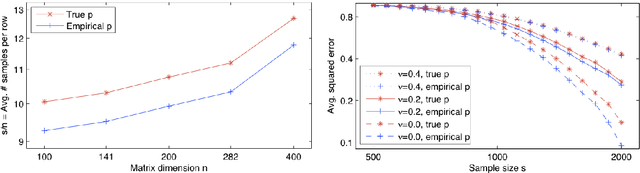
We provide rigorous guarantees on learning with the weighted trace-norm under arbitrary sampling distributions. We show that the standard weighted trace-norm might fail when the sampling distribution is not a product distribution (i.e. when row and column indexes are not selected independently), present a corrected variant for which we establish strong learning guarantees, and demonstrate that it works better in practice. We provide guarantees when weighting by either the true or empirical sampling distribution, and suggest that even if the true distribution is known (or is uniform), weighting by the empirical distribution may be beneficial.