 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory and Experiments on Vector Quantized Autoencoders
Jul 20, 2018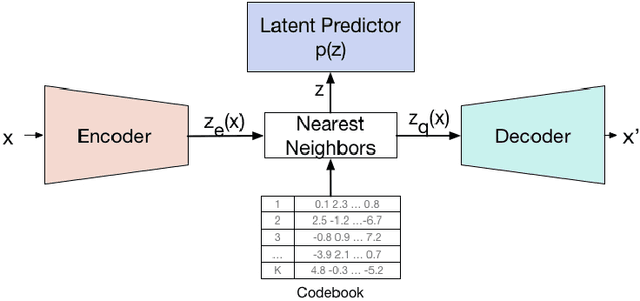
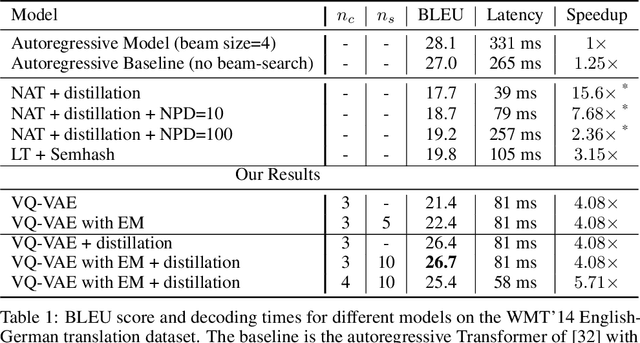
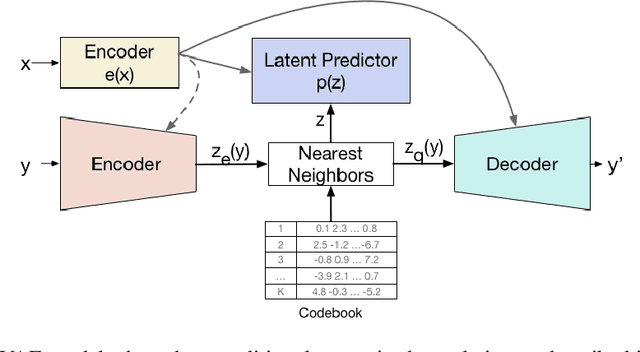

Deep neural networks with discrete latent variables offer the promise of better symbolic reasoning, and learning abstractions that are more useful to new tasks. There has been a surge in interest in discrete latent variable models, however, despite several recent improvements, the training of discrete latent variable models has remained challenging and their performance has mostly failed to match their continuous counterparts. Recent work on vector quantized autoencoders (VQ-VAE) has made substantial progress in this direction, with its perplexity almost matching that of a VAE on datasets such as CIFAR-10. In this work, we investigate an alternate training technique for VQ-VAE, inspired by its connection to the Expectation Maximization (EM) algorithm. Training the discrete bottleneck with EM helps us achieve better image generation results on CIFAR-10, and together with knowledge distillation, allows us to develop a non-autoregressive machine translation model whose accuracy almost matches a strong greedy autoregressive baseline Transformer, while being 3.3 times faster at inference.
Image Transformer
Jun 15, 2018
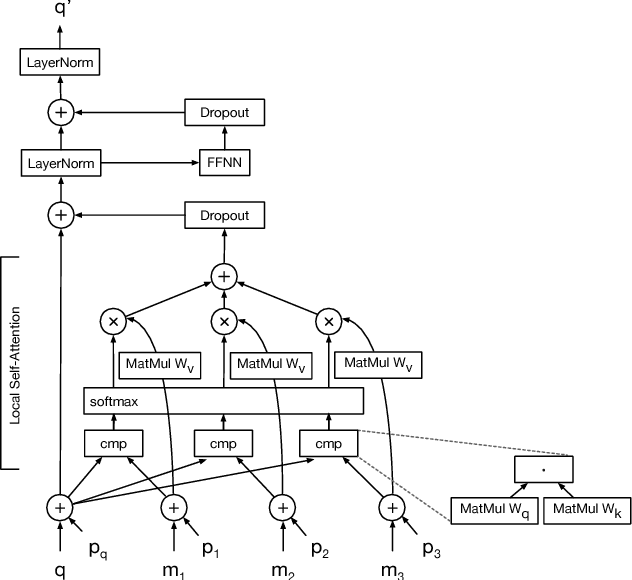

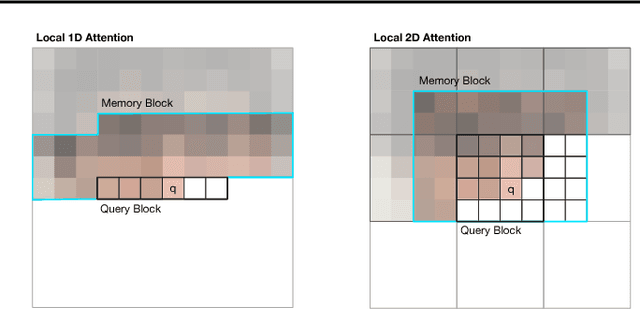
Image generation has been successfully cast as an autoregressive sequence generation or transformation problem. Recent work has shown that self-attention is an effective way of modeling textual sequences. In this work, we generalize a recently proposed model architecture based on self-attention, the Transformer, to a sequence modeling formulation of image generation with a tractable likelihood. By restricting the self-attention mechanism to attend to local neighborhoods we significantly increase the size of images the model can process in practice, despite maintaining significantly larger receptive fields per layer than typical convolutional neural networks. While conceptually simple, our generative models significantly outperform the current state of the art in image generation on ImageNet, improving the best published negative log-likelihood on ImageNet from 3.83 to 3.77. We also present results on image super-resolution with a large magnification ratio, applying an encoder-decoder configuration of our architecture. In a human evaluation study, we find that images generated by our super-resolution model fool human observers three times more often than the previous state of the art.
Fast Decoding in Sequence Models using Discrete Latent Variables
Jun 07, 2018

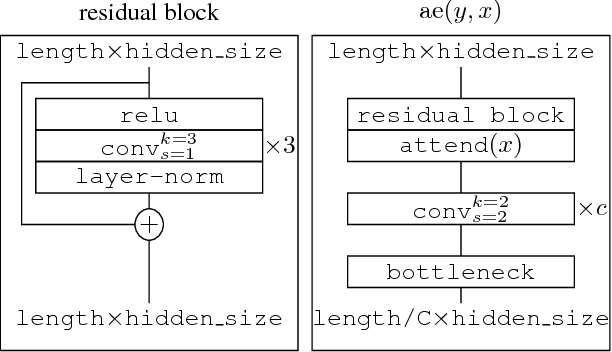
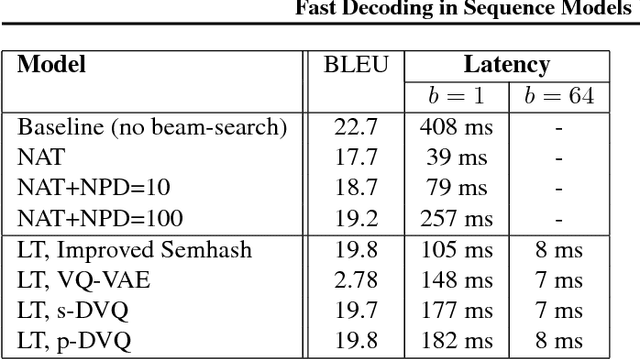
Autoregressive sequence models based on deep neural networks, such as RNNs, Wavenet and the Transformer attain state-of-the-art results on many tasks. However, they are difficult to parallelize and are thus slow at processing long sequences. RNNs lack parallelism both during training and decoding, while architectures like WaveNet and Transformer are much more parallelizable during training, yet still operate sequentially during decoding. Inspired by [arxiv:1711.00937], we present a method to extend sequence models using discrete latent variables that makes decoding much more parallelizable. We first auto-encode the target sequence into a shorter sequence of discrete latent variables, which at inference time is generated autoregressively, and finally decode the output sequence from this shorter latent sequence in parallel. To this end, we introduce a novel method for constructing a sequence of discrete latent variables and compare it with previously introduced methods. Finally, we evaluate our model end-to-end on the task of neural machine translation, where it is an order of magnitude faster at decoding than comparable autoregressive models. While lower in BLEU than purely autoregressive models, our model achieves higher scores than previously proposed non-autoregressive translation models.
The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation
Apr 27, 2018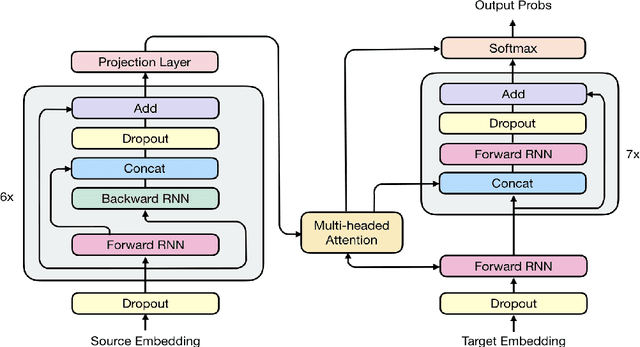
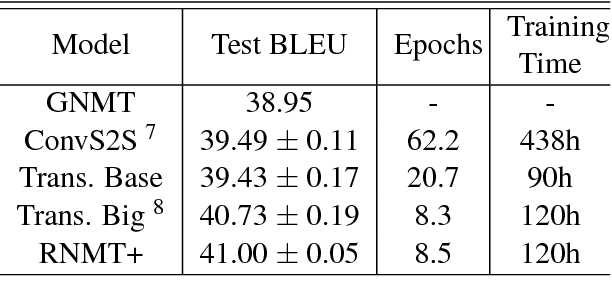
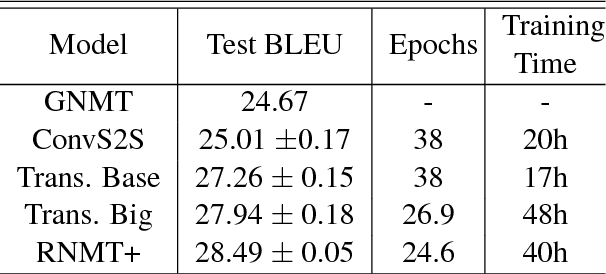
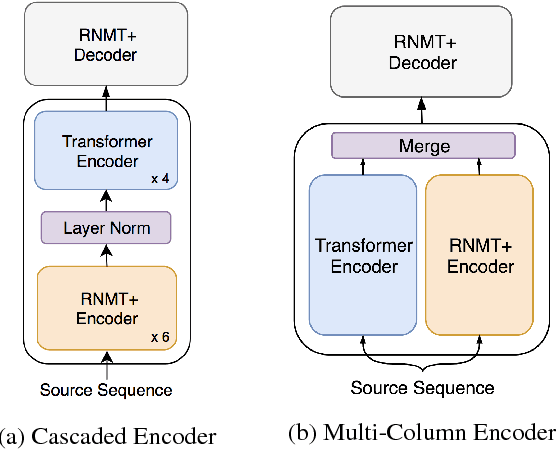
The past year has witnessed rapid advances in sequence-to-sequence (seq2seq) modeling for Machine Translation (MT). The classic RNN-based approaches to MT were first out-performed by the convolutional seq2seq model, which was then out-performed by the more recent Transformer model. Each of these new approaches consists of a fundamental architecture accompanied by a set of modeling and training techniques that are in principle applicable to other seq2seq architectures. In this paper, we tease apart the new architectures and their accompanying techniques in two ways. First, we identify several key modeling and training techniques, and apply them to the RNN architecture, yielding a new RNMT+ model that outperforms all of the three fundamental architectures on the benchmark WMT'14 English to French and English to German tasks. Second, we analyze the properties of each fundamental seq2seq architecture and devise new hybrid architectures intended to combine their strengths. Our hybrid models obtain further improvements, outperforming the RNMT+ model on both benchmark datasets.
Tensor2Tensor for Neural Machine Translation
Mar 16, 2018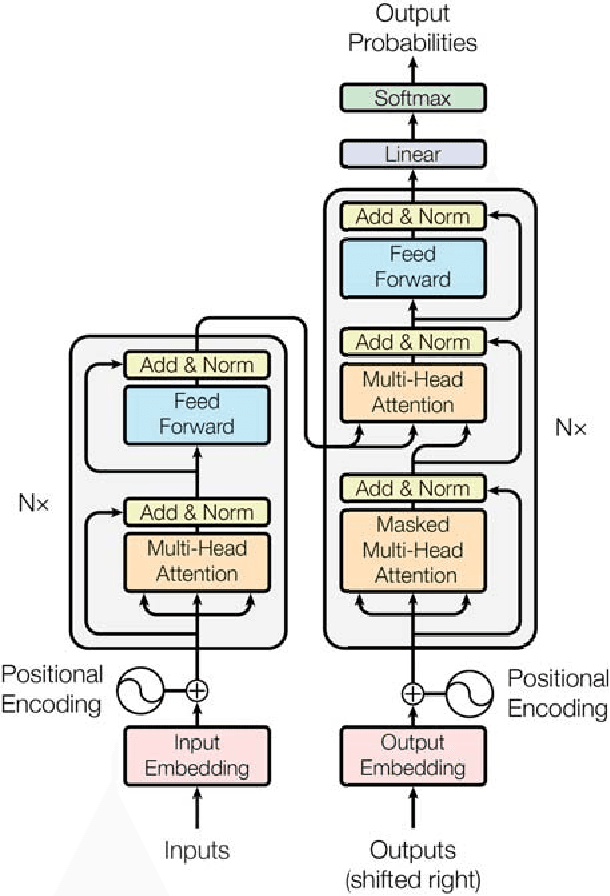
Tensor2Tensor is a library for deep learning models that is well-suited for neural machine translation and includes the reference implementation of the state-of-the-art Transformer model.
Attention Is All You Need
Dec 06, 2017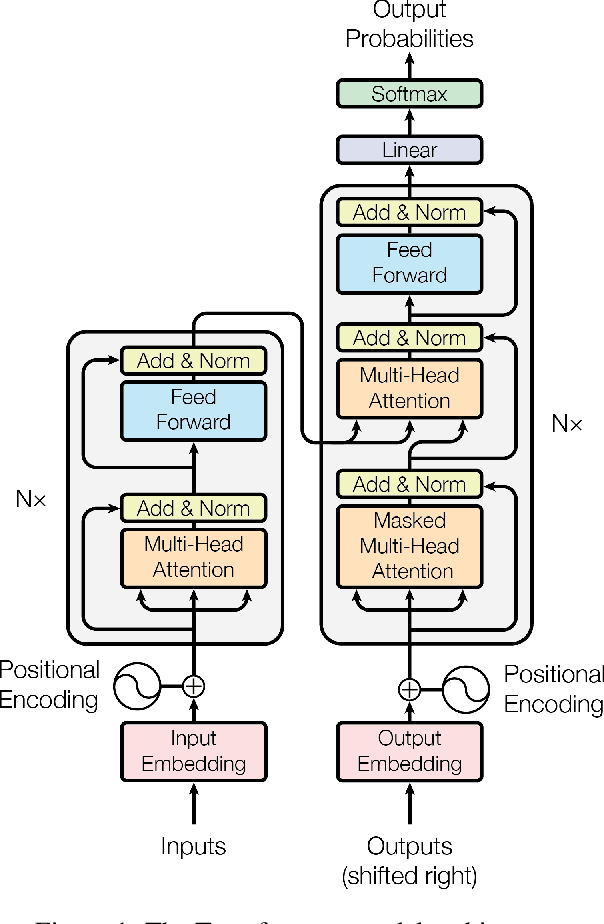
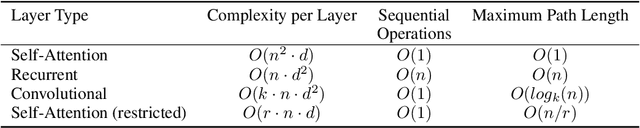
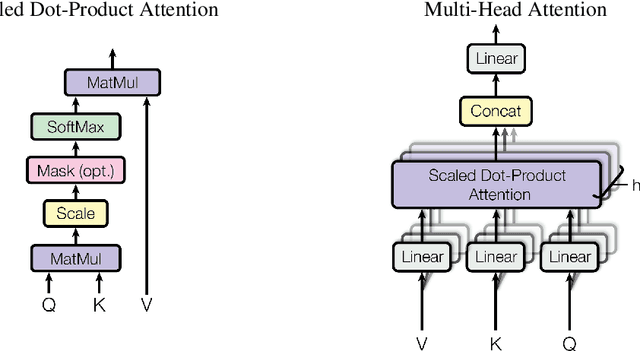
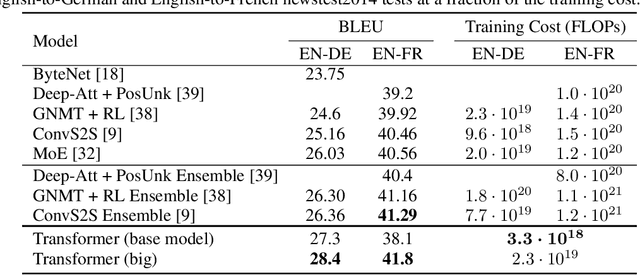
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
One Model To Learn Them All
Jun 16, 2017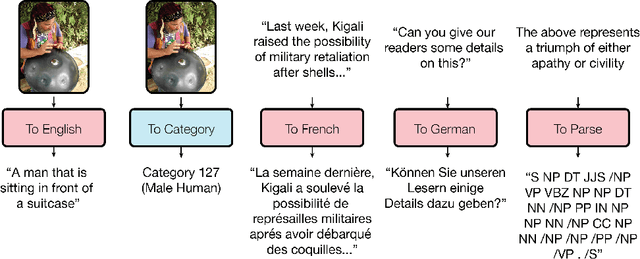

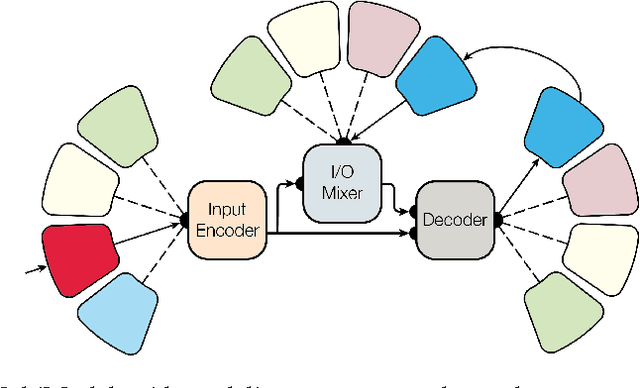

Deep learning yields great results across many fields, from speech recognition, image classification, to translation. But for each problem, getting a deep model to work well involves research into the architecture and a long period of tuning. We present a single model that yields good results on a number of problems spanning multiple domains. In particular, this single model is trained concurrently on ImageNet, multiple translation tasks, image captioning (COCO dataset), a speech recognition corpus, and an English parsing task. Our model architecture incorporates building blocks from multiple domains. It contains convolutional layers, an attention mechanism, and sparsely-gated layers. Each of these computational blocks is crucial for a subset of the tasks we train on. Interestingly, even if a block is not crucial for a task, we observe that adding it never hurts performance and in most cases improves it on all tasks. We also show that tasks with less data benefit largely from joint training with other tasks, while performance on large tasks degrades only slightly if at all.