 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Label-Correlation Enhancement for Congestion Prediction
Aug 01, 2023The physical design process of large-scale designs is a time-consuming task, often requiring hours to days to complete, with routing being the most critical and complex step. As the the complexity of Integrated Circuits (ICs) increases, there is an increased demand for accurate routing quality prediction. Accurate congestion prediction aids in identifying design flaws early on, thereby accelerating circuit design and conserving resources. Despite the advancements in current congestion prediction methodologies, an essential aspect that has been largely overlooked is the spatial label-correlation between different grids in congestion prediction. The spatial label-correlation is a fundamental characteristic of circuit design, where the congestion status of a grid is not isolated but inherently influenced by the conditions of its neighboring grids. In order to fully exploit the inherent spatial label-correlation between neighboring grids, we propose a novel approach, {\ours}, i.e., VAriational Label-Correlation Enhancement for Congestion Prediction, which considers the local label-correlation in the congestion map, associating the estimated congestion value of each grid with a local label-correlation weight influenced by its surrounding grids. {\ours} leverages variational inference techniques to estimate this weight, thereby enhancing the regression model's performance by incorporating spatial dependencies. Experiment results validate the superior effectiveness of {\ours} on the public available \texttt{ISPD2011} and \texttt{DAC2012} benchmarks using the superblue circuit line.
Towards Effective Visual Representations for Partial-Label Learning
May 10, 2023Under partial-label learning (PLL) where, for each training instance, only a set of ambiguous candidate labels containing the unknown true label is accessible, contrastive learning has recently boosted the performance of PLL on vision tasks, attributed to representations learned by contrasting the same/different classes of entities. Without access to true labels, positive points are predicted using pseudo-labels that are inherently noisy, and negative points often require large batches or momentum encoders, resulting in unreliable similarity information and a high computational overhead. In this paper, we rethink a state-of-the-art contrastive PLL method PiCO[24], inspiring the design of a simple framework termed PaPi (Partial-label learning with a guided Prototypical classifier), which demonstrates significant scope for improvement in representation learning, thus contributing to label disambiguation. PaPi guides the optimization of a prototypical classifier by a linear classifier with which they share the same feature encoder, thus explicitly encouraging the representation to reflect visual similarity between categories. It is also technically appealing, as PaPi requires only a few components in PiCO with the opposite direction of guidance, and directly eliminates the contrastive learning module that would introduce noise and consume computational resources. We empirically demonstrate that PaPi significantly outperforms other PLL methods on various image classification tasks.
Scalable Multiple Patterning Layout Decomposition Implemented by a Distribution Evolutionary Algorithm
Apr 09, 2023As the feature size of semiconductor technology shrinks to 10 nm and beyond, the multiple patterning lithography (MPL) attracts more attention from the industry. In this paper, we model the layout decomposition of MPL as a generalized graph coloring problem, which is addressed by a distribution evolutionary algorithm based on a population of probabilistic model (DEA-PPM). DEA-PPM can strike a balance between decomposition results and running time, being scalable for varied settings of mask number and lithography resolution. Due to its robustness of decomposition results, this could be an alternative technique for multiple patterning layout decomposition in next-generation technology nodes.
Unreliable Partial Label Learning with Recursive Separation
Feb 20, 2023Partial label learning (PLL) is a typical weakly supervised learning problem in which each instance is associated with a candidate label set, and among which only one is true. However, the assumption that the ground-truth label is always among the candidate label set would be unrealistic, as the reliability of the candidate label sets in real-world applications cannot be guaranteed by annotators. Therefore, a generalized PLL named Unreliable Partial Label Learning (UPLL) is proposed, in which the true label may not be in the candidate label set. Due to the challenges posed by unreliable labeling, previous PLL methods will experience a marked decline in performance when applied to UPLL. To address the issue, we propose a two-stage framework named Unreliable Partial Label Learning with Recursive Separation (UPLLRS). In the first stage, the self-adaptive recursive separation strategy is proposed to separate the training set into a reliable subset and an unreliable subset. In the second stage, a disambiguation strategy is employed to progressively identify the ground-truth labels in the reliable subset. Simultaneously, semi-supervised learning methods are adopted to extract valuable information from the unreliable subset. Our method demonstrates state-of-the-art performance as evidenced by experimental results, particularly in situations of high unreliability.
Learning From Biased Soft Labels
Feb 16, 2023



Knowledge distillation has been widely adopted in a variety of tasks and has achieved remarkable successes. Since its inception, many researchers have been intrigued by the dark knowledge hidden in the outputs of the teacher model. Recently, a study has demonstrated that knowledge distillation and label smoothing can be unified as learning from soft labels. Consequently, how to measure the effectiveness of the soft labels becomes an important question. Most existing theories have stringent constraints on the teacher model or data distribution, and many assumptions imply that the soft labels are close to the ground-truth labels. This paper studies whether biased soft labels are still effective. We present two more comprehensive indicators to measure the effectiveness of such soft labels. Based on the two indicators, we give sufficient conditions to ensure biased soft label based learners are classifier-consistent and ERM learnable. The theory is applied to three weakly-supervised frameworks. Experimental results validate that biased soft labels can also teach good students, which corroborates the soundness of the theory.
CVM-Cervix: A Hybrid Cervical Pap-Smear Image Classification Framework Using CNN, Visual Transformer and Multilayer Perceptron
Jun 02, 2022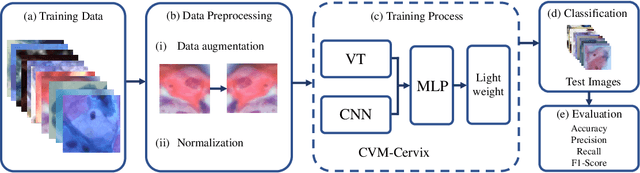
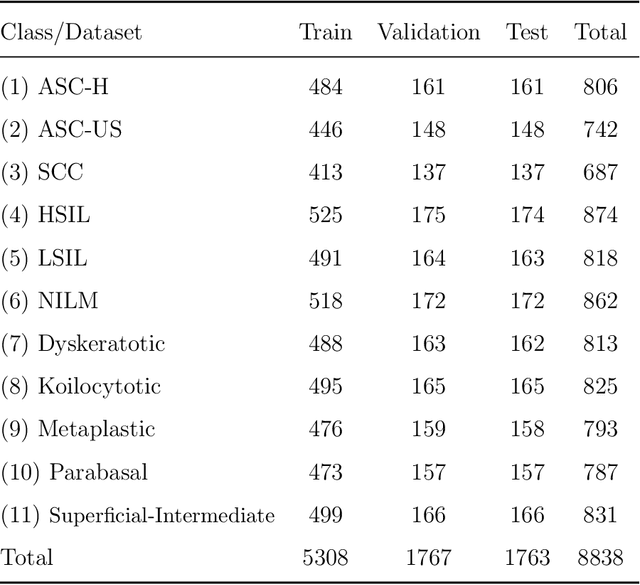
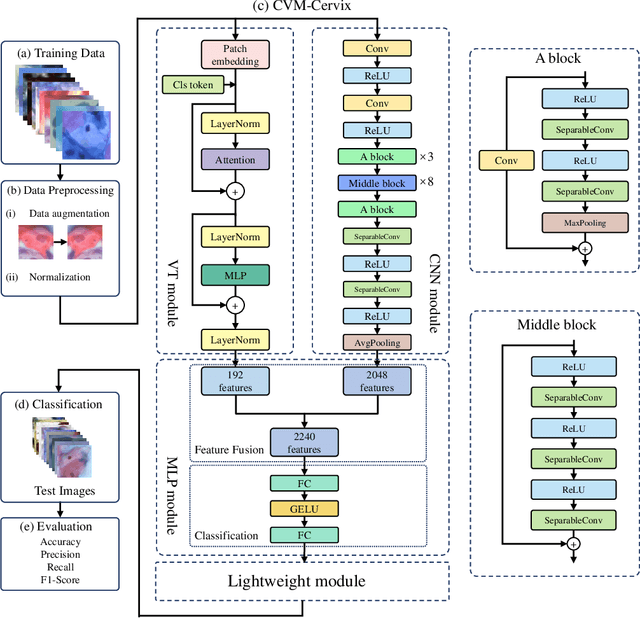
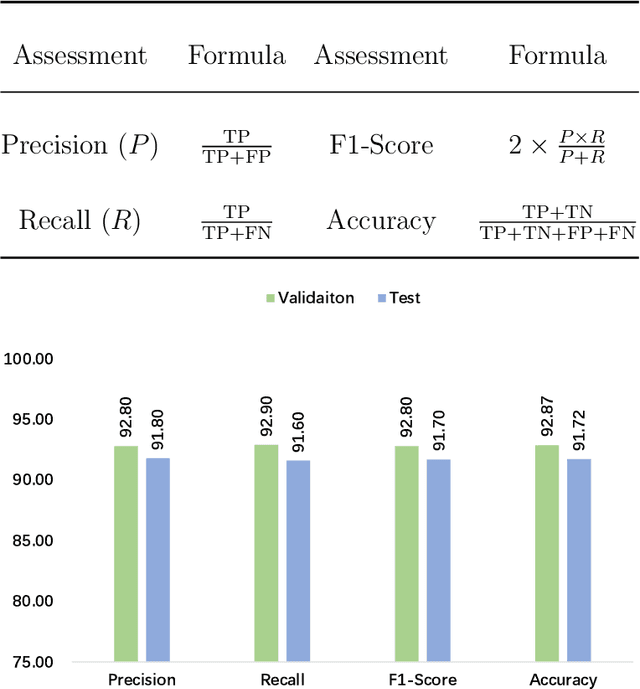
Cervical cancer is the seventh most common cancer among all the cancers worldwide and the fourth most common cancer among women. Cervical cytopathology image classification is an important method to diagnose cervical cancer. Manual screening of cytopathology images is time-consuming and error-prone. The emergence of the automatic computer-aided diagnosis system solves this problem. This paper proposes a framework called CVM-Cervix based on deep learning to perform cervical cell classification tasks. It can analyze pap slides quickly and accurately. CVM-Cervix first proposes a Convolutional Neural Network module and a Visual Transformer module for local and global feature extraction respectively, then a Multilayer Perceptron module is designed to fuse the local and global features for the final classification. Experimental results show the effectiveness and potential of the proposed CVM-Cervix in the field of cervical Pap smear image classification. In addition, according to the practical needs of clinical work, we perform a lightweight post-processing to compress the model.
Progressive Purification for Instance-Dependent Partial Label Learning
Jun 02, 2022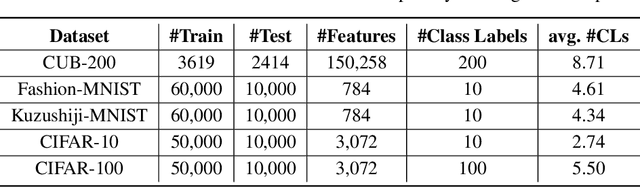
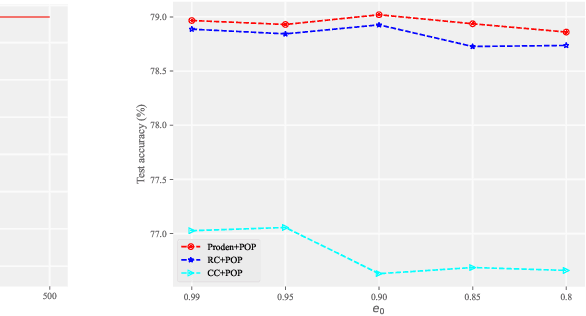
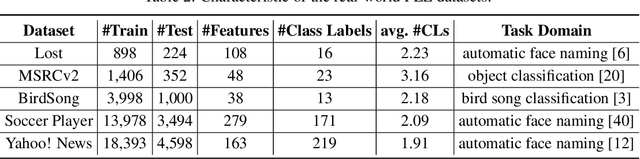
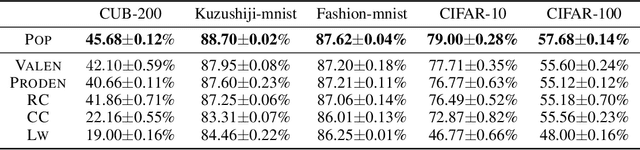
Partial label learning (PLL) aims to train multi-class classifiers from instances with partial labels (PLs)-a PL for an instance is a set of candidate labels where a fixed but unknown candidate is the true label. In the last few years, the instance-independent generation process of PLs has been extensively studied, on the basis of which many practical and theoretical advances have been made in PLL, whereas relatively less attention has been paid to the practical setting of instance-dependent PLs, namely, the PL depends not only on the true label but the instance itself. In this paper, we propose a theoretically grounded and practically effective approach called PrOgressive Purification (POP) for instance-dependent PLL: in each epoch, POP updates the learning model while purifying each PL for the next epoch of the model training by progressively moving out false candidate labels. Theoretically, we prove that POP enlarges the region appropriately fast where the model is reliable, and eventually approximates the Bayes optimal classifier with mild assumptions; technically, POP is flexible with arbitrary losses and compatible with deep networks, so that the previous advanced PLL losses can be embedded in it and the performance is often significantly improved.
One Positive Label is Sufficient: Single-Positive Multi-Label Learning with Label Enhancement
Jun 01, 2022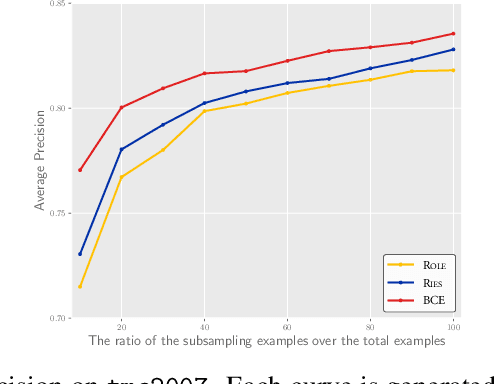
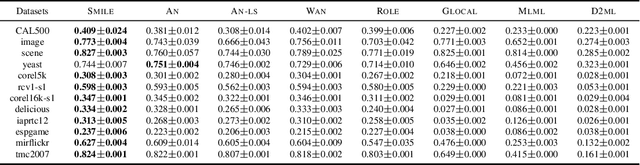
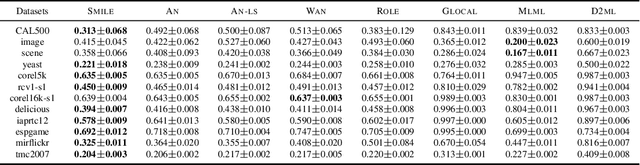

Multi-label learning (MLL) learns from the examples each associated with multiple labels simultaneously, where the high cost of annotating all relevant labels for each training example is challenging for real-world applications. To cope with the challenge, we investigate single-positive multi-label learning (SPMLL) where each example is annotated with only one relevant label and show that one can successfully learn a theoretically grounded multi-label classifier for the problem. In this paper, a novel SPMLL method named {\proposed}, i.e., Single-positive MultI-label learning with Label Enhancement, is proposed. Specifically, an unbiased risk estimator is derived, which could be guaranteed to approximately converge to the optimal risk minimizer of fully supervised learning and shows that one positive label of each instance is sufficient to train the predictive model. Then, the corresponding empirical risk estimator is established via recovering the latent soft label as a label enhancement process, where the posterior density of the latent soft labels is approximate to the variational Beta density parameterized by an inference model. Experiments on benchmark datasets validate the effectiveness of the proposed method.
Decomposition-based Generation Process for Instance-Dependent Partial Label Learning
Apr 08, 2022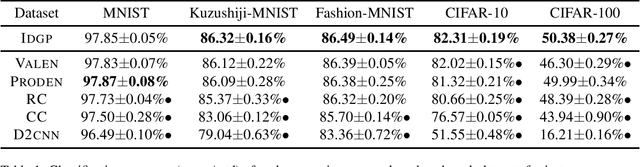

Partial label learning (PLL) is a typical weakly supervised learning problem, where each training example is associated with a set of candidate labels among which only one is true. Most existing PLL approaches assume that the incorrect labels in each training example are randomly picked as the candidate labels and model the generation process of the candidate labels in a simple way. However, these approaches usually do not perform as well as expected due to the fact that the generation process of the candidate labels is always instance-dependent. Therefore, it deserves to be modeled in a refined way. In this paper, we consider instance-dependent PLL and assume that the generation process of the candidate labels could decompose into two sequential parts, where the correct label emerges first in the mind of the annotator but then the incorrect labels related to the feature are also selected with the correct label as candidate labels due to uncertainty of labeling. Motivated by this consideration, we propose a novel PLL method that performs Maximum A Posterior(MAP) based on an explicitly modeled generation process of candidate labels via decomposed probability distribution models. Experiments on benchmark and real-world datasets validate the effectiveness of the proposed method.
An application of Pixel Interval Down-sampling (PID) for dense tiny microorganism counting on environmental microorganism images
Apr 04, 2022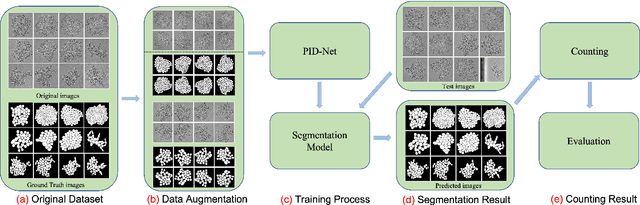

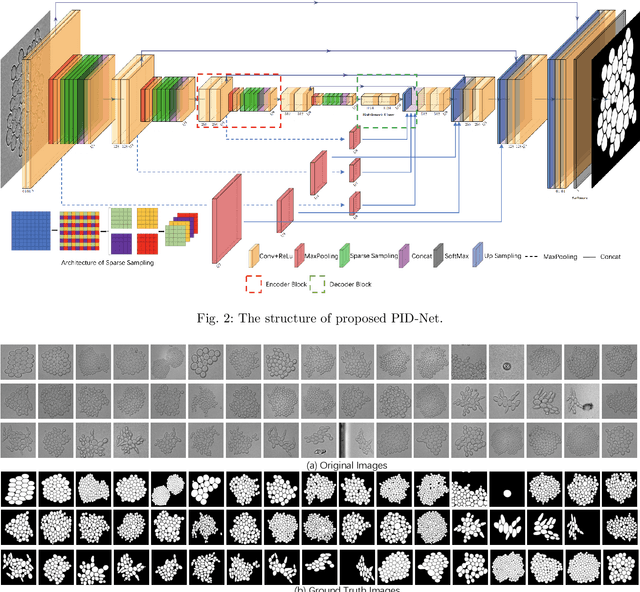
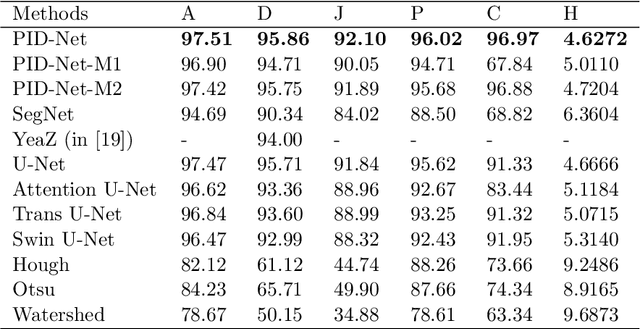
This paper proposes a novel pixel interval down-sampling network (PID-Net) for dense tiny objects (yeast cells) counting tasks with higher accuracy. The PID-Net is an end-to-end CNN model with encoder to decoder architecture. The pixel interval down-sampling operations are concatenated with max-pooling operations to combine the sparse and dense features. It addresses the limitation of contour conglutination of dense objects while counting. Evaluation was done using classical segmentation metrics (Dice, Jaccard, Hausdorff distance) as well as counting metrics. Experimental result shows that the proposed PID-Net has the best performance and potential for dense tiny objects counting tasks, which achieves 96.97% counting accuracy on the dataset with 2448 yeast cell images. By comparing with the state-of-the-art approaches like Attention U-Net, Swin U-Net and Trans U-Net, the proposed PID-Net can segment the dense tiny objects with clearer boundaries and fewer incorrect debris, which shows the great potential of PID-Net in the task of accurate counting tasks.