 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Extrinsic Contact and In-Hand Pose Estimation via Distributed Tactile Sensing
Dec 29, 2025Prehensile autonomous manipulation, such as peg insertion, tool use, or assembly, require precise in-hand understanding of the object pose and the extrinsic contacts made during interactions. Providing accurate estimation of pose and contacts is challenging. Tactile sensors can provide local geometry at the sensor and force information about the grasp, but the locality of sensing means resolving poses and contacts from tactile alone is often an ill-posed problem, as multiple configurations can be consistent with the observations. Adding visual feedback can help resolve ambiguities, but can suffer from noise and occlusions. In this work, we propose a method that pairs local observations from sensing with the physical constraints of contact. We propose a set of factors that ensure local consistency with tactile observations as well as enforcing physical plausibility, namely, that the estimated pose and contacts must respect the kinematic and force constraints of quasi-static rigid body interactions. We formalize our problem as a factor graph, allowing for efficient estimation. In our experiments, we demonstrate that our method outperforms existing geometric and contact-informed estimation pipelines, especially when only tactile information is available. Video results can be found at https://tacgraph.github.io/.
Hydrosoft: Non-Holonomic Hydroelastic Models for Compliant Tactile Manipulation
Sep 16, 2025



Tactile sensors have long been valued for their perceptual capabilities, offering rich insights into the otherwise hidden interface between the robot and grasped objects. Yet their inherent compliance -- a key driver of force-rich interactions -- remains underexplored. The central challenge is to capture the complex, nonlinear dynamics introduced by these passive-compliant elements. Here, we present a computationally efficient non-holonomic hydroelastic model that accurately models path-dependent contact force distributions and dynamic surface area variations. Our insight is to extend the object's state space, explicitly incorporating the distributed forces generated by the compliant sensor. Our differentiable formulation not only accounts for path-dependent behavior but also enables gradient-based trajectory optimization, seamlessly integrating with high-resolution tactile feedback. We demonstrate the effectiveness of our approach across a range of simulated and real-world experiments and highlight the importance of modeling the path dependence of sensor dynamics.
AimBot: A Simple Auxiliary Visual Cue to Enhance Spatial Awareness of Visuomotor Policies
Aug 11, 2025In this paper, we propose AimBot, a lightweight visual augmentation technique that provides explicit spatial cues to improve visuomotor policy learning in robotic manipulation. AimBot overlays shooting lines and scope reticles onto multi-view RGB images, offering auxiliary visual guidance that encodes the end-effector's state. The overlays are computed from depth images, camera extrinsics, and the current end-effector pose, explicitly conveying spatial relationships between the gripper and objects in the scene. AimBot incurs minimal computational overhead (less than 1 ms) and requires no changes to model architectures, as it simply replaces original RGB images with augmented counterparts. Despite its simplicity, our results show that AimBot consistently improves the performance of various visuomotor policies in both simulation and real-world settings, highlighting the benefits of spatially grounded visual feedback.
ViTaSCOPE: Visuo-tactile Implicit Representation for In-hand Pose and Extrinsic Contact Estimation
Jun 13, 2025Mastering dexterous, contact-rich object manipulation demands precise estimation of both in-hand object poses and external contact locations$\unicode{x2013}$tasks particularly challenging due to partial and noisy observations. We present ViTaSCOPE: Visuo-Tactile Simultaneous Contact and Object Pose Estimation, an object-centric neural implicit representation that fuses vision and high-resolution tactile feedback. By representing objects as signed distance fields and distributed tactile feedback as neural shear fields, ViTaSCOPE accurately localizes objects and registers extrinsic contacts onto their 3D geometry as contact fields. Our method enables seamless reasoning over complementary visuo-tactile cues by leveraging simulation for scalable training and zero-shot transfers to the real-world by bridging the sim-to-real gap. We evaluate our method through comprehensive simulated and real-world experiments, demonstrating its capabilities in dexterous manipulation scenarios.
Vib2Move: In-Hand Object Reconfiguration via Fingertip Micro-Vibrations
Jun 12, 2025We introduce Vib2Move, a novel approach for in-hand object reconfiguration that uses fingertip micro-vibrations and gravity to precisely reposition planar objects. Our framework comprises three key innovations. First, we design a vibration-based actuator that dynamically modulates the effective finger-object friction coefficient, effectively emulating changes in gripping force. Second, we derive a sliding motion model for objects clamped in a parallel gripper with two symmetric, variable-friction contact patches. Third, we propose a motion planner that coordinates end-effector finger trajectories and fingertip vibrations to achieve the desired object pose. In real-world trials, Vib2Move consistently yields final positioning errors below 6 mm, demonstrating reliable, high-precision manipulation across a variety of planar objects. For more results and information, please visit https://vib2move.github.io.
Estimating Deformable-Rigid Contact Interactions for a Deformable Tool via Learning and Model-Based Optimization
May 16, 2025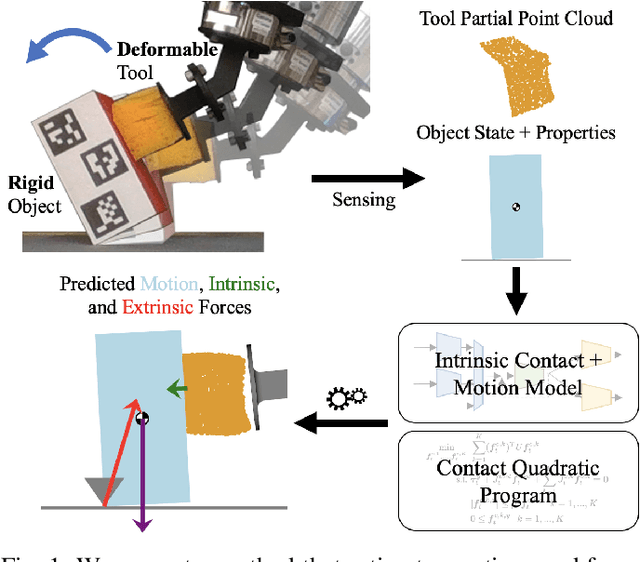
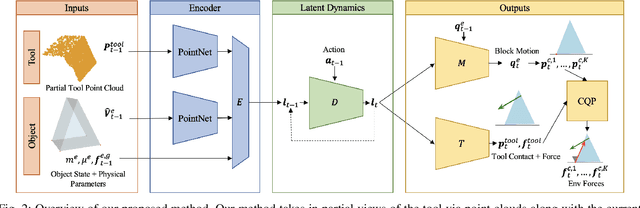
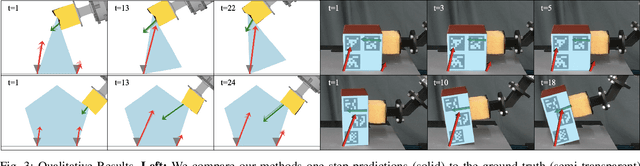
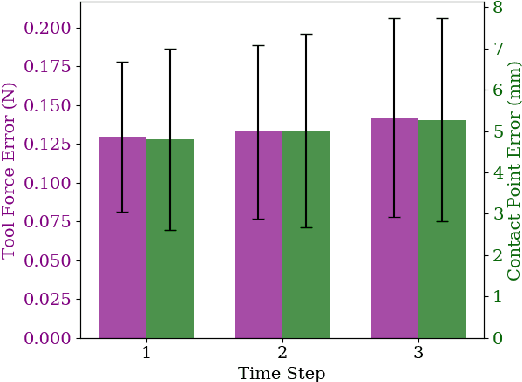
Dexterous manipulation requires careful reasoning over extrinsic contacts. The prevalence of deforming tools in human environments, the use of deformable sensors, and the increasing number of soft robots yields a need for approaches that enable dexterous manipulation through contact reasoning where not all contacts are well characterized by classical rigid body contact models. Here, we consider the case of a deforming tool dexterously manipulating a rigid object. We propose a hybrid learning and first-principles approach to the modeling of simultaneous motion and force transfer of tools and objects. The learned module is responsible for jointly estimating the rigid object's motion and the deformable tool's imparted contact forces. We then propose a Contact Quadratic Program to recover forces between the environment and object subject to quasi-static equilibrium and Coulomb friction. The results is a system capable of modeling both intrinsic and extrinsic motions, contacts, and forces during dexterous deformable manipulation. We train our method in simulation and show that our method outperforms baselines under varying block geometries and physical properties, during pushing and pivoting manipulations, and demonstrate transfer to real world interactions. Video results can be found at https://deform-rigid-contact.github.io/.
ViSA-Flow: Accelerating Robot Skill Learning via Large-Scale Video Semantic Action Flow
May 02, 2025



One of the central challenges preventing robots from acquiring complex manipulation skills is the prohibitive cost of collecting large-scale robot demonstrations. In contrast, humans are able to learn efficiently by watching others interact with their environment. To bridge this gap, we introduce semantic action flow as a core intermediate representation capturing the essential spatio-temporal manipulator-object interactions, invariant to superficial visual differences. We present ViSA-Flow, a framework that learns this representation self-supervised from unlabeled large-scale video data. First, a generative model is pre-trained on semantic action flows automatically extracted from large-scale human-object interaction video data, learning a robust prior over manipulation structure. Second, this prior is efficiently adapted to a target robot by fine-tuning on a small set of robot demonstrations processed through the same semantic abstraction pipeline. We demonstrate through extensive experiments on the CALVIN benchmark and real-world tasks that ViSA-Flow achieves state-of-the-art performance, particularly in low-data regimes, outperforming prior methods by effectively transferring knowledge from human video observation to robotic execution. Videos are available at https://visaflow-web.github.io/ViSAFLOW.
Neural Inverse Source Problems
Nov 03, 2024



Reconstructing unknown external source functions is an important perception capability for a large range of robotics domains including manipulation, aerial, and underwater robotics. In this work, we propose a Physics-Informed Neural Network (PINN [1]) based approach for solving the inverse source problems in robotics, jointly identifying unknown source functions and the complete state of a system given partial and noisy observations. Our approach demonstrates several advantages over prior works (Finite Element Methods (FEM) and data-driven approaches): it offers flexibility in integrating diverse constraints and boundary conditions; eliminates the need for complex discretizations (e.g., meshing); easily accommodates gradients from real measurements; and does not limit performance based on the diversity and quality of training data. We validate our method across three simulation and real-world scenarios involving up to 4th order partial differential equations (PDEs), constraints such as Signorini and Dirichlet, and various regression losses including Chamfer distance and L2 norm.
Contrastive Touch-to-Touch Pretraining
Oct 15, 2024



Today's tactile sensors have a variety of different designs, making it challenging to develop general-purpose methods for processing touch signals. In this paper, we learn a unified representation that captures the shared information between different tactile sensors. Unlike current approaches that focus on reconstruction or task-specific supervision, we leverage contrastive learning to integrate tactile signals from two different sensors into a shared embedding space, using a dataset in which the same objects are probed with multiple sensors. We apply this approach to paired touch signals from GelSlim and Soft Bubble sensors. We show that our learned features provide strong pretraining for downstream pose estimation and classification tasks. We also show that our embedding enables models trained using one touch sensor to be deployed using another without additional training. Project details can be found at https://www.mmintlab.com/research/cttp/.
GelSlim 4.0: Focusing on Touch and Reproducibility
Sep 29, 2024



Tactile sensing provides robots with rich feedback during manipulation, enabling a host of perception and controls capabilities. Here, we present a new open-source, vision-based tactile sensor designed to promote reproducibility and accessibility across research and hobbyist communities. Building upon the GelSlim 3.0 sensor, our design features two key improvements: a simplified, modifiable finger structure and easily manufacturable lenses. To complement the hardware, we provide an open-source perception library that includes depth and shear field estimation algorithms to enable in-hand pose estimation, slip detection, and other manipulation tasks. Our sensor is accompanied by comprehensive manufacturing documentation, ensuring the design can be readily produced by users with varying levels of expertise. We validate the sensor's reproducibility through extensive human usability testing. For documentation, code, and data, please visit the project website: https://www.mmintlab.com/research/gelslim-4-0/