 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Transformer Models by Reordering their Sublayers
Nov 10, 2019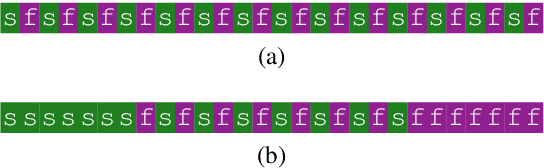
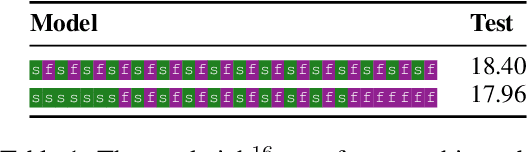
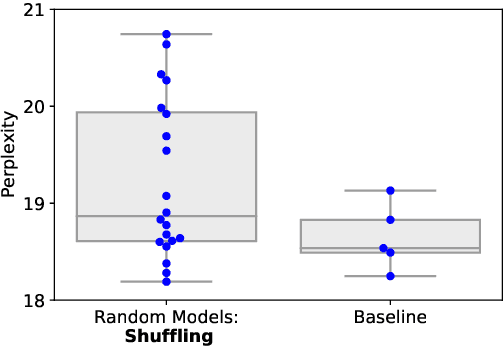

Multilayer transformer networks consist of interleaved self-attention and feedforward sublayers. Could ordering the sublayers in a different pattern achieve better performance? We generate randomly ordered transformers and train them with the language modeling objective. We observe that some of these models are able to achieve better performance than the interleaved baseline, and that those successful variants tend to have more self-attention at the bottom and more feedforward sublayers at the top. We propose a new transformer design pattern that adheres to this property, the sandwich transformer, and show that it improves perplexity on the WikiText-103 language modeling benchmark, at no cost in parameters, memory, or training time.
Situating Sentence Embedders with Nearest Neighbor Overlap
Sep 24, 2019
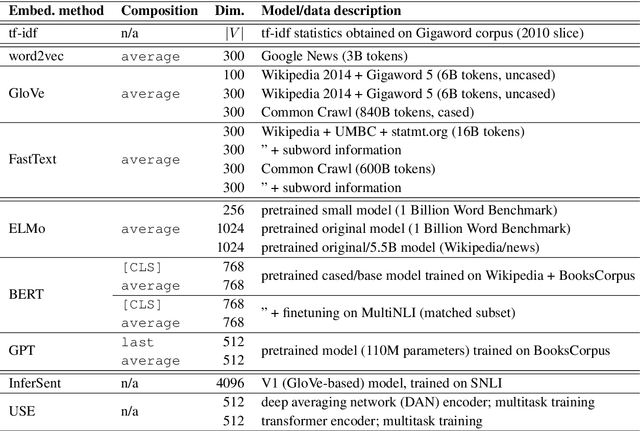
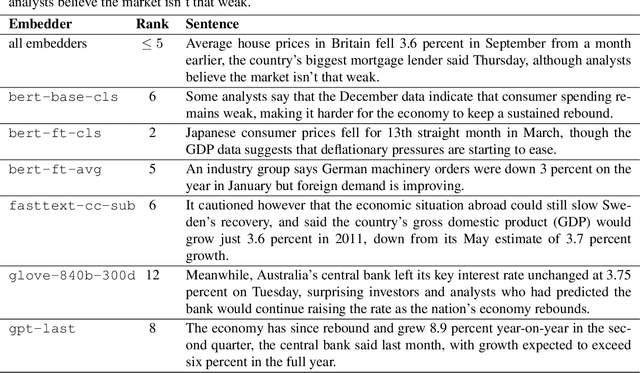
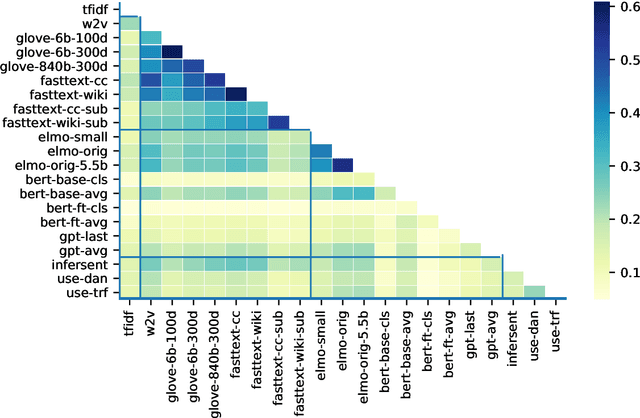
As distributed approaches to natural language semantics have developed and diversified, embedders for linguistic units larger than words have come to play an increasingly important role. To date, such embedders have been evaluated using benchmark tasks (e.g., GLUE) and linguistic probes. We propose a comparative approach, nearest neighbor overlap (N2O), that quantifies similarity between embedders in a task-agnostic manner. N2O requires only a collection of examples and is simple to understand: two embedders are more similar if, for the same set of inputs, there is greater overlap between the inputs' nearest neighbors. Though applicable to embedders of texts of any size, we focus on sentence embedders and use N2O to show the effects of different design choices and architectures.
Low-Resource Parsing with Crosslingual Contextualized Representations
Sep 19, 2019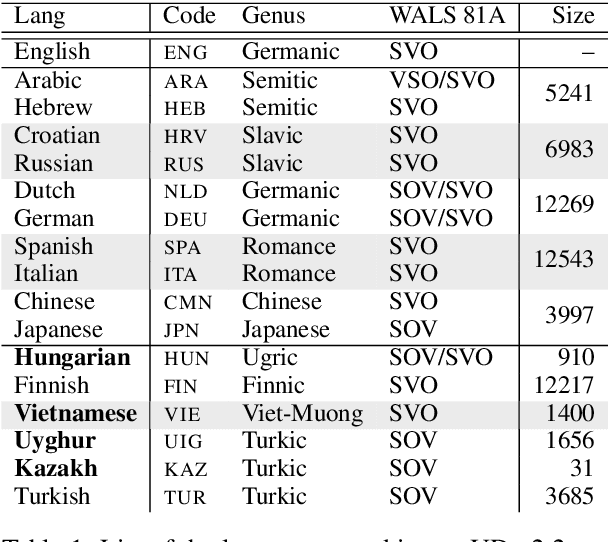
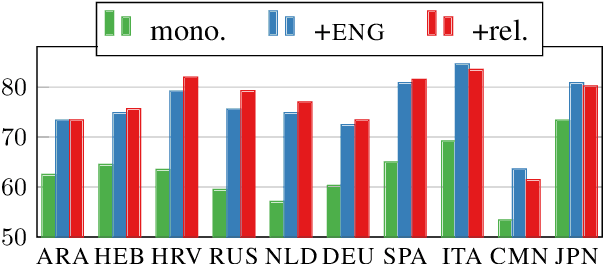

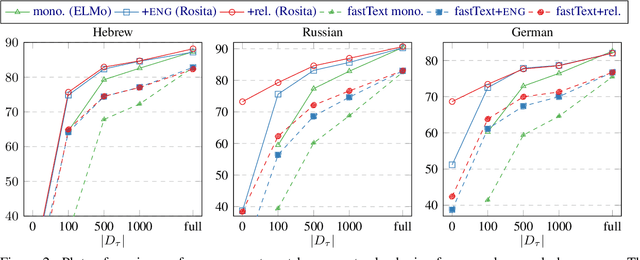
Despite advances in dependency parsing, languages with small treebanks still present challenges. We assess recent approaches to multilingual contextual word representations (CWRs), and compare them for crosslingual transfer from a language with a large treebank to a language with a small or nonexistent treebank, by sharing parameters between languages in the parser itself. We experiment with a diverse selection of languages in both simulated and truly low-resource scenarios, and show that multilingual CWRs greatly facilitate low-resource dependency parsing even without crosslingual supervision such as dictionaries or parallel text. Furthermore, we examine the non-contextual part of the learned language models (which we call a "decontextual probe") to demonstrate that polyglot language models better encode crosslingual lexical correspondence compared to aligned monolingual language models. This analysis provides further evidence that polyglot training is an effective approach to crosslingual transfer.
Improving Natural Language Inference with a Pretrained Parser
Sep 18, 2019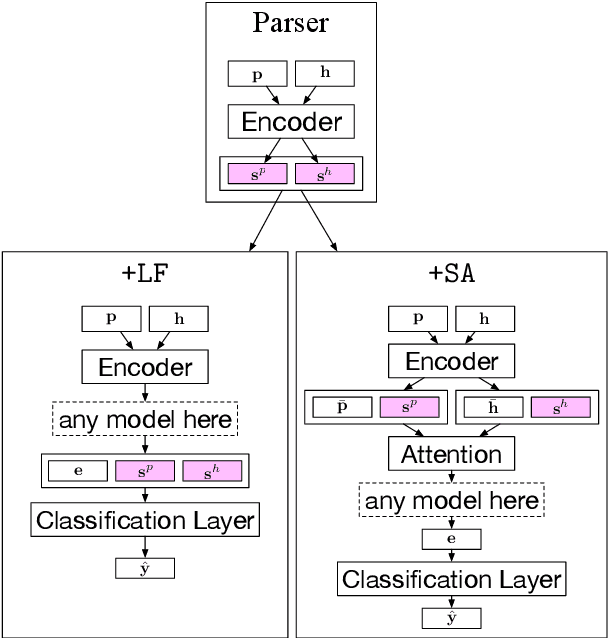
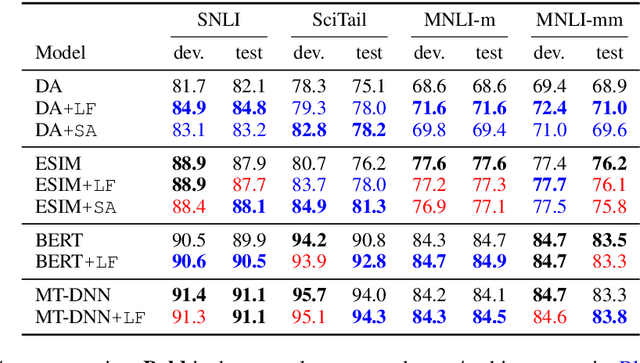
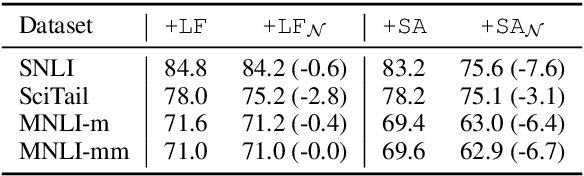
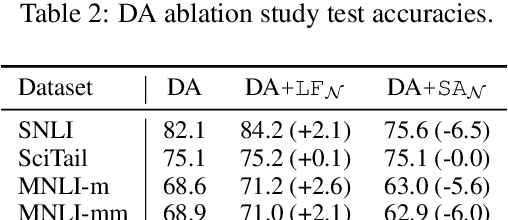
We introduce a novel approach to incorporate syntax into natural language inference (NLI) models. Our method uses contextual token-level vector representations from a pretrained dependency parser. Like other contextual embedders, our method is broadly applicable to any neural model. We experiment with four strong NLI models (decomposable attention model, ESIM, BERT, and MT-DNN), and show consistent benefit to accuracy across three NLI benchmarks.
Knowledge Enhanced Contextual Word Representations
Sep 09, 2019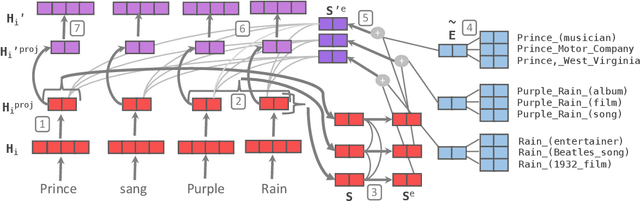
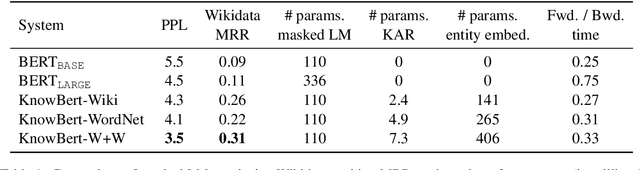
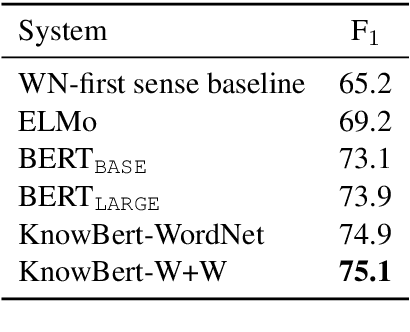
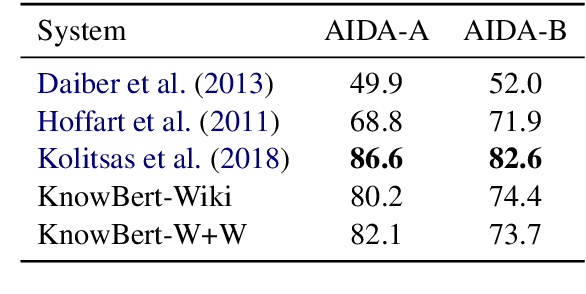
Contextual word representations, typically trained on unstructured, unlabeled text, do not contain any explicit grounding to real world entities and are often unable to remember facts about those entities. We propose a general method to embed multiple knowledge bases (KBs) into large scale models, and thereby enhance their representations with structured, human-curated knowledge. For each KB, we first use an integrated entity linker to retrieve relevant entity embeddings, then update contextual word representations via a form of word-to-entity attention. In contrast to previous approaches, the entity linkers and self-supervised language modeling objective are jointly trained end-to-end in a multitask setting that combines a small amount of entity linking supervision with a large amount of raw text. After integrating WordNet and a subset of Wikipedia into BERT, the knowledge enhanced BERT (KnowBert) demonstrates improved perplexity, ability to recall facts as measured in a probing task and downstream performance on relationship extraction, entity typing, and word sense disambiguation. KnowBert's runtime is comparable to BERT's and it scales to large KBs.
RNN Architecture Learning with Sparse Regularization
Sep 06, 2019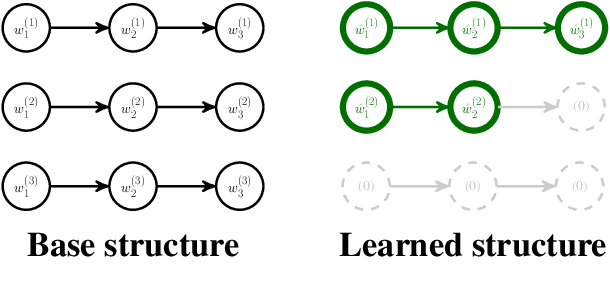
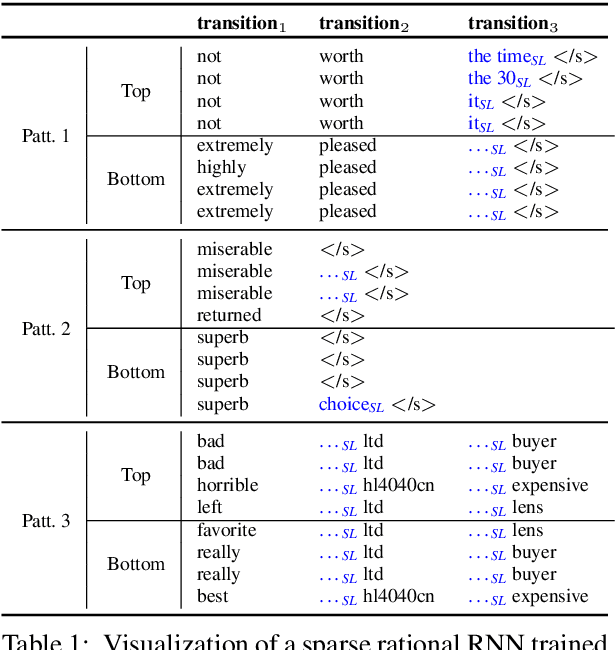
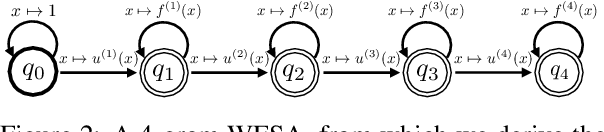
Neural models for NLP typically use large numbers of parameters to reach state-of-the-art performance, which can lead to excessive memory usage and increased runtime. We present a structure learning method for learning sparse, parameter-efficient NLP models. Our method applies group lasso to rational RNNs (Peng et al., 2018), a family of models that is closely connected to weighted finite-state automata (WFSAs). We take advantage of rational RNNs' natural grouping of the weights, so the group lasso penalty directly removes WFSA states, substantially reducing the number of parameters in the model. Our experiments on a number of sentiment analysis datasets, using both GloVe and BERT embeddings, show that our approach learns neural structures which have fewer parameters without sacrificing performance relative to parameter-rich baselines. Our method also highlights the interpretable properties of rational RNNs. We show that sparsifying such models makes them easier to visualize, and we present models that rely exclusively on as few as three WFSAs after pruning more than 90% of the weights. We publicly release our code.
Show Your Work: Improved Reporting of Experimental Results
Sep 06, 2019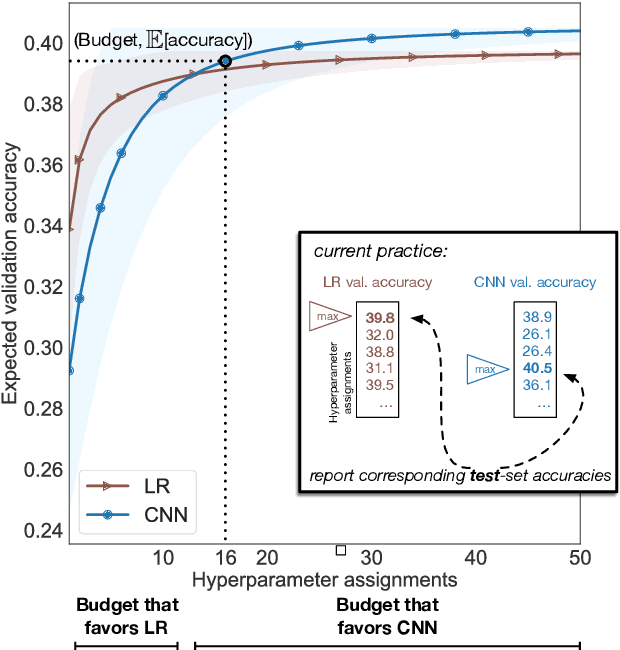
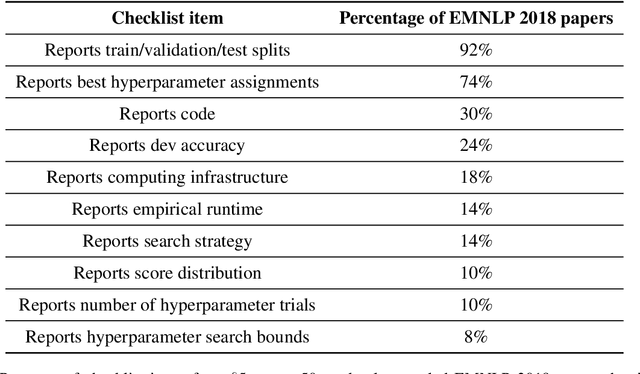
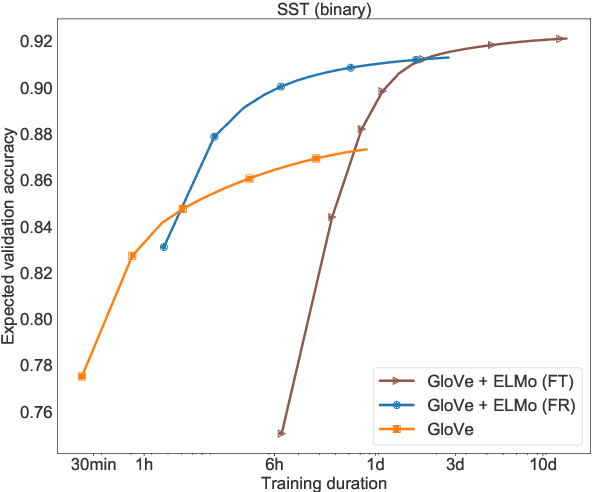
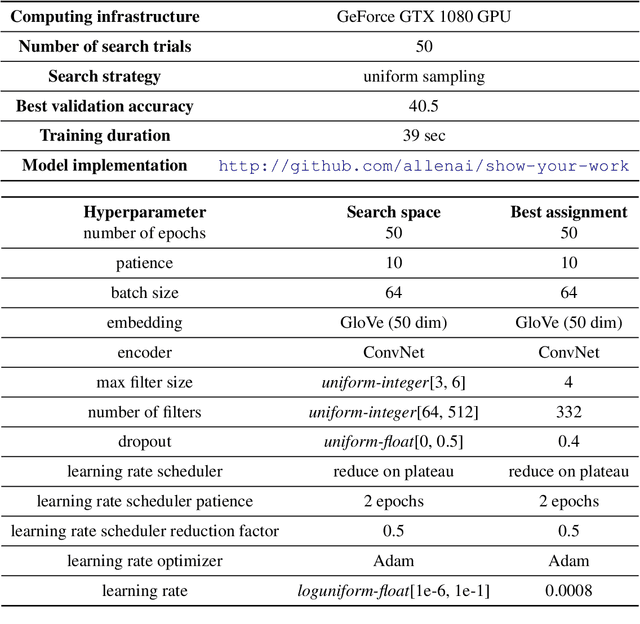
Research in natural language processing proceeds, in part, by demonstrating that new models achieve superior performance (e.g., accuracy) on held-out test data, compared to previous results. In this paper, we demonstrate that test-set performance scores alone are insufficient for drawing accurate conclusions about which model performs best. We argue for reporting additional details, especially performance on validation data obtained during model development. We present a novel technique for doing so: expected validation performance of the best-found model as a function of computation budget (i.e., the number of hyperparameter search trials or the overall training time). Using our approach, we find multiple recent model comparisons where authors would have reached a different conclusion if they had used more (or less) computation. Our approach also allows us to estimate the amount of computation required to obtain a given accuracy; applying it to several recently published results yields massive variation across papers, from hours to weeks. We conclude with a set of best practices for reporting experimental results which allow for robust future comparisons, and provide code to allow researchers to use our technique.
Quoref: A Reading Comprehension Dataset with Questions Requiring Coreferential Reasoning
Sep 05, 2019
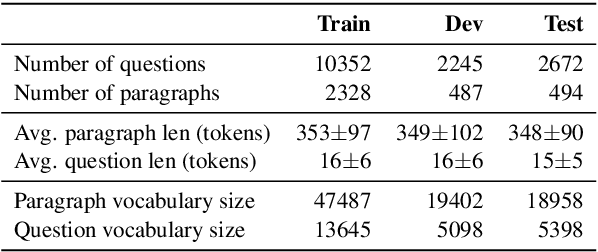

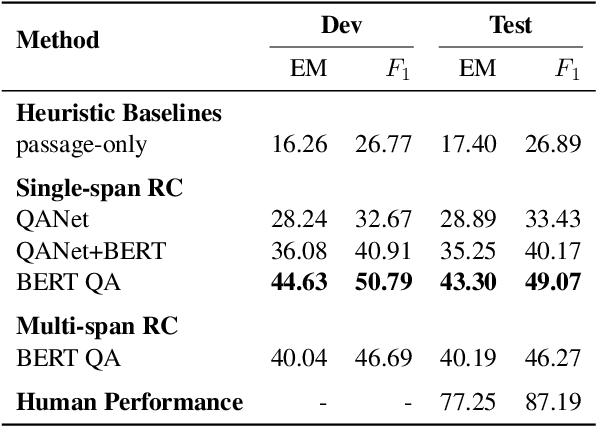
Machine comprehension of texts longer than a single sentence often requires coreference resolution. However, most current reading comprehension benchmarks do not contain complex coreferential phenomena and hence fail to evaluate the ability of models to resolve coreference. We present a new crowdsourced dataset containing more than 24K span-selection questions that require resolving coreference among entities in over 4.7K English paragraphs from Wikipedia. Obtaining questions focused on such phenomena is challenging, because it is hard to avoid lexical cues that shortcut complex reasoning. We deal with this issue by using a strong baseline model as an adversary in the crowdsourcing loop, which helps crowdworkers avoid writing questions with exploitable surface cues. We show that state-of-the-art reading comprehension models perform significantly worse than humans on this benchmark---the best model performance is 70.5 F1, while the estimated human performance is 93.4 F1.
PaLM: A Hybrid Parser and Language Model
Sep 04, 2019
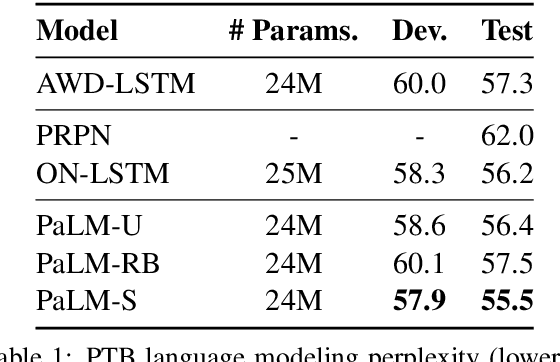
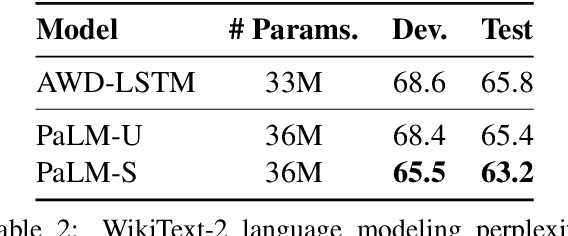
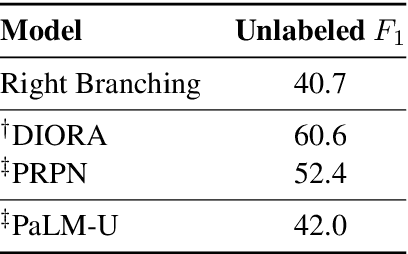
We present PaLM, a hybrid parser and neural language model. Building on an RNN language model, PaLM adds an attention layer over text spans in the left context. An unsupervised constituency parser can be derived from its attention weights, using a greedy decoding algorithm. We evaluate PaLM on language modeling, and empirically show that it outperforms strong baselines. If syntactic annotations are available, the attention component can be trained in a supervised manner, providing syntactically-informed representations of the context, and further improving language modeling performance.
Topics to Avoid: Demoting Latent Confounds in Text Classification
Sep 01, 2019
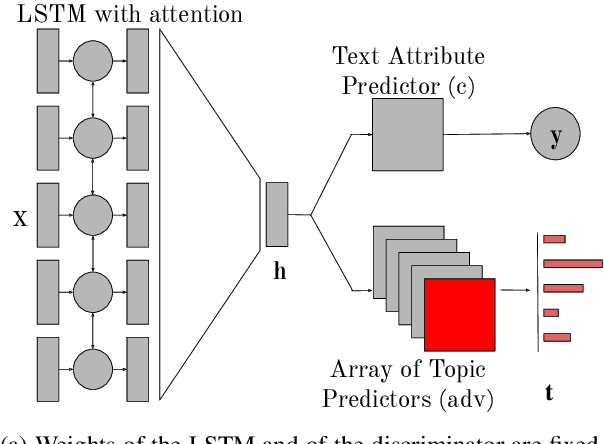
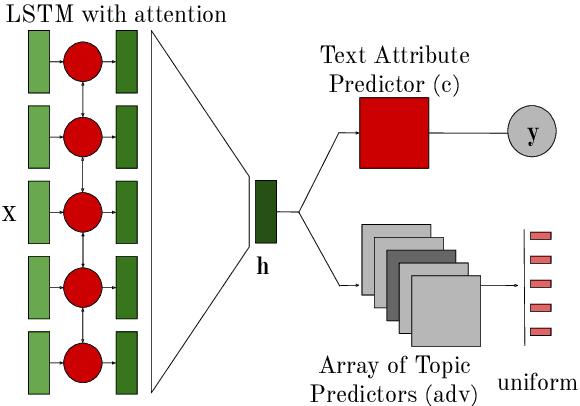

Despite impressive performance on many text classification tasks, deep neural networks tend to learn frequent superficial patterns that are specific to the training data and do not always generalize well. In this work, we observe this limitation with respect to the task of native language identification. We find that standard text classifiers which perform well on the test set end up learning topical features which are confounds of the prediction task (e.g., if the input text mentions Sweden, the classifier predicts that the author's native language is Swedish). We propose a method that represents the latent topical confounds and a model which "unlearns" confounding features by predicting both the label of the input text and the confound; but we train the two predictors adversarially in an alternating fashion to learn a text representation that predicts the correct label but is less prone to using information about the confound. We show that this model generalizes better and learns features that are indicative of the writing style rather than the content.