 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL3DG: Latent 3D Gaussian Diffusion
Oct 17, 2024



We propose L3DG, the first approach for generative 3D modeling of 3D Gaussians through a latent 3D Gaussian diffusion formulation. This enables effective generative 3D modeling, scaling to generation of entire room-scale scenes which can be very efficiently rendered. To enable effective synthesis of 3D Gaussians, we propose a latent diffusion formulation, operating in a compressed latent space of 3D Gaussians. This compressed latent space is learned by a vector-quantized variational autoencoder (VQ-VAE), for which we employ a sparse convolutional architecture to efficiently operate on room-scale scenes. This way, the complexity of the costly generation process via diffusion is substantially reduced, allowing higher detail on object-level generation, as well as scalability to large scenes. By leveraging the 3D Gaussian representation, the generated scenes can be rendered from arbitrary viewpoints in real-time. We demonstrate that our approach significantly improves visual quality over prior work on unconditional object-level radiance field synthesis and showcase its applicability to room-scale scene generation.
G3DST: Generalizing 3D Style Transfer with Neural Radiance Fields across Scenes and Styles
Aug 24, 2024



Neural Radiance Fields (NeRF) have emerged as a powerful tool for creating highly detailed and photorealistic scenes. Existing methods for NeRF-based 3D style transfer need extensive per-scene optimization for single or multiple styles, limiting the applicability and efficiency of 3D style transfer. In this work, we overcome the limitations of existing methods by rendering stylized novel views from a NeRF without the need for per-scene or per-style optimization. To this end, we take advantage of a generalizable NeRF model to facilitate style transfer in 3D, thereby enabling the use of a single learned model across various scenes. By incorporating a hypernetwork into a generalizable NeRF, our approach enables on-the-fly generation of stylized novel views. Moreover, we introduce a novel flow-based multi-view consistency loss to preserve consistency across multiple views. We evaluate our method across various scenes and artistic styles and show its performance in generating high-quality and multi-view consistent stylized images without the need for a scene-specific implicit model. Our findings demonstrate that this approach not only achieves a good visual quality comparable to that of per-scene methods but also significantly enhances efficiency and applicability, marking a notable advancement in the field of 3D style transfer.
Robust 3D Gaussian Splatting for Novel View Synthesis in Presence of Distractors
Aug 21, 20243D Gaussian Splatting has shown impressive novel view synthesis results; nonetheless, it is vulnerable to dynamic objects polluting the input data of an otherwise static scene, so called distractors. Distractors have severe impact on the rendering quality as they get represented as view-dependent effects or result in floating artifacts. Our goal is to identify and ignore such distractors during the 3D Gaussian optimization to obtain a clean reconstruction. To this end, we take a self-supervised approach that looks at the image residuals during the optimization to determine areas that have likely been falsified by a distractor. In addition, we leverage a pretrained segmentation network to provide object awareness, enabling more accurate exclusion of distractors. This way, we obtain segmentation masks of distractors to effectively ignore them in the loss formulation. We demonstrate that our approach is robust to various distractors and strongly improves rendering quality on distractor-polluted scenes, improving PSNR by 1.86dB compared to 3D Gaussian Splatting.
MultiDiff: Consistent Novel View Synthesis from a Single Image
Jun 26, 2024



We introduce MultiDiff, a novel approach for consistent novel view synthesis of scenes from a single RGB image. The task of synthesizing novel views from a single reference image is highly ill-posed by nature, as there exist multiple, plausible explanations for unobserved areas. To address this issue, we incorporate strong priors in form of monocular depth predictors and video-diffusion models. Monocular depth enables us to condition our model on warped reference images for the target views, increasing geometric stability. The video-diffusion prior provides a strong proxy for 3D scenes, allowing the model to learn continuous and pixel-accurate correspondences across generated images. In contrast to approaches relying on autoregressive image generation that are prone to drifts and error accumulation, MultiDiff jointly synthesizes a sequence of frames yielding high-quality and multi-view consistent results -- even for long-term scene generation with large camera movements, while reducing inference time by an order of magnitude. For additional consistency and image quality improvements, we introduce a novel, structured noise distribution. Our experimental results demonstrate that MultiDiff outperforms state-of-the-art methods on the challenging, real-world datasets RealEstate10K and ScanNet. Finally, our model naturally supports multi-view consistent editing without the need for further tuning.
GANeRF: Leveraging Discriminators to Optimize Neural Radiance Fields
Jun 09, 2023Neural Radiance Fields (NeRF) have shown impressive novel view synthesis results; nonetheless, even thorough recordings yield imperfections in reconstructions, for instance due to poorly observed areas or minor lighting changes. Our goal is to mitigate these imperfections from various sources with a joint solution: we take advantage of the ability of generative adversarial networks (GANs) to produce realistic images and use them to enhance realism in 3D scene reconstruction with NeRFs. To this end, we learn the patch distribution of a scene using an adversarial discriminator, which provides feedback to the radiance field reconstruction, thus improving realism in a 3D-consistent fashion. Thereby, rendering artifacts are repaired directly in the underlying 3D representation by imposing multi-view path rendering constraints. In addition, we condition a generator with multi-resolution NeRF renderings which is adversarially trained to further improve rendering quality. We demonstrate that our approach significantly improves rendering quality, e.g., nearly halving LPIPS scores compared to Nerfacto while at the same time improving PSNR by 1.4dB on the advanced indoor scenes of Tanks and Temples.
End2End Multi-View Feature Matching using Differentiable Pose Optimization
May 03, 2022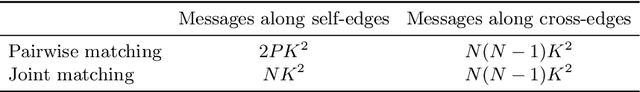

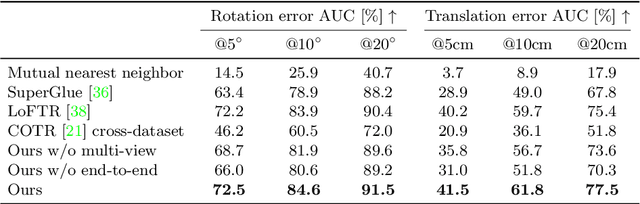
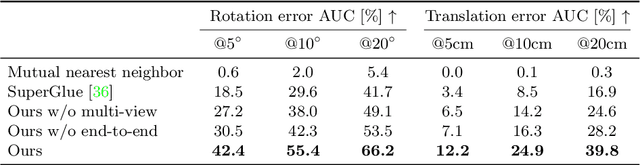
Learning-based approaches have become indispensable for camera pose estimation. However, feature detection, description, matching, and pose optimization are often approached in an isolated fashion. In particular, erroneous feature matches have severe impact on subsequent camera pose estimation and often require additional measures such as outlier rejection. Our method tackles this challenge by addressing feature matching and pose optimization jointly: first, we integrate information from multiple views into the matching by spanning a graph attention network across multiple frames to predict their matches all at once. Second, the resulting matches along with their predicted confidences are used for robust pose optimization with a differentiable Gauss-Newton solver. End-to-end training combined with multi-view feature matching boosts the pose estimation metrics compared to SuperGlue by 8.9% on ScanNet and 10.7% on MegaDepth on average. Our approach improves both pose estimation and matching accuracy over state-of-the-art matching networks. Training feature matching across multiple views with gradients from pose optimization naturally learns to disregard outliers, thereby rendering additional outlier handling unnecessary, which is highly desirable for pose estimation systems.
Dense Depth Priors for Neural Radiance Fields from Sparse Input Views
Dec 06, 2021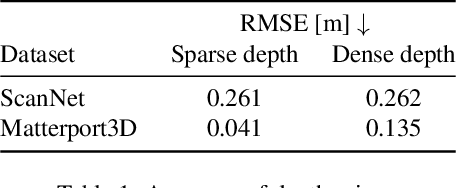
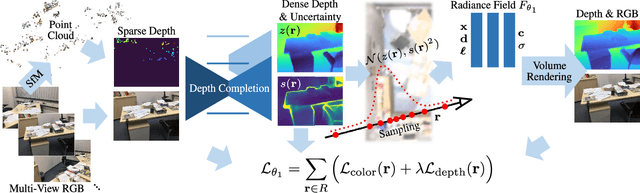
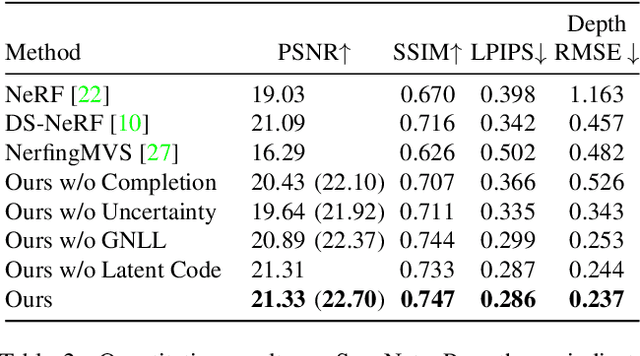

Neural radiance fields (NeRF) encode a scene into a neural representation that enables photo-realistic rendering of novel views. However, a successful reconstruction from RGB images requires a large number of input views taken under static conditions - typically up to a few hundred images for room-size scenes. Our method aims to synthesize novel views of whole rooms from an order of magnitude fewer images. To this end, we leverage dense depth priors in order to constrain the NeRF optimization. First, we take advantage of the sparse depth data that is freely available from the structure from motion (SfM) preprocessing step used to estimate camera poses. Second, we use depth completion to convert these sparse points into dense depth maps and uncertainty estimates, which are used to guide NeRF optimization. Our method enables data-efficient novel view synthesis on challenging indoor scenes, using as few as 18 images for an entire scene.