 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo you understand epistemic uncertainty? Think again! Rigorous frequentist epistemic uncertainty estimation in regression
Mar 17, 2025Quantifying model uncertainty is critical for understanding prediction reliability, yet distinguishing between aleatoric and epistemic uncertainty remains challenging. We extend recent work from classification to regression to provide a novel frequentist approach to epistemic and aleatoric uncertainty estimation. We train models to generate conditional predictions by feeding their initial output back as an additional input. This method allows for a rigorous measurement of model uncertainty by observing how prediction responses change when conditioned on the model's previous answer. We provide a complete theoretical framework to analyze epistemic uncertainty in regression in a frequentist way, and explain how it can be exploited in practice to gauge a model's uncertainty, with minimal changes to the original architecture.
D3DR: Lighting-Aware Object Insertion in Gaussian Splatting
Mar 09, 2025Gaussian Splatting has become a popular technique for various 3D Computer Vision tasks, including novel view synthesis, scene reconstruction, and dynamic scene rendering. However, the challenge of natural-looking object insertion, where the object's appearance seamlessly matches the scene, remains unsolved. In this work, we propose a method, dubbed D3DR, for inserting a 3DGS-parametrized object into 3DGS scenes while correcting its lighting, shadows, and other visual artifacts to ensure consistency, a problem that has not been successfully addressed before. We leverage advances in diffusion models, which, trained on real-world data, implicitly understand correct scene lighting. After inserting the object, we optimize a diffusion-based Delta Denoising Score (DDS)-inspired objective to adjust its 3D Gaussian parameters for proper lighting correction. Utilizing diffusion model personalization techniques to improve optimization quality, our approach ensures seamless object insertion and natural appearance. Finally, we demonstrate the method's effectiveness by comparing it to existing approaches, achieving 0.5 PSNR and 0.15 SSIM improvements in relighting quality.
Uncertainty Estimation for 3D Object Detection via Evidential Learning
Oct 31, 2024



3D object detection is an essential task for computer vision applications in autonomous vehicles and robotics. However, models often struggle to quantify detection reliability, leading to poor performance on unfamiliar scenes. We introduce a framework for quantifying uncertainty in 3D object detection by leveraging an evidential learning loss on Bird's Eye View representations in the 3D detector. These uncertainty estimates require minimal computational overhead and are generalizable across different architectures. We demonstrate both the efficacy and importance of these uncertainty estimates on identifying out-of-distribution scenes, poorly localized objects, and missing (false negative) detections; our framework consistently improves over baselines by 10-20% on average. Finally, we integrate this suite of tasks into a system where a 3D object detector auto-labels driving scenes and our uncertainty estimates verify label correctness before the labels are used to train a second model. Here, our uncertainty-driven verification results in a 1% improvement in mAP and a 1-2% improvement in NDS.
IT$^3$: Idempotent Test-Time Training
Oct 05, 2024



This paper introduces Idempotent Test-Time Training (IT$^3$), a novel approach to addressing the challenge of distribution shift. While supervised-learning methods assume matching train and test distributions, this is rarely the case for machine learning systems deployed in the real world. Test-Time Training (TTT) approaches address this by adapting models during inference, but they are limited by a domain specific auxiliary task. IT$^3$ is based on the universal property of idempotence. An idempotent operator is one that can be applied sequentially without changing the result beyond the initial application, that is $f(f(x))=f(x)$. At training, the model receives an input $x$ along with another signal that can either be the ground truth label $y$ or a neutral "don't know" signal $0$. At test time, the additional signal can only be $0$. When sequentially applying the model, first predicting $y_0 = f(x, 0)$ and then $y_1 = f(x, y_0)$, the distance between $y_0$ and $y_1$ measures certainty and indicates out-of-distribution input $x$ if high. We use this distance, that can be expressed as $||f(x, f(x, 0)) - f(x, 0)||$ as our TTT loss during inference. By carefully optimizing this objective, we effectively train $f(x,\cdot)$ to be idempotent, projecting the internal representation of the input onto the training distribution. We demonstrate the versatility of our approach across various tasks, including corrupted image classification, aerodynamic predictions, tabular data with missing information, age prediction from face, and large-scale aerial photo segmentation. Moreover, these tasks span different architectures such as MLPs, CNNs, and GNNs.
MirrorCheck: Efficient Adversarial Defense for Vision-Language Models
Jun 13, 2024



Vision-Language Models (VLMs) are becoming increasingly vulnerable to adversarial attacks as various novel attack strategies are being proposed against these models. While existing defenses excel in unimodal contexts, they currently fall short in safeguarding VLMs against adversarial threats. To mitigate this vulnerability, we propose a novel, yet elegantly simple approach for detecting adversarial samples in VLMs. Our method leverages Text-to-Image (T2I) models to generate images based on captions produced by target VLMs. Subsequently, we calculate the similarities of the embeddings of both input and generated images in the feature space to identify adversarial samples. Empirical evaluations conducted on different datasets validate the efficacy of our approach, outperforming baseline methods adapted from image classification domains. Furthermore, we extend our methodology to classification tasks, showcasing its adaptability and model-agnostic nature. Theoretical analyses and empirical findings also show the resilience of our approach against adaptive attacks, positioning it as an excellent defense mechanism for real-world deployment against adversarial threats.
Enabling Uncertainty Estimation in Iterative Neural Networks
Mar 25, 2024Turning pass-through network architectures into iterative ones, which use their own output as input, is a well-known approach for boosting performance. In this paper, we argue that such architectures offer an additional benefit: The convergence rate of their successive outputs is highly correlated with the accuracy of the value to which they converge. Thus, we can use the convergence rate as a useful proxy for uncertainty. This results in an approach to uncertainty estimation that provides state-of-the-art estimates at a much lower computational cost than techniques like Ensembles, and without requiring any modifications to the original iterative model. We demonstrate its practical value by embedding it in two application domains: road detection in aerial images and the estimation of aerodynamic properties of 2D and 3D shapes.
ZigZag: Universal Sampling-free Uncertainty Estimation Through Two-Step Inference
Nov 21, 2022



Whereas the ability of deep networks to produce useful predictions on many kinds of data has been amply demonstrated, estimating the reliability of these predictions remains challenging. Sampling approaches such as MC-Dropout and Deep Ensembles have emerged as the most popular ones for this purpose. Unfortunately, they require many forward passes at inference time, which slows them down. Sampling-free approaches can be faster but suffer from other drawbacks, such as lower reliability of uncertainty estimates, difficulty of use, and limited applicability to different types of tasks and data. In this work, we introduce a sampling-free approach that is generic and easy to deploy, while producing reliable uncertainty estimates on par with state-of-the-art methods at a significantly lower computational cost. It is predicated on training the network to produce the same output with and without additional information about that output. At inference time, when no prior information is given, we use the network's own prediction as the additional information. We prove that the difference between the two predictions is an accurate uncertainty estimate and demonstrate our approach on various types of tasks and applications.
PartAL: Efficient Partial Active Learning in Multi-Task Visual Settings
Nov 21, 2022



Multi-task learning is central to many real-world applications. Unfortunately, obtaining labelled data for all tasks is time-consuming, challenging, and expensive. Active Learning (AL) can be used to reduce this burden. Existing techniques typically involve picking images to be annotated and providing annotations for all tasks. In this paper, we show that it is more effective to select not only the images to be annotated but also a subset of tasks for which to provide annotations at each AL iteration. Furthermore, the annotations that are provided can be used to guess pseudo-labels for the tasks that remain unannotated. We demonstrate the effectiveness of our approach on several popular multi-task datasets.
How to Boost Face Recognition with StyleGAN?
Oct 18, 2022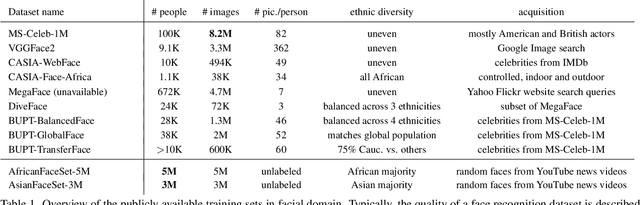
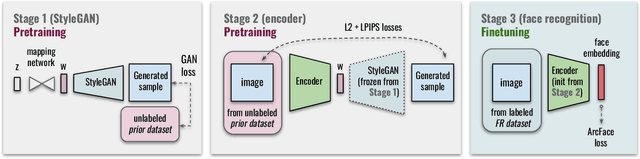
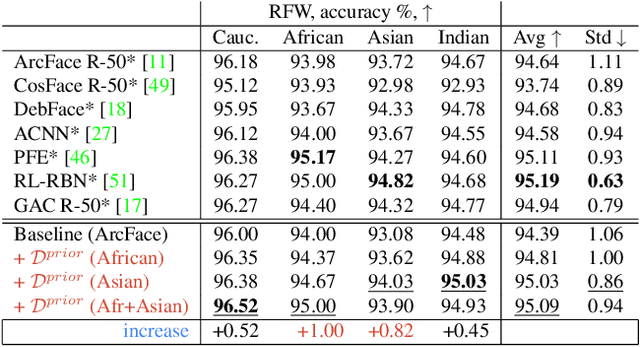

State-of-the-art face recognition systems require huge amounts of labeled training data. Given the priority of privacy in face recognition applications, the data is limited to celebrity web crawls, which have issues such as skewed distributions of ethnicities and limited numbers of identities. On the other hand, the self-supervised revolution in the industry motivates research on adaptation of the related techniques to facial recognition. One of the most popular practical tricks is to augment the dataset by the samples drawn from the high-resolution high-fidelity models (e.g. StyleGAN-like), while preserving the identity. We show that a simple approach based on fine-tuning an encoder for StyleGAN allows to improve upon the state-of-the-art facial recognition and performs better compared to training on synthetic face identities. We also collect large-scale unlabeled datasets with controllable ethnic constitution -- AfricanFaceSet-5M (5 million images of different people) and AsianFaceSet-3M (3 million images of different people) and we show that pretraining on each of them improves recognition of the respective ethnicities (as well as also others), while combining all unlabeled datasets results in the biggest performance increase. Our self-supervised strategy is the most useful with limited amounts of labeled training data, which can be beneficial for more tailored face recognition tasks and when facing privacy concerns. Evaluation is provided based on a standard RFW dataset and a new large-scale RB-WebFace benchmark.
DEBOSH: Deep Bayesian Shape Optimization
Sep 28, 2021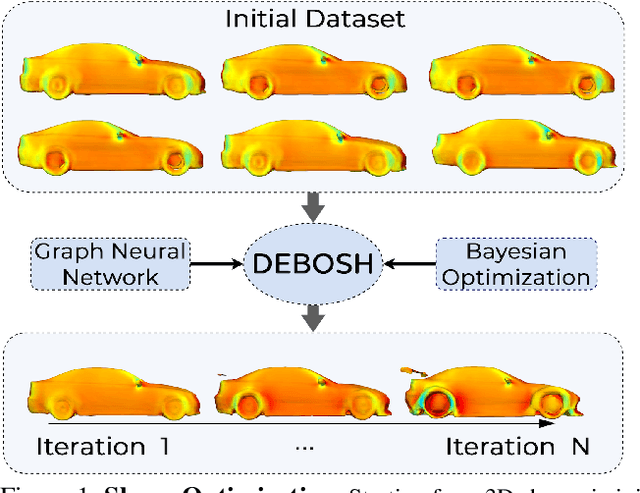
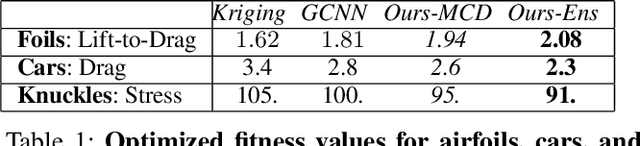
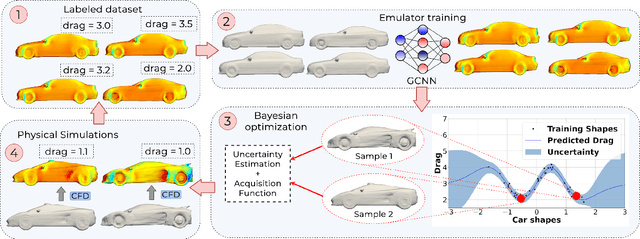
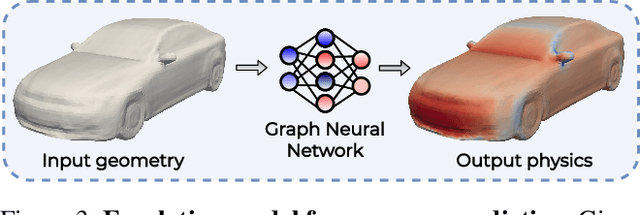
Shape optimization is at the heart of many industrial applications, such as aerodynamics, heat transfer, and structural analysis. It has recently been shown that Graph Neural Networks (GNNs) can predict the performance of a shape quickly and accurately and be used to optimize more effectively than traditional techniques that rely on response-surfaces obtained by Kriging. However, GNNs suffer from the fact that they do not evaluate their own accuracy, which is something Bayesian Optimization methods require. Therefore, estimating confidence in generated predictions is necessary to go beyond straight deterministic optimization, which is less effective. In this paper, we demonstrate that we can use Ensembles-based technique to overcome this limitation and outperform the state-of-the-art. Our experiments on diverse aerodynamics and structural analysis tasks prove that adding uncertainty to shape optimization significantly improves the quality of resulting shapes and reduces the time required for the optimization.