 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDIN: An End-to-end Benchmark and Pipeline for Unknown Entity Discovery and Indexing
May 25, 2022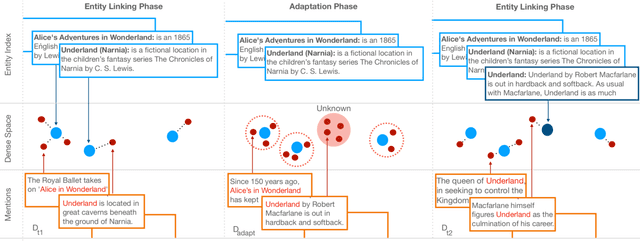
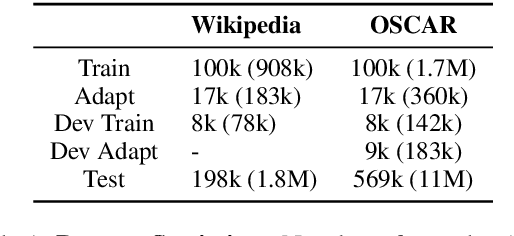
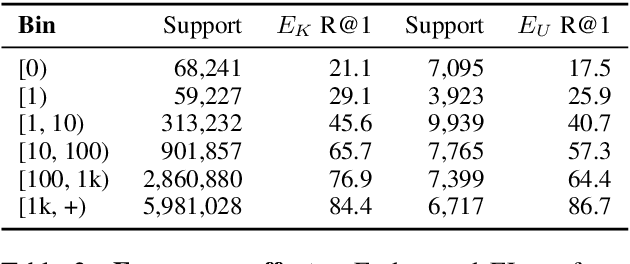
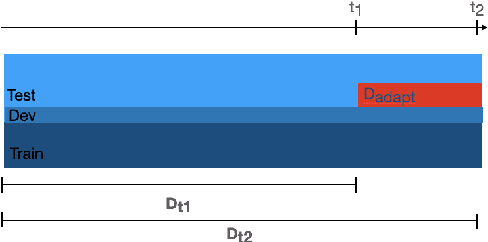
Existing work on Entity Linking mostly assumes that the reference knowledge base is complete, and therefore all mentions can be linked. In practice this is hardly ever the case, as knowledge bases are incomplete and because novel concepts arise constantly. This paper created the Unknown Entity Discovery and Indexing (EDIN) benchmark where unknown entities, that is entities without a description in the knowledge base and labeled mentions, have to be integrated into an existing entity linking system. By contrasting EDIN with zero-shot entity linking, we provide insight on the additional challenges it poses. Building on dense-retrieval based entity linking, we introduce the end-to-end EDIN pipeline that detects, clusters, and indexes mentions of unknown entities in context. Experiments show that indexing a single embedding per entity unifying the information of multiple mentions works better than indexing mentions independently.
Language Models As or For Knowledge Bases
Oct 10, 2021
Pre-trained language models (LMs) have recently gained attention for their potential as an alternative to (or proxy for) explicit knowledge bases (KBs). In this position paper, we examine this hypothesis, identify strengths and limitations of both LMs and KBs, and discuss the complementary nature of the two paradigms. In particular, we offer qualitative arguments that latent LMs are not suitable as a substitute for explicit KBs, but could play a major role for augmenting and curating KBs.
BeliefBank: Adding Memory to a Pre-Trained Language Model for a Systematic Notion of Belief
Sep 29, 2021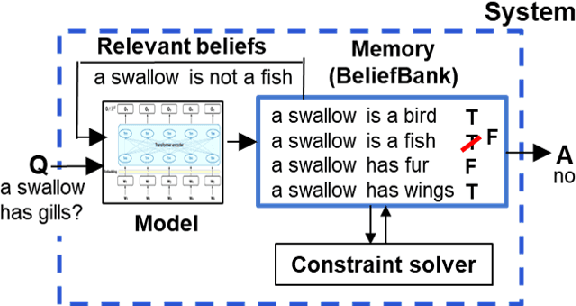

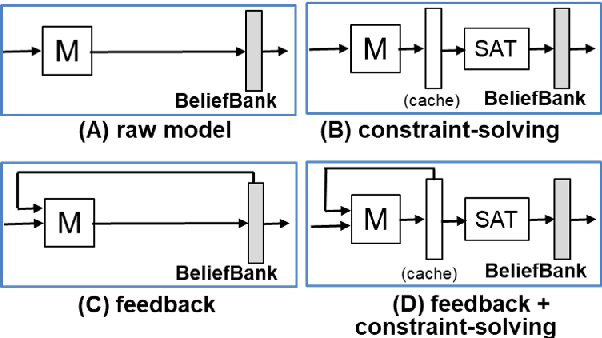

Although pretrained language models (PTLMs) contain significant amounts of world knowledge, they can still produce inconsistent answers to questions when probed, even after specialized training. As a result, it can be hard to identify what the model actually "believes" about the world, making it susceptible to inconsistent behavior and simple errors. Our goal is to reduce these problems. Our approach is to embed a PTLM in a broader system that also includes an evolving, symbolic memory of beliefs -- a BeliefBank -- that records but then may modify the raw PTLM answers. We describe two mechanisms to improve belief consistency in the overall system. First, a reasoning component -- a weighted MaxSAT solver -- revises beliefs that significantly clash with others. Second, a feedback component issues future queries to the PTLM using known beliefs as context. We show that, in a controlled experimental setting, these two mechanisms result in more consistent beliefs in the overall system, improving both the accuracy and consistency of its answers over time. This is significant as it is a first step towards PTLM-based architectures with a systematic notion of belief, enabling them to construct a more coherent picture of the world, and improve over time without model retraining.
Enriching a Model's Notion of Belief using a Persistent Memory
Apr 16, 2021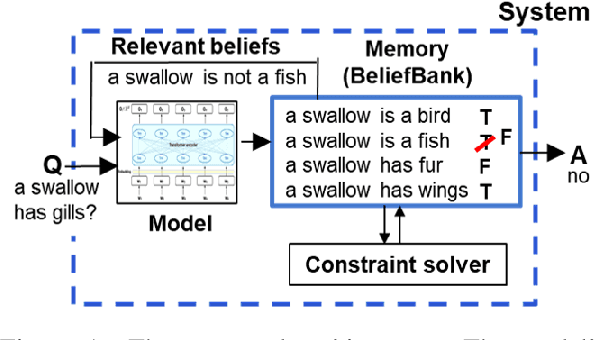

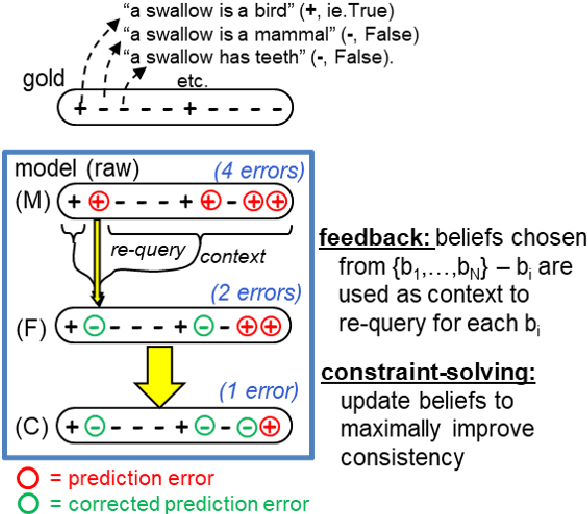
Although pretrained language models (PTLMs) have been shown to contain significant amounts of world knowledge, they can still produce inconsistent answers to questions when probed, even after using specialized training techniques to reduce inconsistency. As a result, it can be hard to identify what the model actually "believes" about the world. Our goal is to reduce this problem, so systems are more globally consistent and accurate in their answers. Our approach is to add a memory component - a BeliefBank - that records a model's answers, and two mechanisms that use it to improve consistency among beliefs. First, a reasoning component - a weighted SAT solver - improves consistency by flipping answers that significantly clash with others. Second, a feedback component re-queries the model but using known beliefs as context. We show that, in a controlled experimental setting, these two mechanisms improve both accuracy and consistency. This is significant as it is a first step towards endowing models with an evolving memory, allowing them to construct a more coherent picture of the world.
Static Embeddings as Efficient Knowledge Bases?
Apr 14, 2021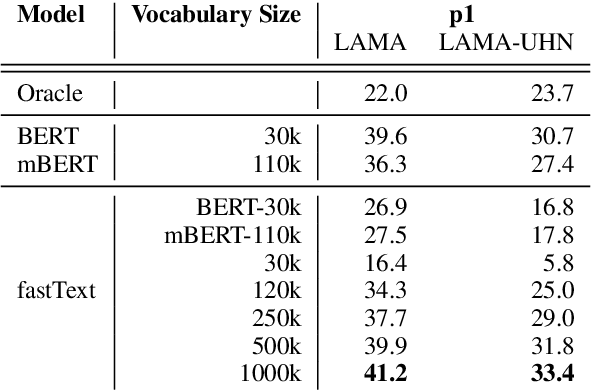
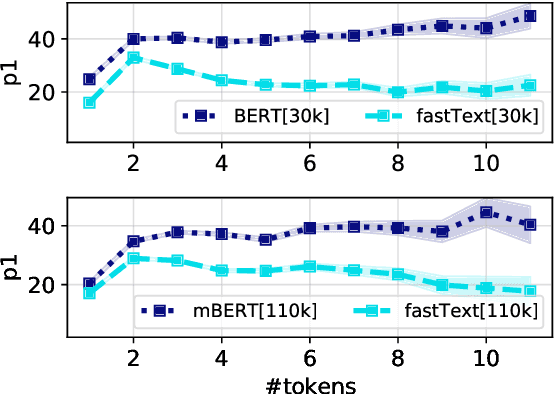
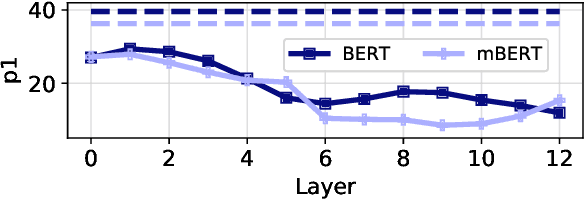
Recent research investigates factual knowledge stored in large pretrained language models (PLMs). Instead of structural knowledge base (KB) queries, masked sentences such as "Paris is the capital of [MASK]" are used as probes. The good performance on this analysis task has been interpreted as PLMs becoming potential repositories of factual knowledge. In experiments across ten linguistically diverse languages, we study knowledge contained in static embeddings. We show that, when restricting the output space to a candidate set, simple nearest neighbor matching using static embeddings performs better than PLMs. E.g., static embeddings perform 1.6% points better than BERT while just using 0.3% of energy for training. One important factor in their good comparative performance is that static embeddings are standardly learned for a large vocabulary. In contrast, BERT exploits its more sophisticated, but expensive ability to compose meaningful representations from a much smaller subword vocabulary.
Measuring and Improving Consistency in Pretrained Language Models
Feb 01, 2021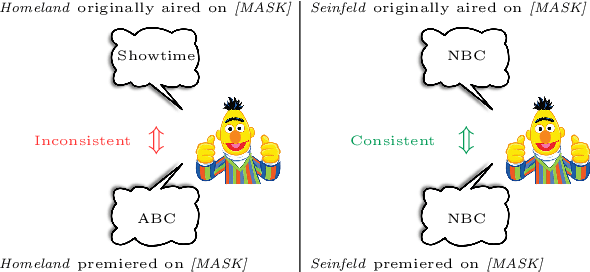
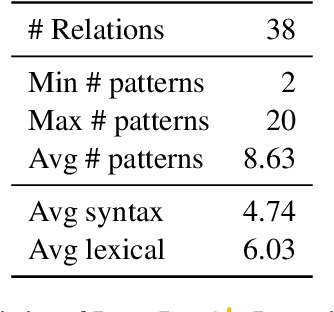
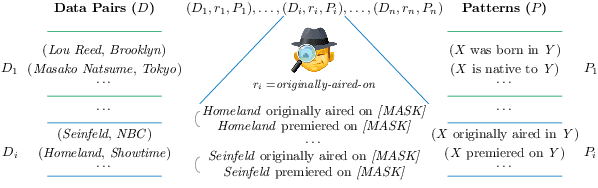
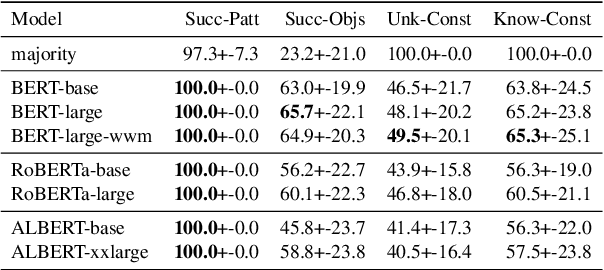
Consistency of a model -- that is, the invariance of its behavior under meaning-preserving alternations in its input -- is a highly desirable property in natural language processing. In this paper we study the question: Are Pretrained Language Models (PLMs) consistent with respect to factual knowledge? To this end, we create ParaRel, a high-quality resource of cloze-style query English paraphrases. It contains a total of 328 paraphrases for thirty-eight relations. Using ParaRel, we show that the consistency of all PLMs we experiment with is poor -- though with high variance between relations. Our analysis of the representational spaces of PLMs suggests that they have a poor structure and are currently not suitable for representing knowledge in a robust way. Finally, we propose a method for improving model consistency and experimentally demonstrate its effectiveness.
Multilingual LAMA: Investigating Knowledge in Multilingual Pretrained Language Models
Feb 01, 2021
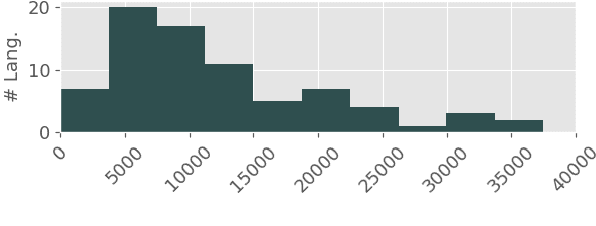
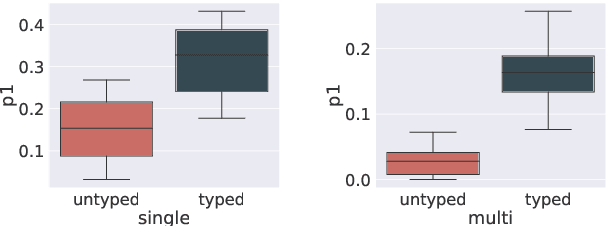
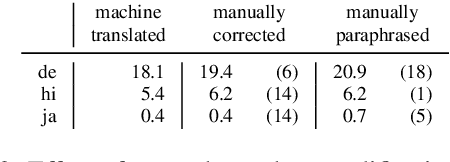
Recently, it has been found that monolingual English language models can be used as knowledge bases. Instead of structural knowledge base queries, masked sentences such as "Paris is the capital of [MASK]" are used as probes. We translate the established benchmarks TREx and GoogleRE into 53 languages. Working with mBERT, we investigate three questions. (i) Can mBERT be used as a multilingual knowledge base? Most prior work only considers English. Extending research to multiple languages is important for diversity and accessibility. (ii) Is mBERT's performance as knowledge base language-independent or does it vary from language to language? (iii) A multilingual model is trained on more text, e.g., mBERT is trained on 104 Wikipedias. Can mBERT leverage this for better performance? We find that using mBERT as a knowledge base yields varying performance across languages and pooling predictions across languages improves performance. Conversely, mBERT exhibits a language bias; e.g., when queried in Italian, it tends to predict Italy as the country of origin.
Dirichlet-Smoothed Word Embeddings for Low-Resource Settings
Jun 22, 2020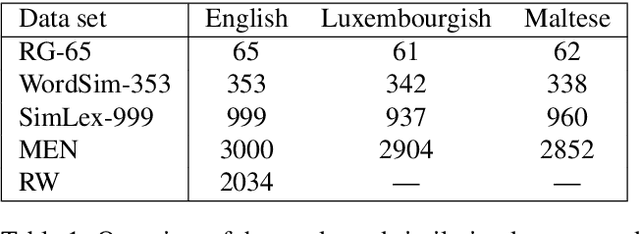
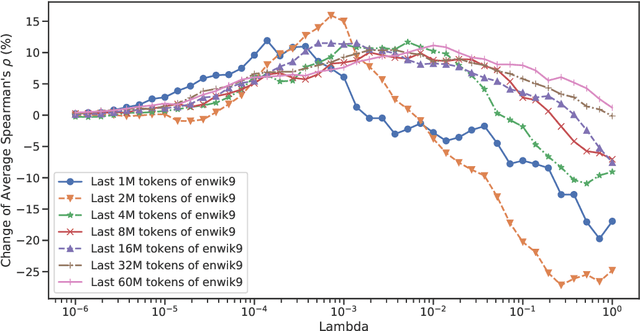
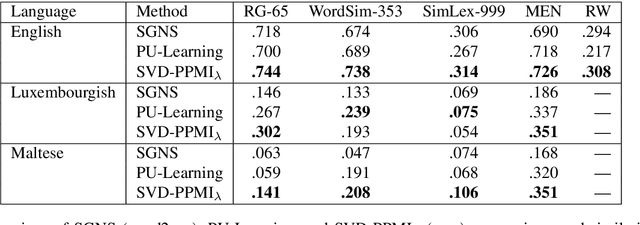
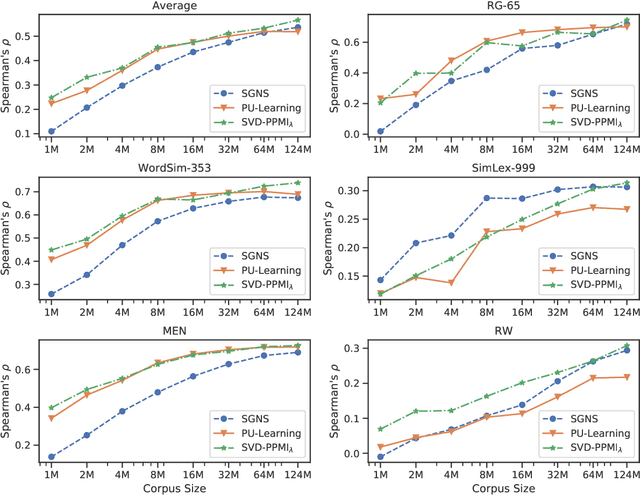
Nowadays, classical count-based word embeddings using positive pointwise mutual information (PPMI) weighted co-occurrence matrices have been widely superseded by machine-learning-based methods like word2vec and GloVe. But these methods are usually applied using very large amounts of text data. In many cases, however, there is not much text data available, for example for specific domains or low-resource languages. This paper revisits PPMI by adding Dirichlet smoothing to correct its bias towards rare words. We evaluate on standard word similarity data sets and compare to word2vec and the recent state of the art for low-resource settings: Positive and Unlabeled (PU) Learning for word embeddings. The proposed method outperforms PU-Learning for low-resource settings and obtains competitive results for Maltese and Luxembourgish.
Pre-trained Language Models as Symbolic Reasoners over Knowledge?
Jun 18, 2020
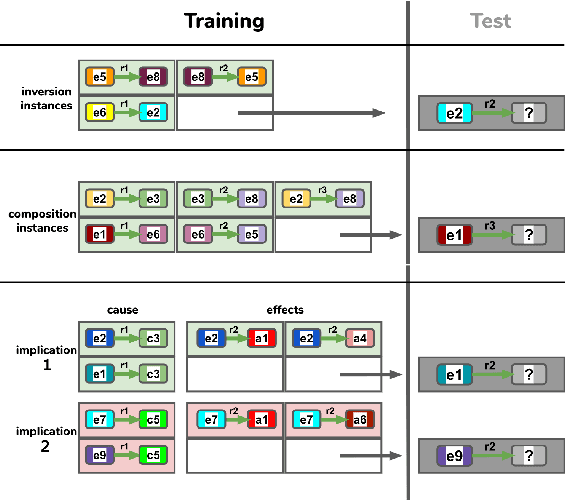
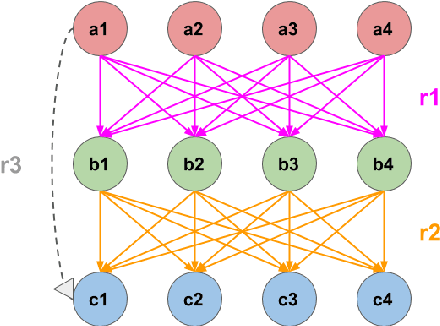

How can pre-trained language models (PLMs) learn factual knowledge from the training set? We investigate the two most important mechanisms: reasoning and memorization. Prior work has attempted to quantify the number of facts PLMs learn, but we present, using synthetic data, the first study that establishes a causal relation between facts present in training and facts learned by the PLM. For reasoning, we show that PLMs learn to apply some symbolic reasoning rules; but in particular, they struggle with two-hop reasoning. For memorization, we identify schema conformity (facts systematically supported by other facts) and frequency as key factors for its success.
BERT-kNN: Adding a kNN Search Component to Pretrained Language Models for Better QA
May 02, 2020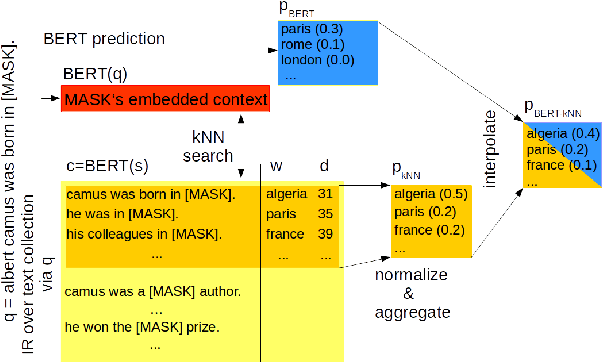

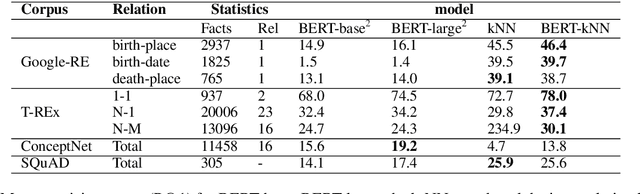
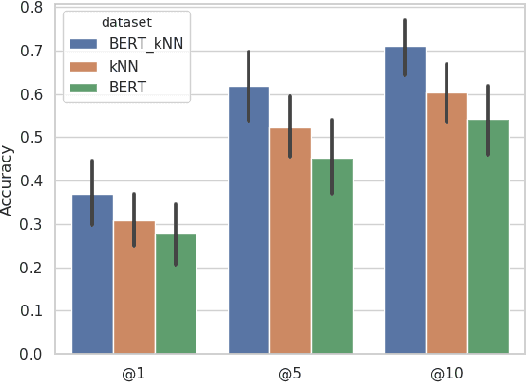
Khandelwal et al. (2020) show that a k-nearest-neighbor (kNN) component improves language modeling performance. We use this idea for open domain question answering (QA). To improve the recall of facts stated in the training text, we combine BERT (Devlin et al., 2019) with a kNN search over a large corpus. Our contributions are as follows. i) We outperform BERT on cloze-style QA by large margins without any further training. ii) We show that BERT often identifies the correct response category (e.g., central European city), but only kNN recovers the factually correct answer (e.g., "Vienna").