 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Iterative Reconstruction: One-Shot Universal Anomaly Detection
Mar 24, 2026Unsupervised medical anomaly detection is severely limited by the scarcity of normal training samples. Existing methods typically train dedicated models for each dataset or disease, requiring hundreds of normal images per task and lacking cross-modality generalization. We propose Semantic Iterative Reconstruction (SIR), a framework that enables a single universal model to detect anomalies across diverse medical domains using extremely few normal samples. SIR leverages a pretrained teacher encoder to extract multi-scale deep features and employs a compact up-then-down decoder with multi-loop iterative refinement to enforce robust normality priors in deep feature space. The framework adopts a one-shot universal design: a single model is trained by mixing exactly one normal sample from each of nine heterogeneous datasets, enabling effective anomaly detection on all corresponding test sets without task-specific retraining. Extensive experiments on nine medical benchmarks demonstrate that SIR achieves state-of-the-art under all four settings -- one-shot universal, full-shot universal, one-shot specialized, and full-shot specialized -- consistently outperforming previous methods. SIR offers an efficient and scalable solution for multi-domain clinical anomaly detection. Code is available at https://github.com/jusufzn212427/sir4ad.
RAM: Recover Any 3D Human Motion in-the-Wild
Mar 20, 2026RAM incorporates a motion-aware semantic tracker with adaptive Kalman filtering to achieve robust identity association under severe occlusions and dynamic interactions. A memory-augmented Temporal HMR module further enhances human motion reconstruction by injecting spatio-temporal priors for consistent and smooth motion estimation. Moreover, a lightweight Predictor module forecasts future poses to maintain reconstruction continuity, while a gated combiner adaptively fuses reconstructed and predicted features to ensure coherence and robustness. Experiments on in-the-wild multi-person benchmarks such as PoseTrack and 3DPW, demonstrate that RAM substantially outperforms previous state-of-the-art in both Zero-shot tracking stability and 3D accuracy, offering a generalizable paradigm for markerless 3D human motion capture in-the-wild.
ChatRadio-Valuer: A Chat Large Language Model for Generalizable Radiology Report Generation Based on Multi-institution and Multi-system Data
Oct 10, 2023



Radiology report generation, as a key step in medical image analysis, is critical to the quantitative analysis of clinically informed decision-making levels. However, complex and diverse radiology reports with cross-source heterogeneity pose a huge generalizability challenge to the current methods under massive data volume, mainly because the style and normativity of radiology reports are obviously distinctive among institutions, body regions inspected and radiologists. Recently, the advent of large language models (LLM) offers great potential for recognizing signs of health conditions. To resolve the above problem, we collaborate with the Second Xiangya Hospital in China and propose ChatRadio-Valuer based on the LLM, a tailored model for automatic radiology report generation that learns generalizable representations and provides a basis pattern for model adaptation in sophisticated analysts' cases. Specifically, ChatRadio-Valuer is trained based on the radiology reports from a single institution by means of supervised fine-tuning, and then adapted to disease diagnosis tasks for human multi-system evaluation (i.e., chest, abdomen, muscle-skeleton, head, and maxillofacial $\&$ neck) from six different institutions in clinical-level events. The clinical dataset utilized in this study encompasses a remarkable total of \textbf{332,673} observations. From the comprehensive results on engineering indicators, clinical efficacy and deployment cost metrics, it can be shown that ChatRadio-Valuer consistently outperforms state-of-the-art models, especially ChatGPT (GPT-3.5-Turbo) and GPT-4 et al., in terms of the diseases diagnosis from radiology reports. ChatRadio-Valuer provides an effective avenue to boost model generalization performance and alleviate the annotation workload of experts to enable the promotion of clinical AI applications in radiology reports.
Neural Architecture Search for Deep Face Recognition
Apr 26, 2019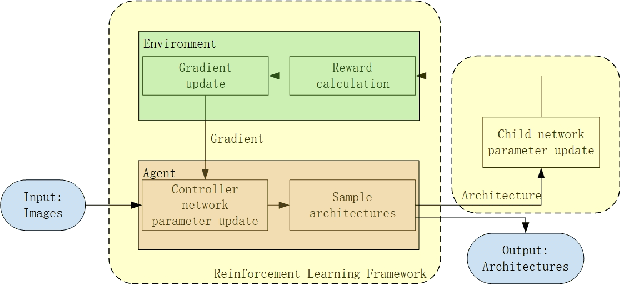

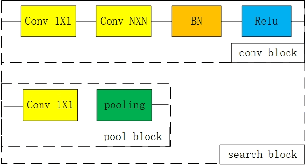

By the widespread popularity of electronic devices, the emergence of biometric technology has brought significant convenience to user authentication compared with the traditional password and mode unlocking. Among many biological characteristics, the face is a universal and irreplaceable feature that does not need too much cooperation and can significantly improve the user's experience at the same time. Face recognition is one of the main functions of electronic equipment propaganda. Hence it's virtually worth researching in computer vision. Previous work in this field has focused on two directions: converting loss function to improve recognition accuracy in traditional deep convolution neural networks (Resnet); combining the latest loss function with the lightweight system (MobileNet) to reduce network size at the minimal expense of accuracy. But none of these has changed the network structure. With the development of AutoML, neural architecture search (NAS) has shown excellent performance in the benchmark of image classification. In this paper, we integrate NAS technology into face recognition to customize a more suitable network. We quote the framework of neural architecture search which trains child and controller network alternately. At the same time, we mutate NAS by incorporating evaluation latency into rewards of reinforcement learning and utilize policy gradient algorithm to search the architecture automatically with the most classical cross-entropy loss. The network architectures we searched out have got state-of-the-art accuracy in the large-scale face dataset, which achieves 98.77% top-1 in MS-Celeb-1M and 99.89% in LFW with relatively small network size. To the best of our knowledge, this proposal is the first attempt to use NAS to solve the problem of Deep Face Recognition and achieve the best results in this domain.