Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptively Learning the Crowd Kernel
Paper and Code
Jun 25, 2011
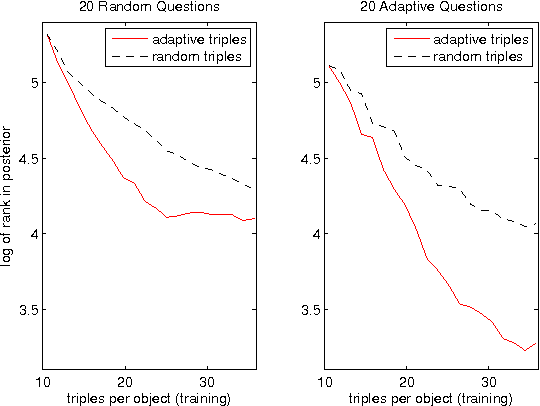


We introduce an algorithm that, given n objects, learns a similarity matrix over all n^2 pairs, from crowdsourced data alone. The algorithm samples responses to adaptively chosen triplet-based relative-similarity queries. Each query has the form "is object 'a' more similar to 'b' or to 'c'?" and is chosen to be maximally informative given the preceding responses. The output is an embedding of the objects into Euclidean space (like MDS); we refer to this as the "crowd kernel." SVMs reveal that the crowd kernel captures prominent and subtle features across a number of domains, such as "is striped" among neckties and "vowel vs. consonant" among letters.
* The 28th International Conference on Machine Learning, 2011 * 9 pages, 7 figures, Accepted to the 28th International Conference on
Machine Learning (ICML), 2011
View paper on