 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatic Embeddings as Efficient Knowledge Bases?
Paper and Code
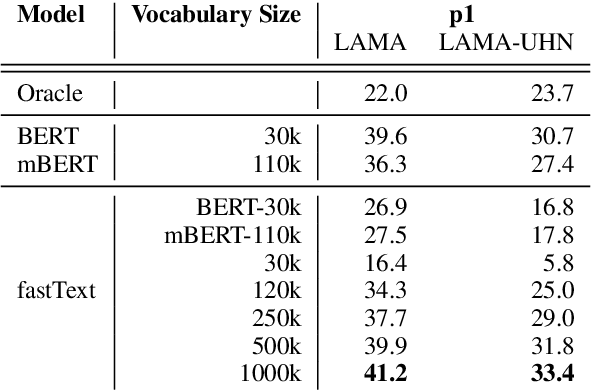
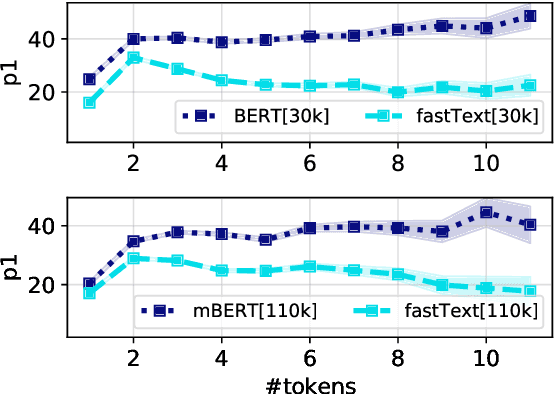
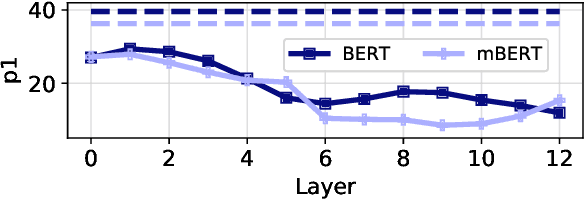
Recent research investigates factual knowledge stored in large pretrained language models (PLMs). Instead of structural knowledge base (KB) queries, masked sentences such as "Paris is the capital of [MASK]" are used as probes. The good performance on this analysis task has been interpreted as PLMs becoming potential repositories of factual knowledge. In experiments across ten linguistically diverse languages, we study knowledge contained in static embeddings. We show that, when restricting the output space to a candidate set, simple nearest neighbor matching using static embeddings performs better than PLMs. E.g., static embeddings perform 1.6% points better than BERT while just using 0.3% of energy for training. One important factor in their good comparative performance is that static embeddings are standardly learned for a large vocabulary. In contrast, BERT exploits its more sophisticated, but expensive ability to compose meaningful representations from a much smaller subword vocabulary.