 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Framework for Understanding Sensitive Attribute Association Bias in Latent Factor Recommendation Algorithms
Oct 30, 2023



We present a novel evaluation framework for representation bias in latent factor recommendation (LFR) algorithms. Our framework introduces the concept of attribute association bias in recommendations allowing practitioners to explore how recommendation systems can introduce or amplify stakeholder representation harm. Attribute association bias (AAB) occurs when sensitive attributes become semantically captured or entangled in the trained recommendation latent space. This bias can result in the recommender reinforcing harmful stereotypes, which may result in downstream representation harms to system consumer and provider stakeholders. LFR models are at risk of experiencing AAB due to their ability to entangle explicit and implicit attributes into the trained latent space. Understanding this phenomenon is essential due to the increasingly common use of entity vectors as attributes in downstream components in hybrid industry recommendation systems. We provide practitioners with a framework for executing disaggregated evaluations of AAB within broader algorithmic auditing frameworks. Inspired by research in natural language processing (NLP) observing gender bias in word embeddings, our framework introduces AAB evaluation methods specifically for recommendation entity vectors. We present four evaluation strategies for sensitive AAB in LFR models: attribute bias directions, attribute association bias metrics, classification for explaining bias, and latent space visualization. We demonstrate the utility of our framework by evaluating user gender AAB regarding podcast genres with an industry case study of a production-level DNN recommendation model. We uncover significant levels of user gender AAB when user gender is used and removed as a model feature during training, pointing to the potential for systematic bias in LFR model outputs.
Parsing with Multilingual BERT, a Small Corpus, and a Small Treebank
Sep 29, 2020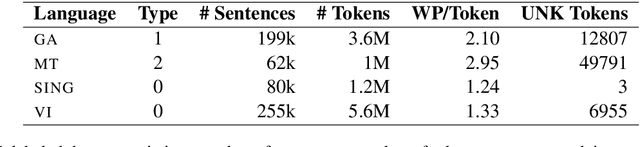
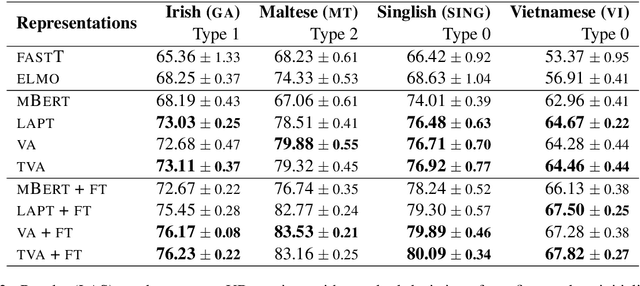
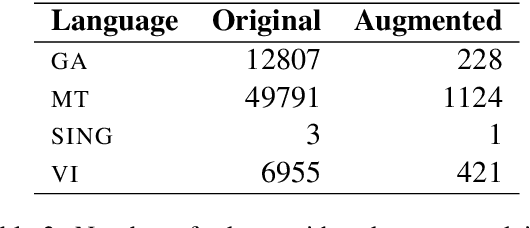
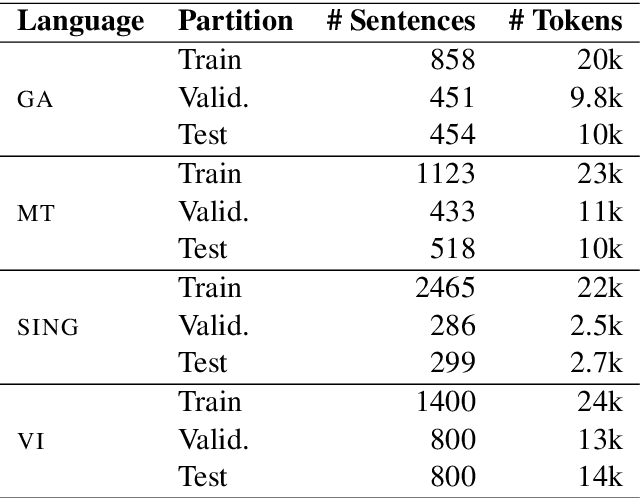
Pretrained multilingual contextual representations have shown great success, but due to the limits of their pretraining data, their benefits do not apply equally to all language varieties. This presents a challenge for language varieties unfamiliar to these models, whose labeled \emph{and unlabeled} data is too limited to train a monolingual model effectively. We propose the use of additional language-specific pretraining and vocabulary augmentation to adapt multilingual models to low-resource settings. Using dependency parsing of four diverse low-resource language varieties as a case study, we show that these methods significantly improve performance over baselines, especially in the lowest-resource cases, and demonstrate the importance of the relationship between such models' pretraining data and target language varieties.
Situating Sentence Embedders with Nearest Neighbor Overlap
Sep 24, 2019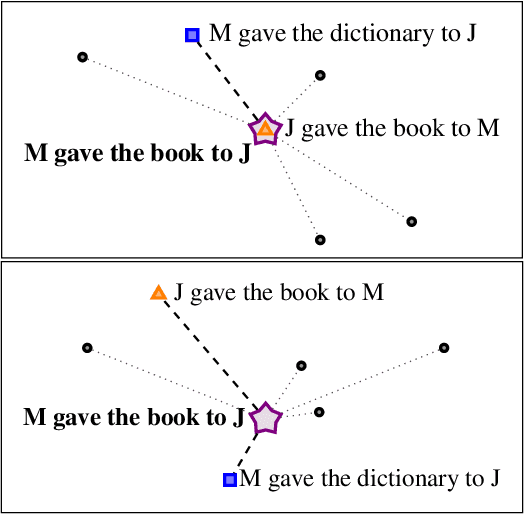
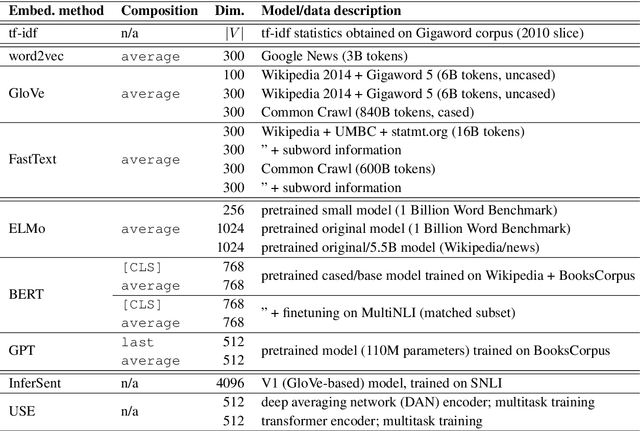
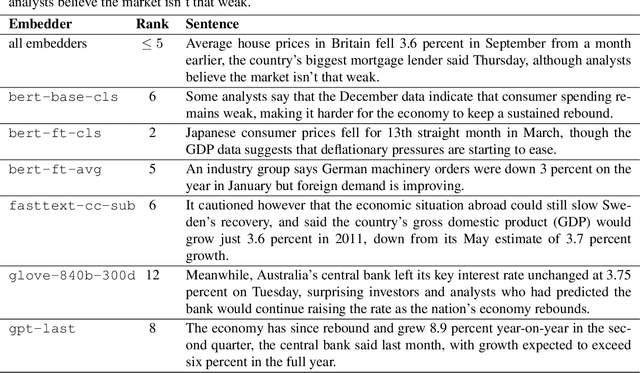
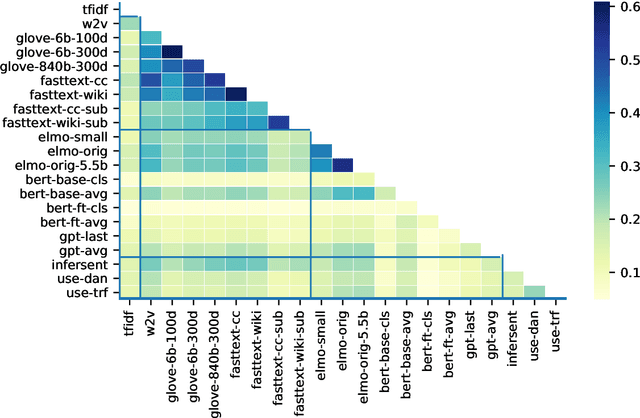
As distributed approaches to natural language semantics have developed and diversified, embedders for linguistic units larger than words have come to play an increasingly important role. To date, such embedders have been evaluated using benchmark tasks (e.g., GLUE) and linguistic probes. We propose a comparative approach, nearest neighbor overlap (N2O), that quantifies similarity between embedders in a task-agnostic manner. N2O requires only a collection of examples and is simple to understand: two embedders are more similar if, for the same set of inputs, there is greater overlap between the inputs' nearest neighbors. Though applicable to embedders of texts of any size, we focus on sentence embedders and use N2O to show the effects of different design choices and architectures.
Improving Natural Language Inference with a Pretrained Parser
Sep 18, 2019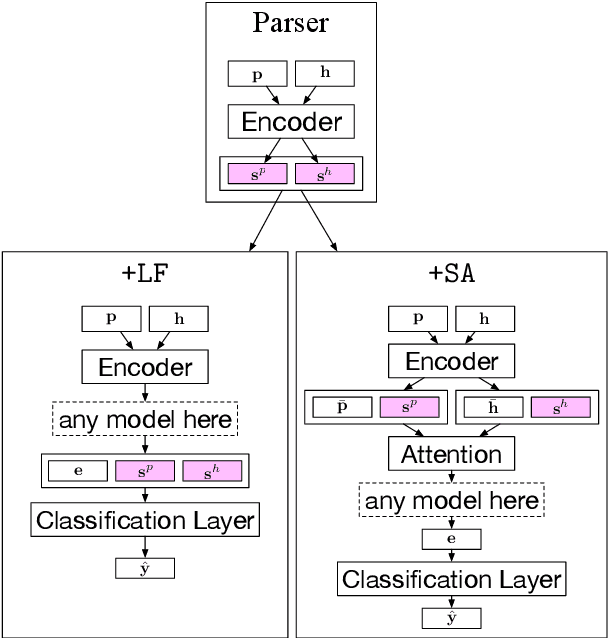
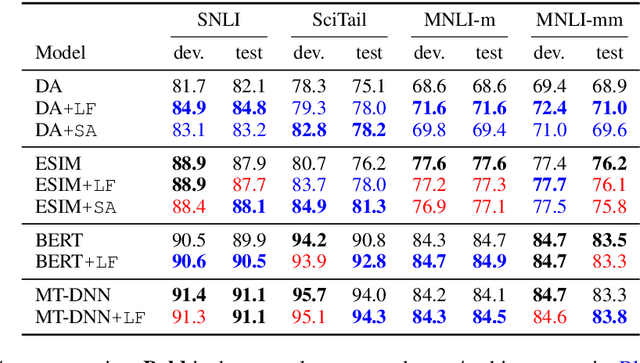
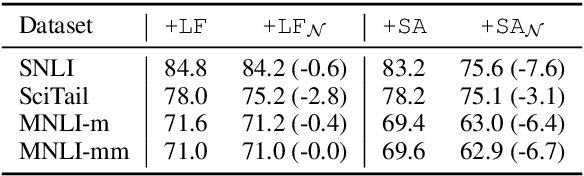
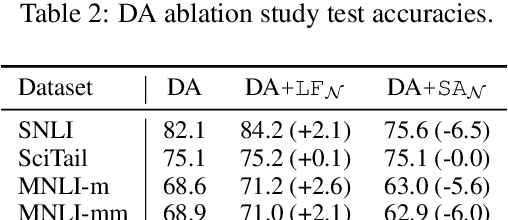
We introduce a novel approach to incorporate syntax into natural language inference (NLI) models. Our method uses contextual token-level vector representations from a pretrained dependency parser. Like other contextual embedders, our method is broadly applicable to any neural model. We experiment with four strong NLI models (decomposable attention model, ESIM, BERT, and MT-DNN), and show consistent benefit to accuracy across three NLI benchmarks.
Semantic Matching Against a Corpus: New Applications and Methods
Aug 28, 2018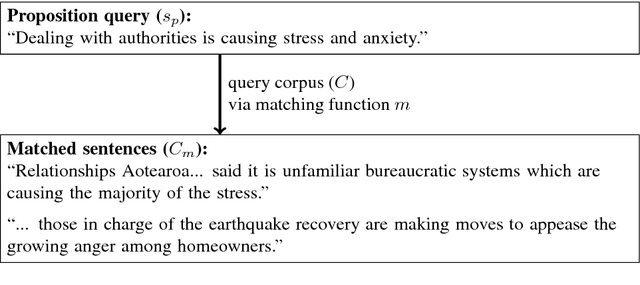

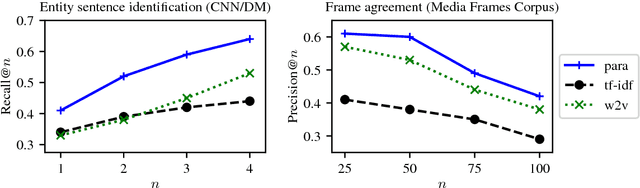
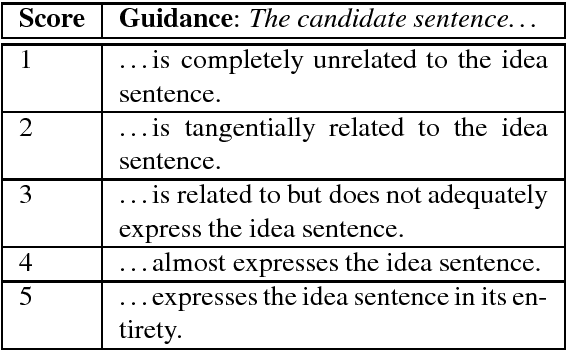
We consider the case of a domain expert who wishes to explore the extent to which a particular idea is expressed in a text collection. We propose the task of semantically matching the idea, expressed as a natural language proposition, against a corpus. We create two preliminary tasks derived from existing datasets, and then introduce a more realistic one on disaster recovery designed for emergency managers, whom we engaged in a user study. On the latter, we find that a new model built from natural language entailment data produces higher-quality matches than simple word-vector averaging, both on expert-crafted queries and on ones produced by the subjects themselves. This work provides a proof-of-concept for such applications of semantic matching and illustrates key challenges.