 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEx-DoF: Expansion of Action Degree-of-Freedom with Virtual Camera Rotation for Omnidirectional Image
Nov 24, 2021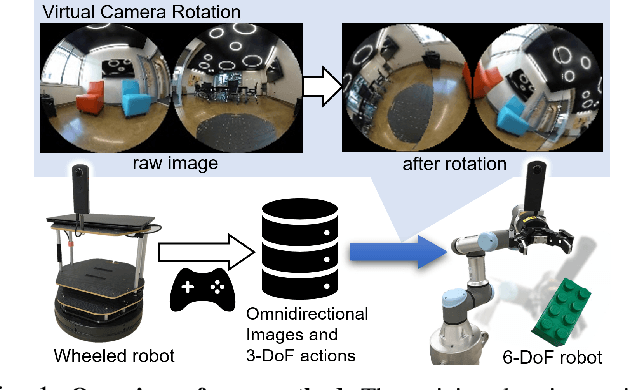
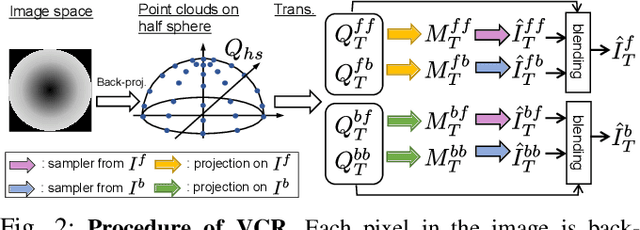
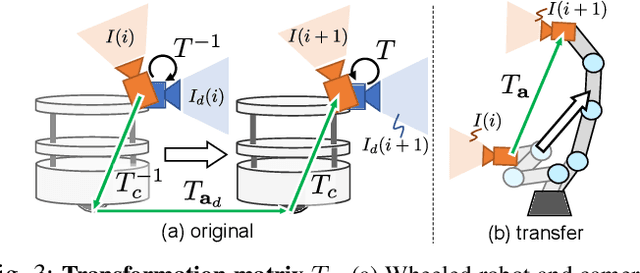
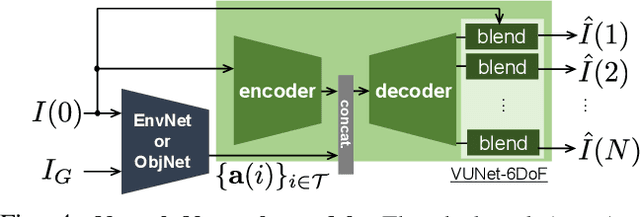
Inter-robot transfer of training data is a little explored topic in learning and vision-based robot control. Thus, we propose a transfer method from a robot with a lower Degree-of-Freedom (DoF) action to one with a higher DoF utilizing an omnidirectional camera. The virtual rotation of the robot camera enables data augmentation in this transfer learning process. In this study, a vision-based control policy for a 6-DoF robot was trained using a dataset collected by a differential wheeled ground robot with only three DoFs. Towards application of robotic manipulations, we also demonstrate a control system of a 6-DoF arm robot using multiple policies with different fields of view to enable object reaching tasks.
Depth360: Monocular Depth Estimation using Learnable Axisymmetric Camera Model for Spherical Camera Image
Oct 20, 2021
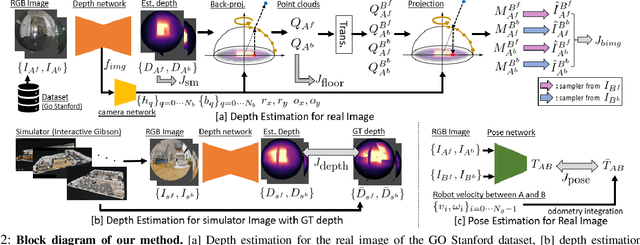
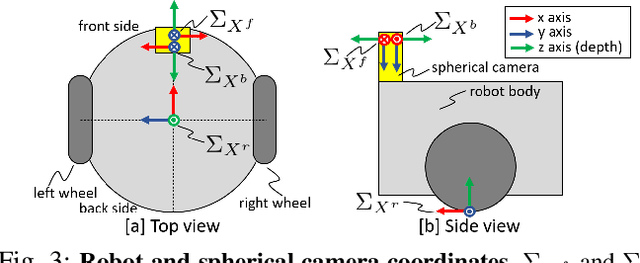
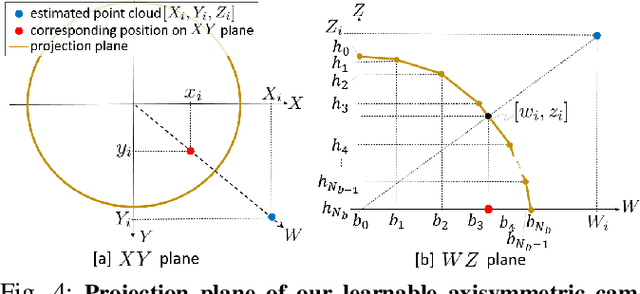
Self-supervised monocular depth estimation has been widely investigated to estimate depth images and relative poses from RGB images. This framework is attractive for researchers because the depth and pose networks can be trained from just time sequence images without the need for the ground truth depth and poses. In this work, we estimate the depth around a robot (360 degree view) using time sequence spherical camera images, from a camera whose parameters are unknown. We propose a learnable axisymmetric camera model which accepts distorted spherical camera images with two fisheye camera images. In addition, we trained our models with a photo-realistic simulator to generate ground truth depth images to provide supervision. Moreover, we introduced loss functions to provide floor constraints to reduce artifacts that can result from reflective floor surfaces. We demonstrate the efficacy of our method using the spherical camera images from the GO Stanford dataset and pinhole camera images from the KITTI dataset to compare our method's performance with that of baseline method in learning the camera parameters.
Variational Monocular Depth Estimation for Reliability Prediction
Nov 24, 2020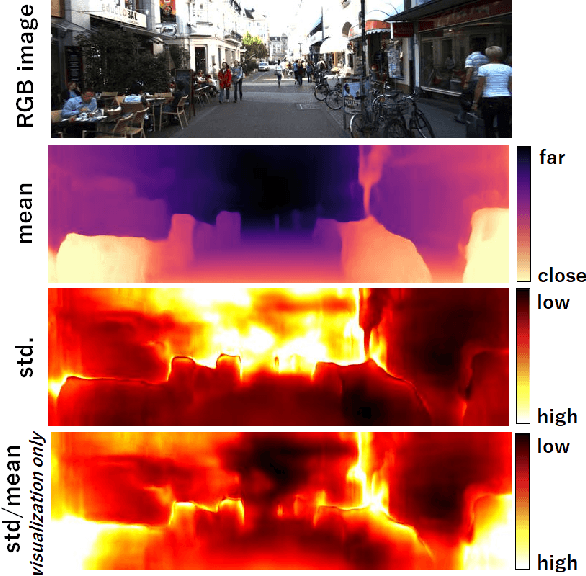
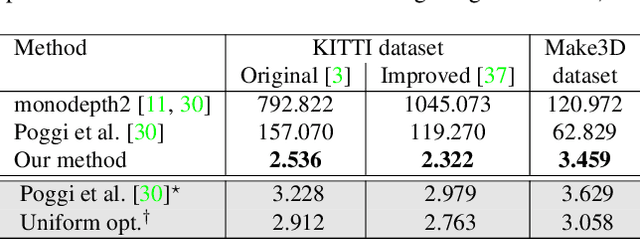
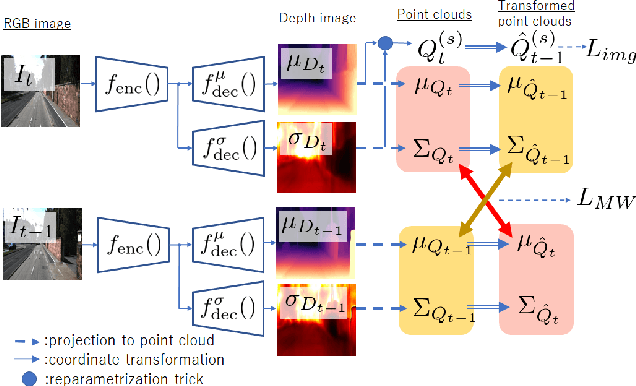
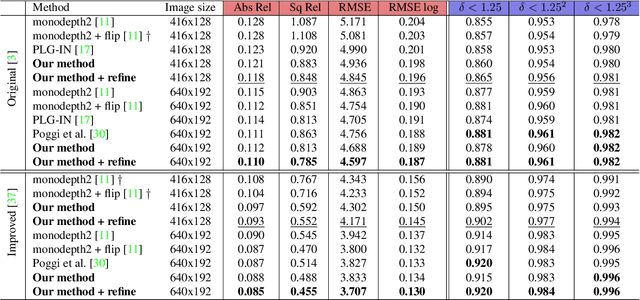
Self-supervised learning for monocular depth estimation is widely investigated as an alternative to supervised learning approach, that requires a lot of ground truths. Previous works have successfully improved the accuracy of depth estimation by modifying the model structure, adding objectives, and masking dynamic objects and occluded area. However, when using such estimated depth image in applications, such as autonomous vehicles, and robots, we have to uniformly believe the estimated depth at each pixel position. This could lead to fatal errors in performing the tasks, because estimated depth at some pixels may make a bigger mistake. In this paper, we theoretically formulate a variational model for the monocular depth estimation to predict the reliability of the estimated depth image. Based on the results, we can exclude the estimated depths with low reliability or refine them for actual use. The effectiveness of the proposed method is quantitatively and qualitatively demonstrated using the KITTI benchmark and Make3D dataset.
PLG-IN: Pluggable Geometric Consistency Loss with Wasserstein Distance in Monocular Depth Estimation
Jun 03, 2020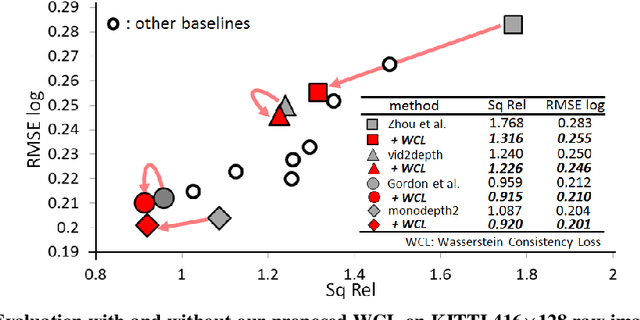
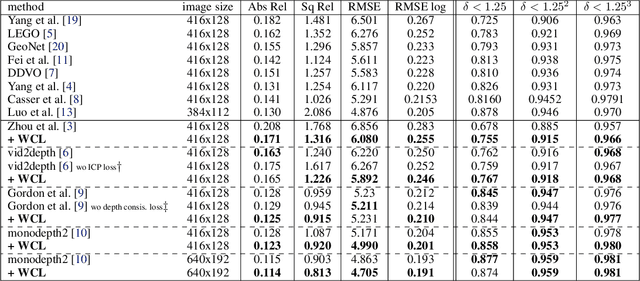

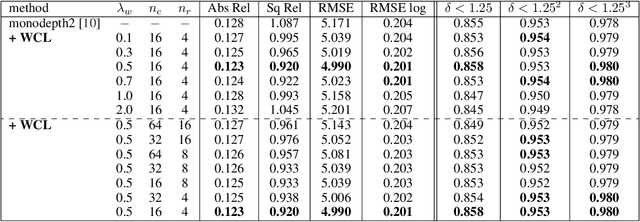
We propose a novel objective to penalize geometric inconsistencies, to improve the performance of depth estimation from monocular camera images. Our objective is designed with the Wasserstein distance between two point clouds estimated from images with different camera poses. The Wasserstein distance can impose a soft and symmetric coupling between two point clouds, which suitably keeps geometric constraints and leads differentiable objective. By adding our objective to the original ones of other state-of-the-art methods, we can effectively penalize a geometric inconsistency and obtain a highly accurate depth estimation. Our proposed method is evaluated on the Eigen split of the KITTI raw dataset.
Probabilistic Visual Navigation with Bidirectional Image Prediction
Mar 20, 2020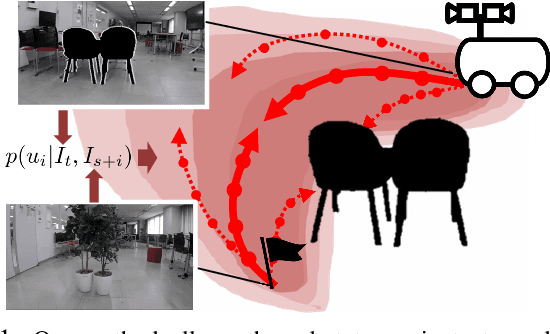
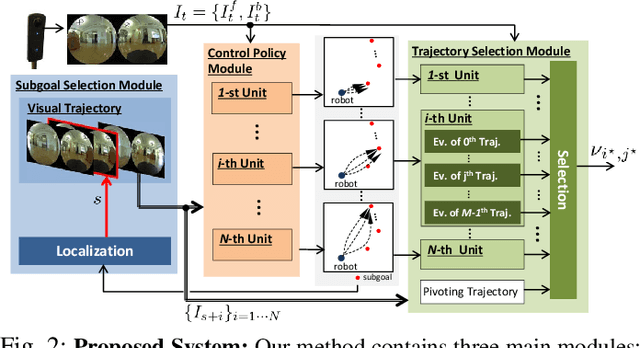
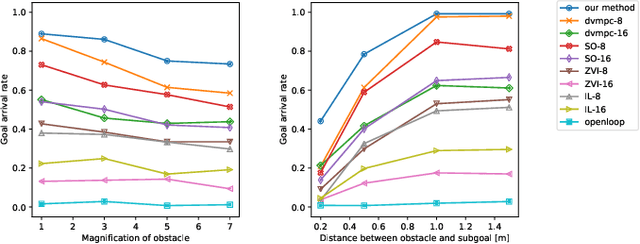
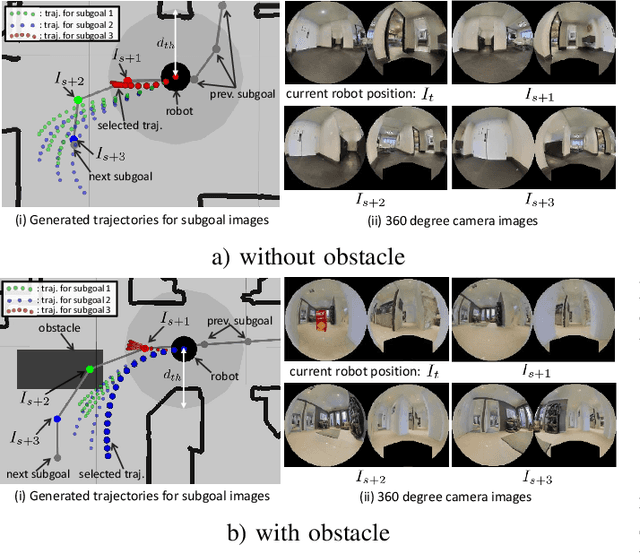
Humans can robustly follow a visual trajectory defined by a sequence of images (i.e. a video) regardless of substantial changes in the environment or the presence of obstacles. We aim at endowing similar visual navigation capabilities to mobile robots solely equipped with a RGB fisheye camera. We propose a novel probabilistic visual navigation system that learns to follow a sequence of images with bidirectional visual predictions conditioned on possible navigation velocities. By predicting bidirectionally (from start towards goal and vice versa) our method extends its predictive horizon enabling the robot to go around unseen large obstacles that are not visible in the video trajectory. Learning how to react to obstacles and potential risks in the visual field is achieved by imitating human teleoperators. Since the human teleoperation commands are diverse, we propose a probabilistic representation of trajectories that we can sample to find the safest path. Integrated into our navigation system, we present a novel localization approach that infers the current location of the robot based on the virtual predicted trajectories required to reach different images in the visual trajectory. We evaluate our navigation system quantitatively and qualitatively in multiple simulated and real environments and compare to state-of-the-art baselines.Our approach outperforms the most recent visual navigation methods with a large margin with regard to goal arrival rate, subgoal coverage rate, and success weighted by path length (SPL). Our method also generalizes to new robot embodiments never used during training.
Deep Visual MPC-Policy Learning for Navigation
Mar 07, 2019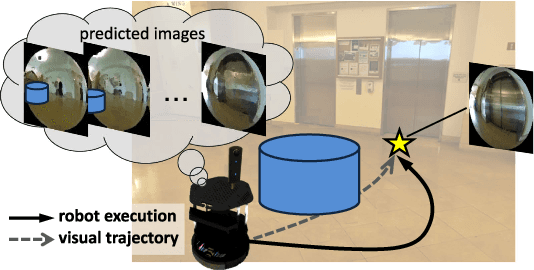
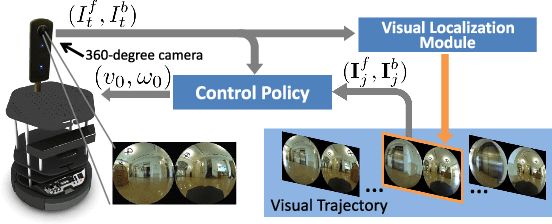
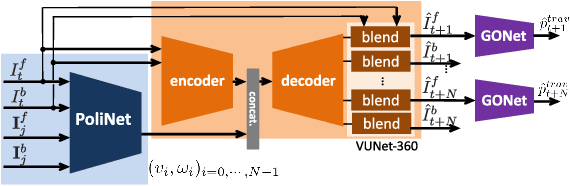
Humans can routinely follow a trajectory defined by a list of images/landmarks. However, traditional robot navigation methods require accurate mapping of the environment, localization, and planning. Moreover, these methods are sensitive to subtle changes in the environment. In this paper, we propose a Deep Visual MPC-policy learning method that can perform visual navigation while avoiding collisions with unseen objects on the navigation path. Our model PoliNet takes in as input a visual trajectory and the image of the robot's current view and outputs velocity commands for a planning horizon of $N$ steps that optimally balance between trajectory following and obstacle avoidance. PoliNet is trained using a strong image predictive model and traversability estimation model in a MPC setup, with minimal human supervision. Different from prior work, PoliNet can be applied to new scenes without retraining. We show experimentally that the robot can follow a visual trajectory when varying start position and in the presence of previously unseen obstacles. We validated our algorithm with tests both in a realistic simulation environment and in the real world. We also show that we can generate visual trajectories in simulation and execute the corresponding path in the real environment. Our approach outperforms classical approaches as well as previous learning-based baselines in success rate of goal reaching, sub-goal coverage rate, and computational load.
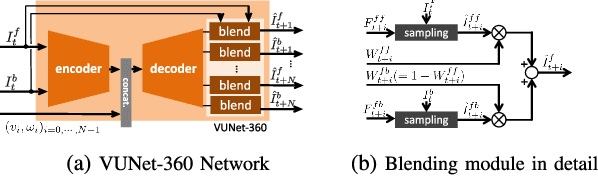
VUNet: Dynamic Scene View Synthesis for Traversability Estimation using an RGB Camera
Jan 10, 2019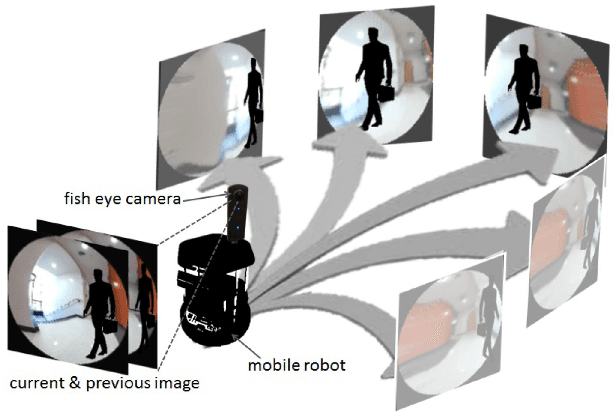
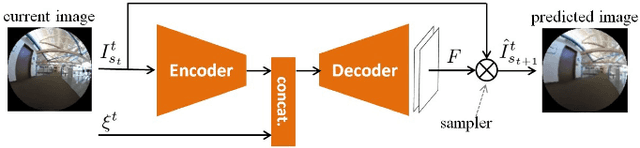
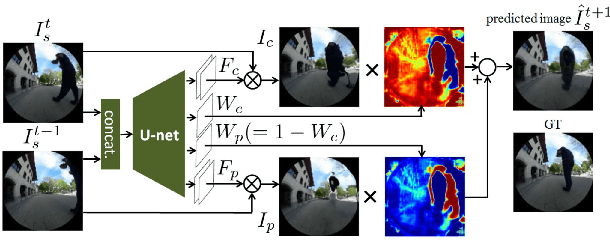
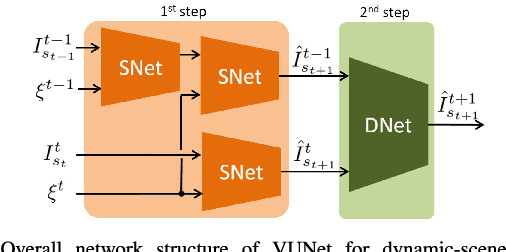
We present VUNet, a novel view(VU) synthesis method for mobile robots in dynamic environments, and its application to the estimation of future traversability. Our method predicts future images for given virtual robot velocity commands using only RGB images at previous and current time steps. The future images result from applying two types of image changes to the previous and current images: 1) changes caused by different camera pose, and 2) changes due to the motion of the dynamic obstacles. We learn to predict these two types of changes disjointly using two novel network architectures, SNet and DNet. We combine SNet and DNet to synthesize future images that we pass to our previously presented method GONet to estimate the traversable areas around the robot. Our quantitative and qualitative evaluation indicate that our approach for view synthesis predicts accurate future images in both static and dynamic environments. We also show that these virtual images can be used to estimate future traversability correctly. We apply our view synthesis-based traversability estimation method to two applications for assisted teleoperation.
* website: http://svl.stanford.edu/projects/vunet/
SoPhie: An Attentive GAN for Predicting Paths Compliant to Social and Physical Constraints
Sep 20, 2018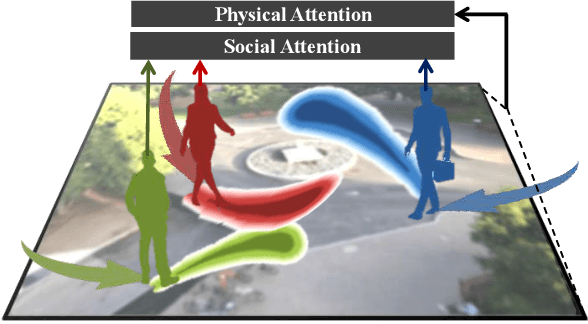
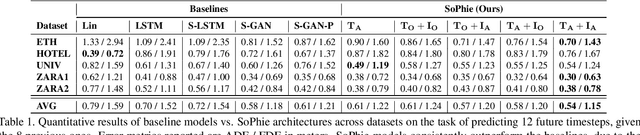
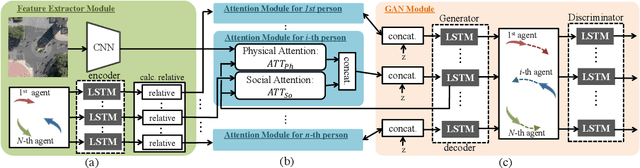

This paper addresses the problem of path prediction for multiple interacting agents in a scene, which is a crucial step for many autonomous platforms such as self-driving cars and social robots. We present \textit{SoPhie}; an interpretable framework based on Generative Adversarial Network (GAN), which leverages two sources of information, the path history of all the agents in a scene, and the scene context information, using images of the scene. To predict a future path for an agent, both physical and social information must be leveraged. Previous work has not been successful to jointly model physical and social interactions. Our approach blends a social attention mechanism with a physical attention that helps the model to learn where to look in a large scene and extract the most salient parts of the image relevant to the path. Whereas, the social attention component aggregates information across the different agent interactions and extracts the most important trajectory information from the surrounding neighbors. SoPhie also takes advantage of GAN to generates more realistic samples and to capture the uncertain nature of the future paths by modeling its distribution. All these mechanisms enable our approach to predict socially and physically plausible paths for the agents and to achieve state-of-the-art performance on several different trajectory forecasting benchmarks.
GONet: A Semi-Supervised Deep Learning Approach For Traversability Estimation
Mar 08, 2018
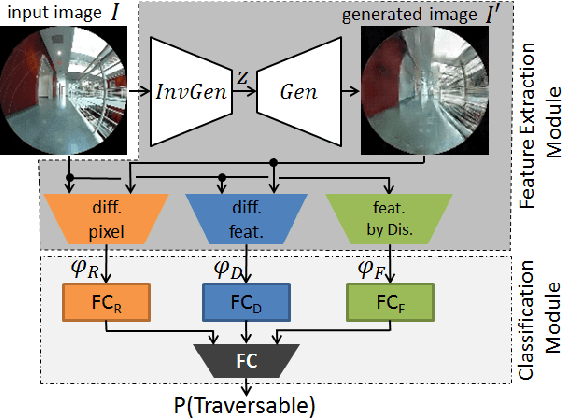
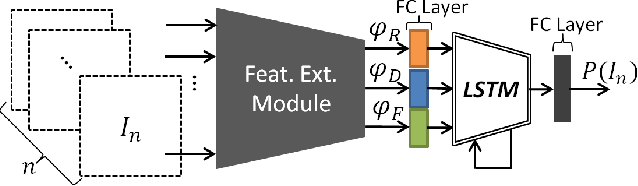

We present semi-supervised deep learning approaches for traversability estimation from fisheye images. Our method, GONet, and the proposed extensions leverage Generative Adversarial Networks (GANs) to effectively predict whether the area seen in the input image(s) is safe for a robot to traverse. These methods are trained with many positive images of traversable places, but just a small set of negative images depicting blocked and unsafe areas. This makes the proposed methods practical. Positive examples can be collected easily by simply operating a robot through traversable spaces, while obtaining negative examples is time consuming, costly, and potentially dangerous. Through extensive experiments and several demonstrations, we show that the proposed traversability estimation approaches are robust and can generalize to unseen scenarios. Further, we demonstrate that our methods are memory efficient and fast, allowing for real-time operation on a mobile robot with single or stereo fisheye cameras. As part of our contributions, we open-source two new datasets for traversability estimation. These datasets are composed of approximately 24h of videos from more than 25 indoor environments. Our methods outperform baseline approaches for traversability estimation on these new datasets.
To Go or Not To Go? A Near Unsupervised Learning Approach For Robot Navigation
Sep 16, 2017


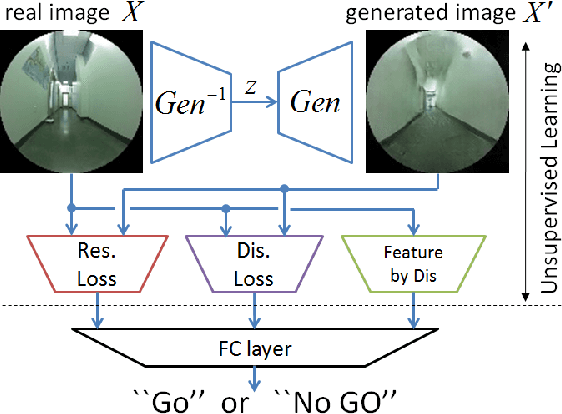
It is important for robots to be able to decide whether they can go through a space or not, as they navigate through a dynamic environment. This capability can help them avoid injury or serious damage, e.g., as a result of running into people and obstacles, getting stuck, or falling off an edge. To this end, we propose an unsupervised and a near-unsupervised method based on Generative Adversarial Networks (GAN) to classify scenarios as traversable or not based on visual data. Our method is inspired by the recent success of data-driven approaches on computer vision problems and anomaly detection, and reduces the need for vast amounts of negative examples at training time. Collecting negative data indicating that a robot should not go through a space is typically hard and dangerous because of collisions, whereas collecting positive data can be automated and done safely based on the robot's own traveling experience. We verify the generality and effectiveness of the proposed approach on a test dataset collected in a previously unseen environment with a mobile robot. Furthermore, we show that our method can be used to build costmaps (we call as "GoNoGo" costmaps) for robot path planning using visual data only.