 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSF: Neural Surface Fields for Human Modeling from Monocular Depth
Aug 30, 2023



Obtaining personalized 3D animatable avatars from a monocular camera has several real world applications in gaming, virtual try-on, animation, and VR/XR, etc. However, it is very challenging to model dynamic and fine-grained clothing deformations from such sparse data. Existing methods for modeling 3D humans from depth data have limitations in terms of computational efficiency, mesh coherency, and flexibility in resolution and topology. For instance, reconstructing shapes using implicit functions and extracting explicit meshes per frame is computationally expensive and cannot ensure coherent meshes across frames. Moreover, predicting per-vertex deformations on a pre-designed human template with a discrete surface lacks flexibility in resolution and topology. To overcome these limitations, we propose a novel method `\keyfeature: Neural Surface Fields' for modeling 3D clothed humans from monocular depth. NSF defines a neural field solely on the base surface which models a continuous and flexible displacement field. NSF can be adapted to the base surface with different resolution and topology without retraining at inference time. Compared to existing approaches, our method eliminates the expensive per-frame surface extraction while maintaining mesh coherency, and is capable of reconstructing meshes with arbitrary resolution without retraining. To foster research in this direction, we release our code in project page at: https://yuxuan-xue.com/nsf.
VIVE3D: Viewpoint-Independent Video Editing using 3D-Aware GANs
Mar 28, 2023We introduce VIVE3D, a novel approach that extends the capabilities of image-based 3D GANs to video editing and is able to represent the input video in an identity-preserving and temporally consistent way. We propose two new building blocks. First, we introduce a novel GAN inversion technique specifically tailored to 3D GANs by jointly embedding multiple frames and optimizing for the camera parameters. Second, besides traditional semantic face edits (e.g. for age and expression), we are the first to demonstrate edits that show novel views of the head enabled by the inherent properties of 3D GANs and our optical flow-guided compositing technique to combine the head with the background video. Our experiments demonstrate that VIVE3D generates high-fidelity face edits at consistent quality from a range of camera viewpoints which are composited with the original video in a temporally and spatially consistent manner.
Pose-NDF: Modeling Human Pose Manifolds with Neural Distance Fields
Jul 27, 2022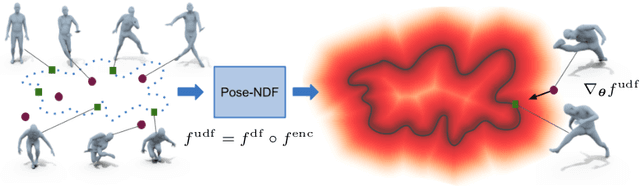
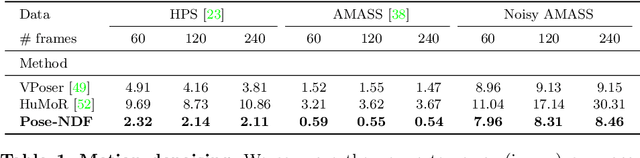
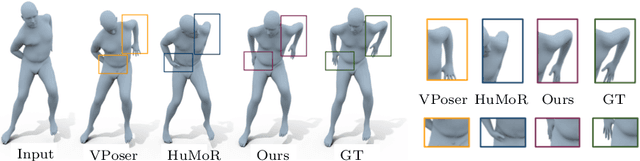
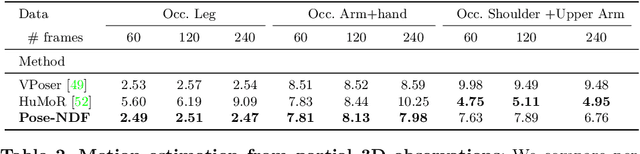
We present Pose-NDF, a continuous model for plausible human poses based on neural distance fields (NDFs). Pose or motion priors are important for generating realistic new poses and for reconstructing accurate poses from noisy or partial observations. Pose-NDF learns a manifold of plausible poses as the zero level set of a neural implicit function, extending the idea of modeling implicit surfaces in 3D to the high-dimensional domain SO(3)^K, where a human pose is defined by a single data point, represented by K quaternions. The resulting high-dimensional implicit function can be differentiated with respect to the input poses and thus can be used to project arbitrary poses onto the manifold by using gradient descent on the set of 3-dimensional hyperspheres. In contrast to previous VAE-based human pose priors, which transform the pose space into a Gaussian distribution, we model the actual pose manifold, preserving the distances between poses. We demonstrate that PoseNDF outperforms existing state-of-the-art methods as a prior in various downstream tasks, ranging from denoising real-world human mocap data, pose recovery from occluded data to 3D pose reconstruction from images. Furthermore, we show that it can be used to generate more diverse poses by random sampling and projection than VAE-based methods.
* Project page: https://virtualhumans.mpi-inf.mpg.de/posendf
BodyMap: Learning Full-Body Dense Correspondence Map
May 18, 2022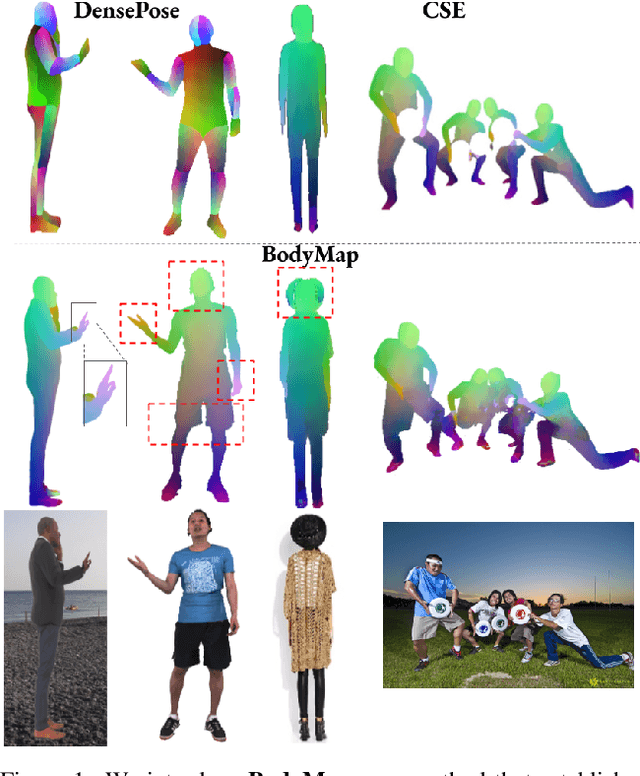
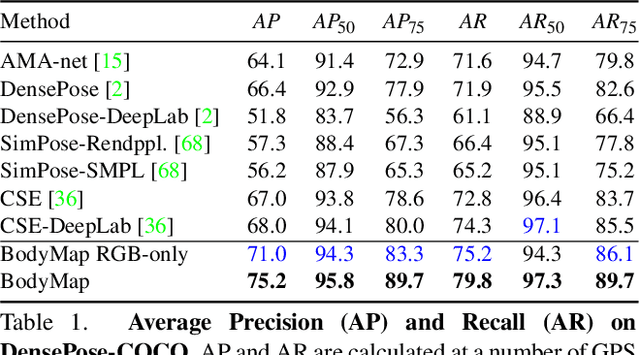
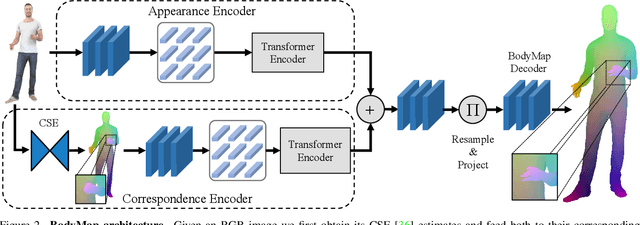
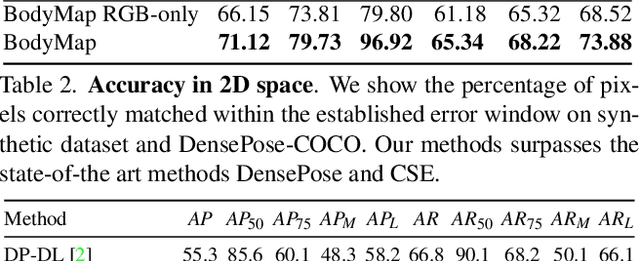
Dense correspondence between humans carries powerful semantic information that can be utilized to solve fundamental problems for full-body understanding such as in-the-wild surface matching, tracking and reconstruction. In this paper we present BodyMap, a new framework for obtaining high-definition full-body and continuous dense correspondence between in-the-wild images of clothed humans and the surface of a 3D template model. The correspondences cover fine details such as hands and hair, while capturing regions far from the body surface, such as loose clothing. Prior methods for estimating such dense surface correspondence i) cut a 3D body into parts which are unwrapped to a 2D UV space, producing discontinuities along part seams, or ii) use a single surface for representing the whole body, but none handled body details. Here, we introduce a novel network architecture with Vision Transformers that learn fine-level features on a continuous body surface. BodyMap outperforms prior work on various metrics and datasets, including DensePose-COCO by a large margin. Furthermore, we show various applications ranging from multi-layer dense cloth correspondence, neural rendering with novel-view synthesis and appearance swapping.
Animatable Neural Radiance Fields from Monocular RGB-D
Apr 04, 2022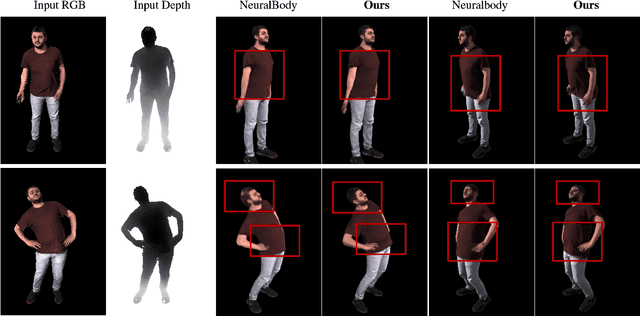
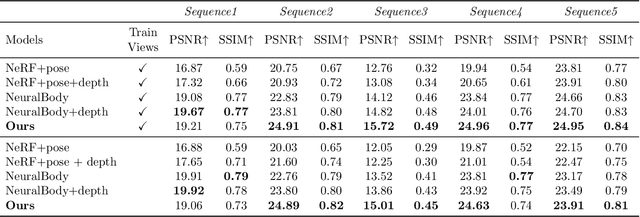
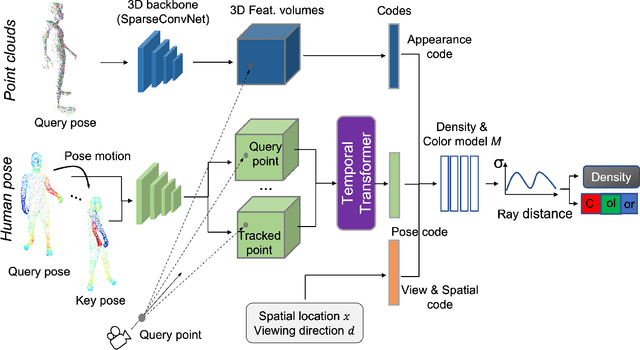

This paper aims at representing animatable photo-realistic humans under novel views and poses. Recent work has shown significant progress with dynamic scenes by exploring shared canonical neural radiance fields. However learning a user-controlled model for novel poses remains a challenging task. To tackle this problem, we introduce a novel method to integrate observations across frames and encode the appearance at each individual frame by utilizing the human pose that models the body shape and point clouds which cover partial part of the human as the input. Specifically, our method simultaneously learns a shared set of latent codes anchored to the human pose among frames, and learns an appearance-dependent code anchored to incomplete point clouds generated by monocular RGB-D at each frame. A human pose-based code models the shape of the performer whereas a point cloud based code predicts details and reasons about missing structures at the unseen poses. To further recover non-visible regions in query frames, we utilize a temporal transformer to integrate features of points in query frames and tracked body points from automatically-selected key frames. Experiments on various sequences of humans in motion show that our method significantly outperforms existing works under unseen poses and novel views given monocular RGB-D videos as input.
SPAMs: Structured Implicit Parametric Models
Jan 20, 2022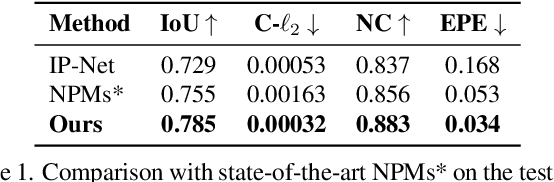
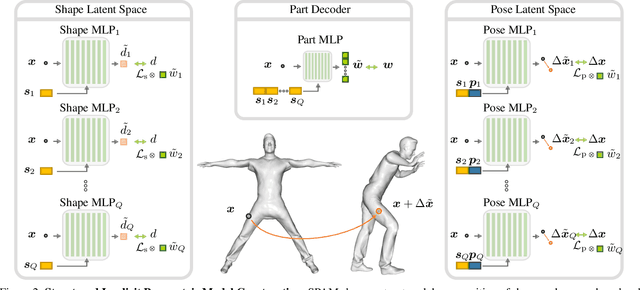
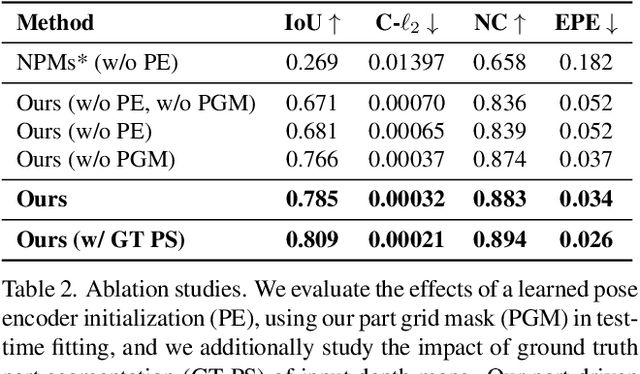

Parametric 3D models have formed a fundamental role in modeling deformable objects, such as human bodies, faces, and hands; however, the construction of such parametric models requires significant manual intervention and domain expertise. Recently, neural implicit 3D representations have shown great expressibility in capturing 3D shape geometry. We observe that deformable object motion is often semantically structured, and thus propose to learn Structured-implicit PArametric Models (SPAMs) as a deformable object representation that structurally decomposes non-rigid object motion into part-based disentangled representations of shape and pose, with each being represented by deep implicit functions. This enables a structured characterization of object movement, with part decomposition characterizing a lower-dimensional space in which we can establish coarse motion correspondence. In particular, we can leverage the part decompositions at test time to fit to new depth sequences of unobserved shapes, by establishing part correspondences between the input observation and our learned part spaces; this guides a robust joint optimization between the shape and pose of all parts, even under dramatic motion sequences. Experiments demonstrate that our part-aware shape and pose understanding lead to state-of-the-art performance in reconstruction and tracking of depth sequences of complex deforming object motion. We plan to release models to the public at https://pablopalafox.github.io/spams.
Human View Synthesis using a Single Sparse RGB-D Input
Dec 30, 2021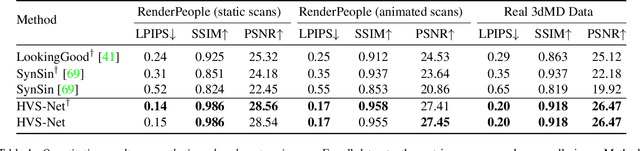

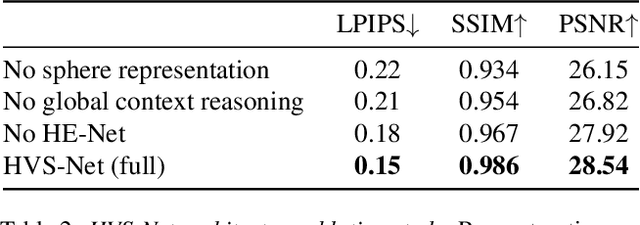
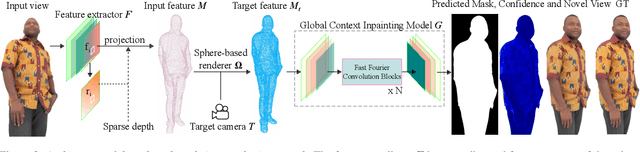
Novel view synthesis for humans in motion is a challenging computer vision problem that enables applications such as free-viewpoint video. Existing methods typically use complex setups with multiple input views, 3D supervision, or pre-trained models that do not generalize well to new identities. Aiming to address these limitations, we present a novel view synthesis framework to generate realistic renders from unseen views of any human captured from a single-view sensor with sparse RGB-D, similar to a low-cost depth camera, and without actor-specific models. We propose an architecture to learn dense features in novel views obtained by sphere-based neural rendering, and create complete renders using a global context inpainting model. Additionally, an enhancer network leverages the overall fidelity, even in occluded areas from the original view, producing crisp renders with fine details. We show our method generates high-quality novel views of synthetic and real human actors given a single sparse RGB-D input. It generalizes to unseen identities, new poses and faithfully reconstructs facial expressions. Our approach outperforms prior human view synthesis methods and is robust to different levels of input sparsity.
Neural-GIF: Neural Generalized Implicit Functions for Animating People in Clothing
Aug 20, 2021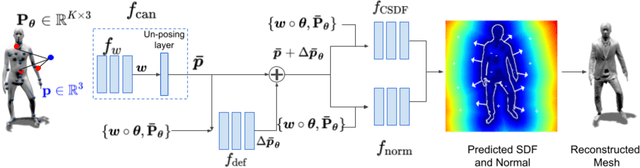


We present Neural Generalized Implicit Functions(Neural-GIF), to animate people in clothing as a function of the body pose. Given a sequence of scans of a subject in various poses, we learn to animate the character for new poses. Existing methods have relied on template-based representations of the human body (or clothing). However such models usually have fixed and limited resolutions, require difficult data pre-processing steps and cannot be used with complex clothing. We draw inspiration from template-based methods, which factorize motion into articulation and non-rigid deformation, but generalize this concept for implicit shape learning to obtain a more flexible model. We learn to map every point in the space to a canonical space, where a learned deformation field is applied to model non-rigid effects, before evaluating the signed distance field. Our formulation allows the learning of complex and non-rigid deformations of clothing and soft tissue, without computing a template registration as it is common with current approaches. Neural-GIF can be trained on raw 3D scans and reconstructs detailed complex surface geometry and deformations. Moreover, the model can generalize to new poses. We evaluate our method on a variety of characters from different public datasets in diverse clothing styles and show significant improvements over baseline methods, quantitatively and qualitatively. We also extend our model to multiple shape setting. To stimulate further research, we will make the model, code and data publicly available at: https://virtualhumans.mpi-inf.mpg.de/neuralgif/
Semi-supervised Synthesis of High-Resolution Editable Textures for 3D Humans
Mar 31, 2021
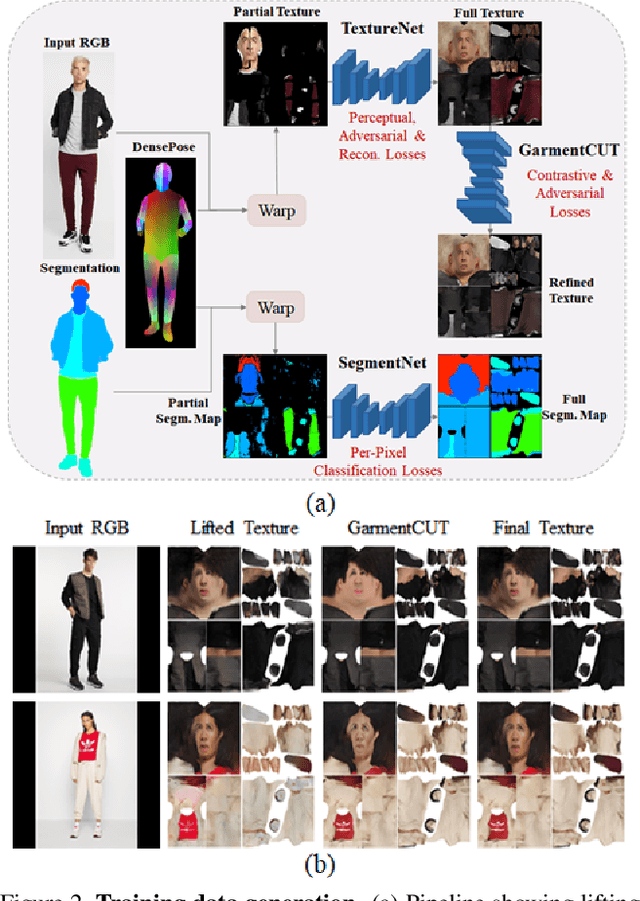
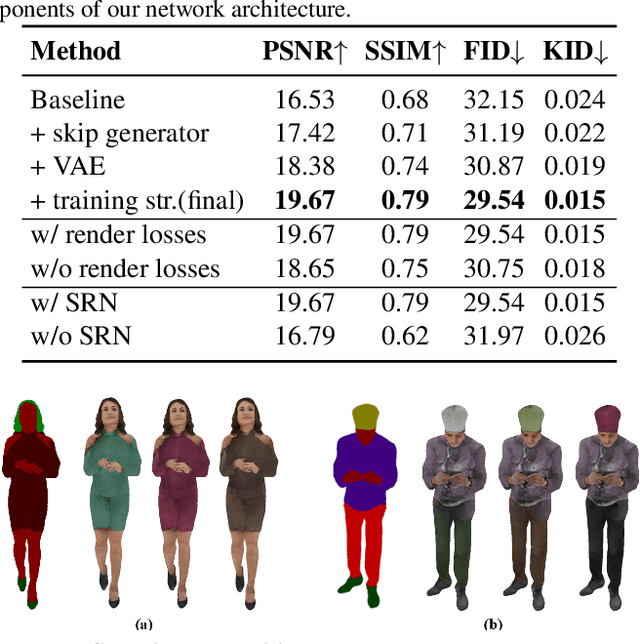
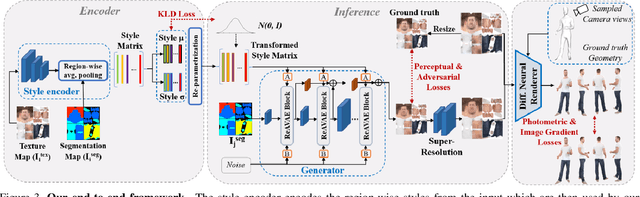
We introduce a novel approach to generate diverse high fidelity texture maps for 3D human meshes in a semi-supervised setup. Given a segmentation mask defining the layout of the semantic regions in the texture map, our network generates high-resolution textures with a variety of styles, that are then used for rendering purposes. To accomplish this task, we propose a Region-adaptive Adversarial Variational AutoEncoder (ReAVAE) that learns the probability distribution of the style of each region individually so that the style of the generated texture can be controlled by sampling from the region-specific distributions. In addition, we introduce a data generation technique to augment our training set with data lifted from single-view RGB inputs. Our training strategy allows the mixing of reference image styles with arbitrary styles for different regions, a property which can be valuable for virtual try-on AR/VR applications. Experimental results show that our method synthesizes better texture maps compared to prior work while enabling independent layout and style controllability.
On Improving the Generalization of Face Recognition in the Presence of Occlusions
Jun 11, 2020

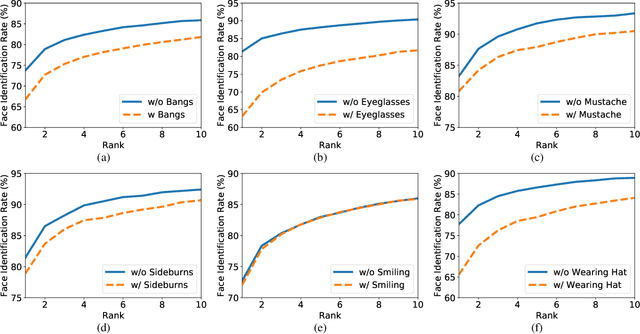

In this paper, we address a key limitation of existing 2D face recognition methods: robustness to occlusions. To accomplish this task, we systematically analyzed the impact of facial attributes on the performance of a state-of-the-art face recognition method and through extensive experimentation, quantitatively analyzed the performance degradation under different types of occlusion. Our proposed Occlusion-aware face REcOgnition (OREO) approach learned discriminative facial templates despite the presence of such occlusions. First, an attention mechanism was proposed that extracted local identity-related region. The local features were then aggregated with the global representations to form a single template. Second, a simple, yet effective, training strategy was introduced to balance the non-occluded and occluded facial images. Extensive experiments demonstrated that OREO improved the generalization ability of face recognition under occlusions by (10.17%) in a single-image-based setting and outperformed the baseline by approximately (2%) in terms of rank-1 accuracy in an image-set-based scenario.