 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Counterfactually Invariant Predictors
Jul 20, 2022



We propose a method to learn predictors that are invariant under counterfactual changes of certain covariates. This method is useful when the prediction target is causally influenced by covariates that should not affect the predictor output. For instance, an object recognition model may be influenced by position, orientation, or scale of the object itself. We address the problem of training predictors that are explicitly counterfactually invariant to changes of such covariates. We propose a model-agnostic regularization term based on conditional kernel mean embeddings, to enforce counterfactual invariance during training. We prove the soundness of our method, which can handle mixed categorical and continuous multi-variate attributes. Empirical results on synthetic and real-world data demonstrate the efficacy of our method in a variety of settings.
Modeling Content Creator Incentives on Algorithm-Curated Platforms
Jun 27, 2022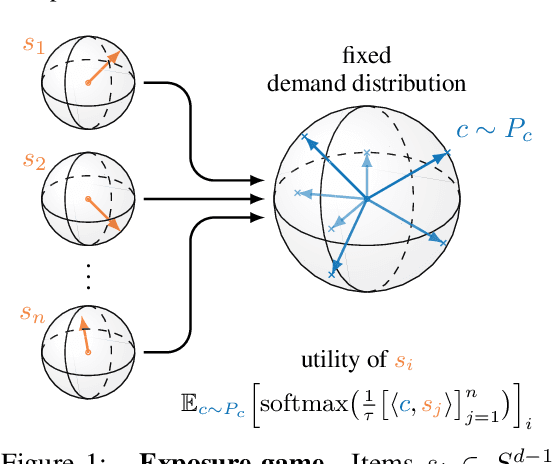

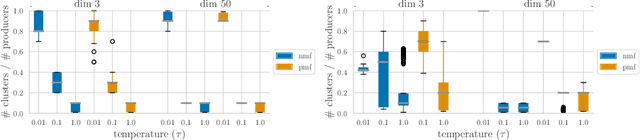
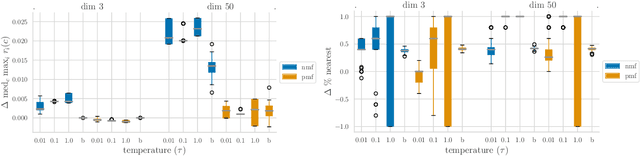
Content creators compete for user attention. Their reach crucially depends on algorithmic choices made by developers on online platforms. To maximize exposure, many creators adapt strategically, as evidenced by examples like the sprawling search engine optimization industry. This begets competition for the finite user attention pool. We formalize these dynamics in what we call an exposure game, a model of incentives induced by algorithms including modern factorization and (deep) two-tower architectures. We prove that seemingly innocuous algorithmic choices -- e.g., non-negative vs. unconstrained factorization -- significantly affect the existence and character of (Nash) equilibria in exposure games. We proffer use of creator behavior models like ours for an (ex-ante) pre-deployment audit. Such an audit can identify misalignment between desirable and incentivized content, and thus complement post-hoc measures like content filtering and moderation. To this end, we propose tools for numerically finding equilibria in exposure games, and illustrate results of an audit on the MovieLens and LastFM datasets. Among else, we find that the strategically produced content exhibits strong dependence between algorithmic exploration and content diversity, and between model expressivity and bias towards gender-based user and creator groups.
Multi-disciplinary fairness considerations in machine learning for clinical trials
May 18, 2022While interest in the application of machine learning to improve healthcare has grown tremendously in recent years, a number of barriers prevent deployment in medical practice. A notable concern is the potential to exacerbate entrenched biases and existing health disparities in society. The area of fairness in machine learning seeks to address these issues of equity; however, appropriate approaches are context-dependent, necessitating domain-specific consideration. We focus on clinical trials, i.e., research studies conducted on humans to evaluate medical treatments. Clinical trials are a relatively under-explored application in machine learning for healthcare, in part due to complex ethical, legal, and regulatory requirements and high costs. Our aim is to provide a multi-disciplinary assessment of how fairness for machine learning fits into the context of clinical trials research and practice. We start by reviewing the current ethical considerations and guidelines for clinical trials and examine their relationship with common definitions of fairness in machine learning. We examine potential sources of unfairness in clinical trials, providing concrete examples, and discuss the role machine learning might play in either mitigating potential biases or exacerbating them when applied without care. Particular focus is given to adaptive clinical trials, which may employ machine learning. Finally, we highlight concepts that require further investigation and development, and emphasize new approaches to fairness that may be relevant to the design of clinical trials.
Supervised Learning and Model Analysis with Compositional Data
May 15, 2022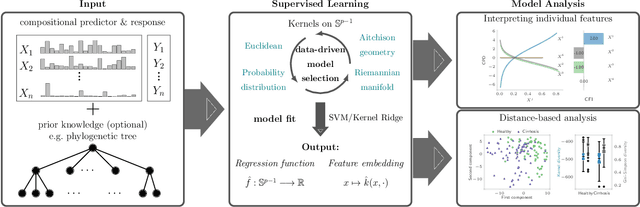

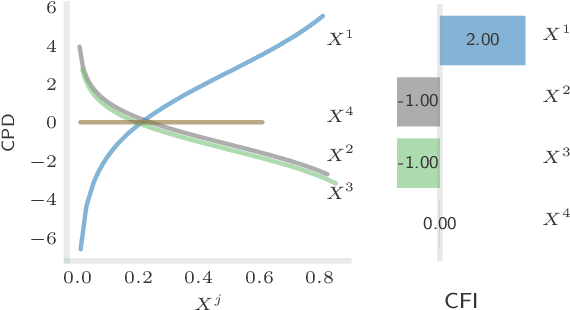
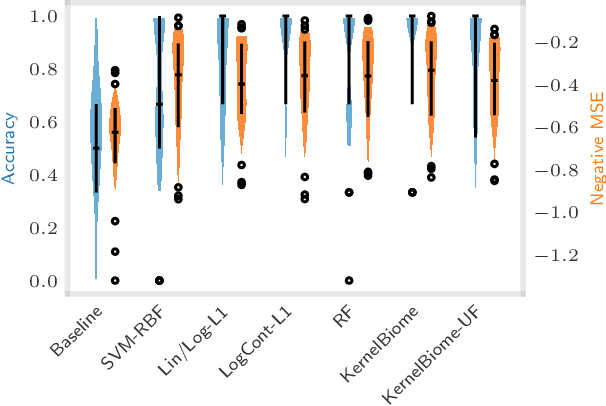
The compositionality and sparsity of high-throughput sequencing data poses a challenge for regression and classification. However, in microbiome research in particular, conditional modeling is an essential tool to investigate relationships between phenotypes and the microbiome. Existing techniques are often inadequate: they either rely on extensions of the linear log-contrast model (which adjusts for compositionality, but is often unable to capture useful signals), or they are based on black-box machine learning methods (which may capture useful signals, but ignore compositionality in downstream analyses). We propose KernelBiome, a kernel-based nonparametric regression and classification framework for compositional data. It is tailored to sparse compositional data and is able to incorporate prior knowledge, such as phylogenetic structure. KernelBiome captures complex signals, including in the zero-structure, while automatically adapting model complexity. We demonstrate on par or improved predictive performance compared with state-of-the-art machine learning methods. Additionally, our framework provides two key advantages: (i) We propose two novel quantities to interpret contributions of individual components and prove that they consistently estimate average perturbation effects of the conditional mean, extending the interpretability of linear log-contrast models to nonparametric models. (ii) We show that the connection between kernels and distances aids interpretability and provides a data-driven embedding that can augment further analysis. Finally, we apply the KernelBiome framework to two public microbiome studies and illustrate the proposed model analysis. KernelBiome is available as an open-source Python package at https://github.com/shimenghuang/KernelBiome.
Predicting single-cell perturbation responses for unseen drugs
Apr 28, 2022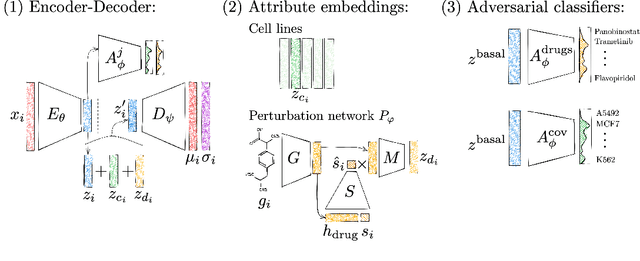
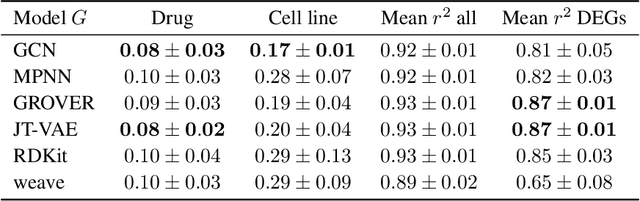
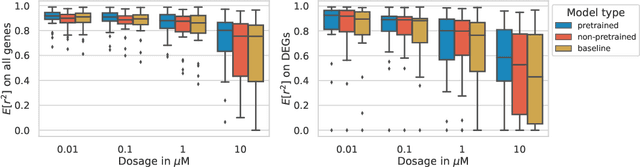
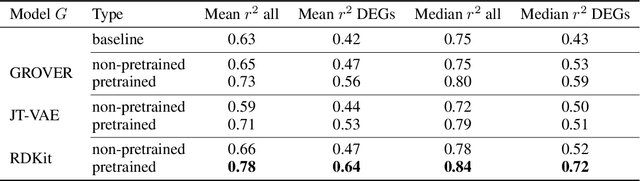
Single-cell transcriptomics enabled the study of cellular heterogeneity in response to perturbations at the resolution of individual cells. However, scaling high-throughput screens (HTSs) to measure cellular responses for many drugs remains a challenge due to technical limitations and, more importantly, the cost of such multiplexed experiments. Thus, transferring information from routinely performed bulk RNA-seq HTS is required to enrich single-cell data meaningfully. We introduce a new encoder-decoder architecture to study the perturbational effects of unseen drugs. We combine the model with a transfer learning scheme and demonstrate how training on existing bulk RNA-seq HTS datasets can improve generalisation performance. Better generalisation reduces the need for extensive and costly screens at single-cell resolution. We envision that our proposed method will facilitate more efficient experiment designs through its ability to generate in-silico hypotheses, ultimately accelerating targeted drug discovery.
* 8 pages
Stochastic Causal Programming for Bounding Treatment Effects
Feb 22, 2022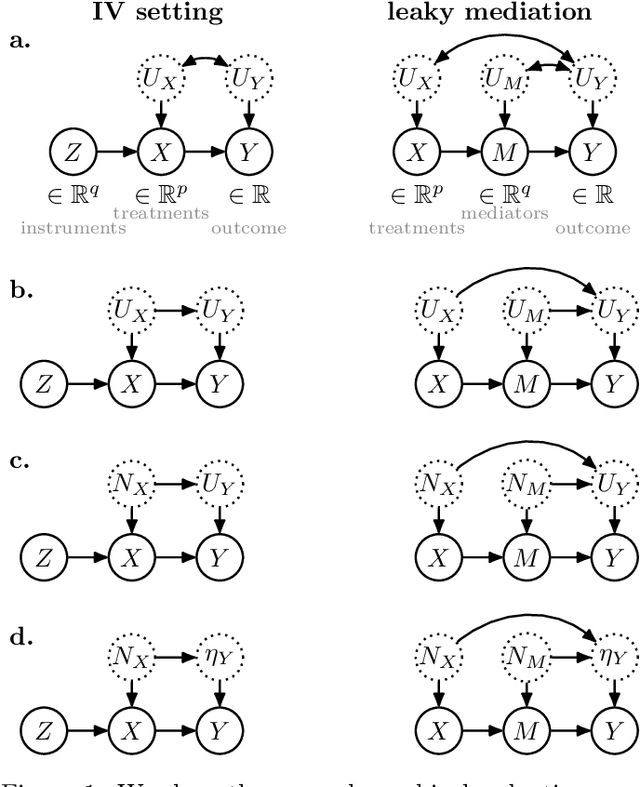
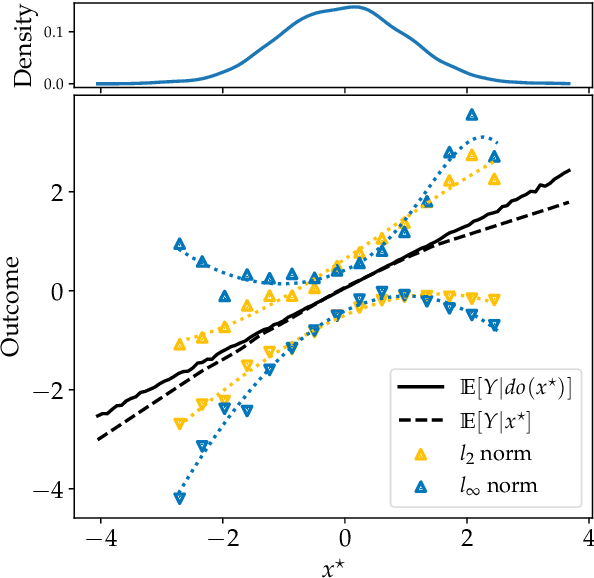
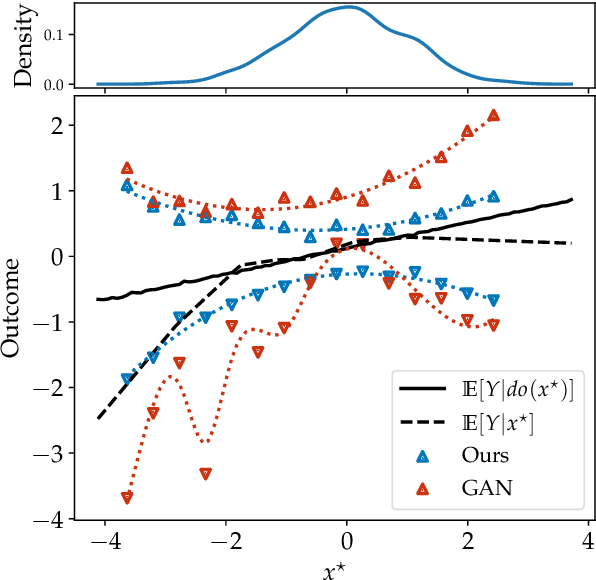
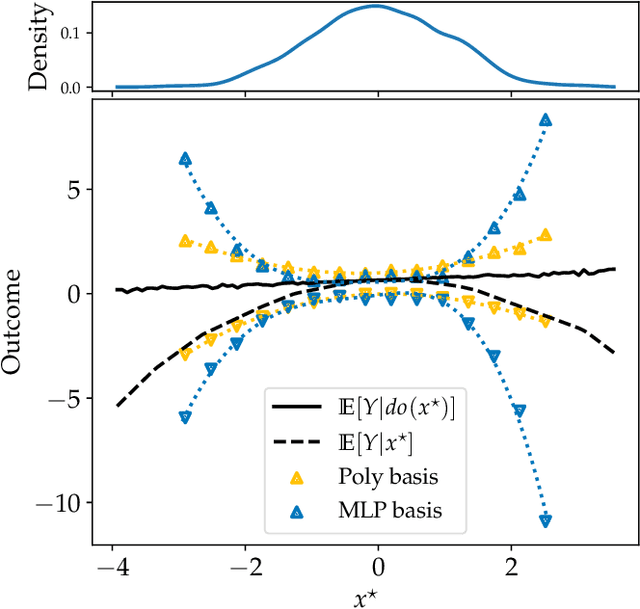
Causal effect estimation is important for numerous tasks in the natural and social sciences. However, identifying effects is impossible from observational data without making strong, often untestable assumptions. We consider algorithms for the partial identification problem, bounding treatment effects from multivariate, continuous treatments over multiple possible causal models when unmeasured confounding makes identification impossible. We consider a framework where observable evidence is matched to the implications of constraints encoded in a causal model by norm-based criteria. This generalizes classical approaches based purely on generative models. Casting causal effects as objective functions in a constrained optimization problem, we combine flexible learning algorithms with Monte Carlo methods to implement a family of solutions under the name of stochastic causal programming. In particular, we present ways by which such constrained optimization problems can be parameterized without likelihood functions for the causal or the observed data model, reducing the computational and statistical complexity of the task.
On component interactions in two-stage recommender systems
Jun 28, 2021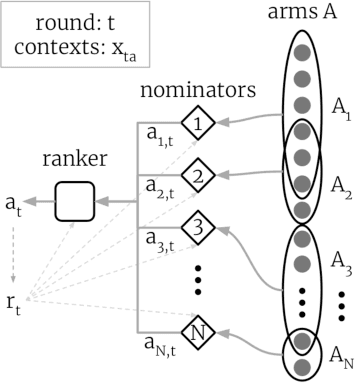

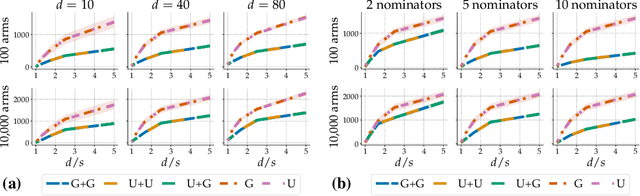
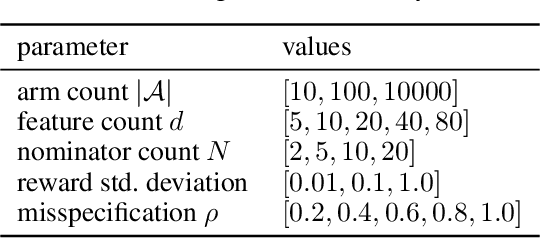
Thanks to their scalability, two-stage recommenders are used by many of today's largest online platforms, including YouTube, LinkedIn, and Pinterest. These systems produce recommendations in two steps: (i) multiple nominators -- tuned for low prediction latency -- preselect a small subset of candidates from the whole item pool; (ii)~a slower but more accurate ranker further narrows down the nominated items, and serves to the user. Despite their popularity, the literature on two-stage recommenders is relatively scarce, and the algorithms are often treated as the sum of their parts. Such treatment presupposes that the two-stage performance is explained by the behavior of individual components if they were deployed independently. This is not the case: using synthetic and real-world data, we demonstrate that interactions between the ranker and the nominators substantially affect the overall performance. Motivated by these findings, we derive a generalization lower bound which shows that careful choice of each nominator's training set is sometimes the only difference between a poor and an optimal two-stage recommender. Since searching for a good choice manually is difficult, we learn one instead. In particular, using a Mixture-of-Experts approach, we train the nominators (experts) to specialize on different subsets of the item pool. This significantly improves performance.
Beyond Predictions in Neural ODEs: Identification and Interventions
Jun 23, 2021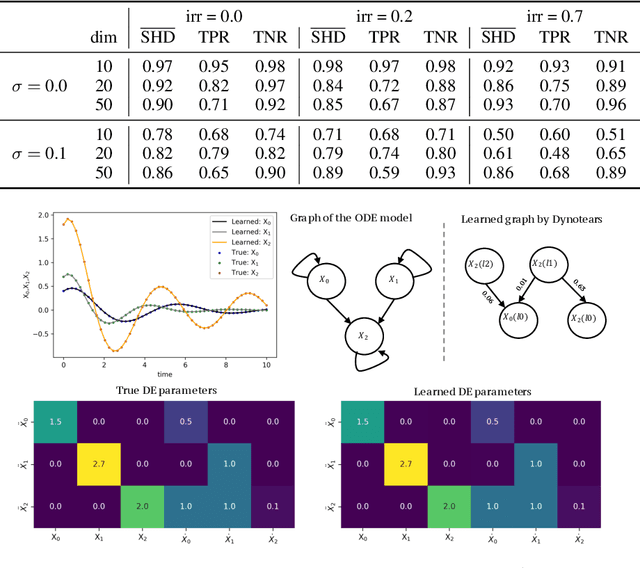
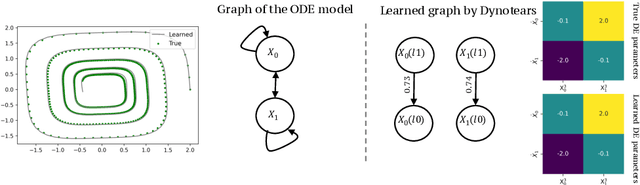
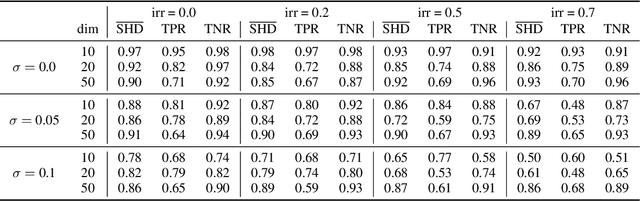
Spurred by tremendous success in pattern matching and prediction tasks, researchers increasingly resort to machine learning to aid original scientific discovery. Given large amounts of observational data about a system, can we uncover the rules that govern its evolution? Solving this task holds the great promise of fully understanding the causal interactions and being able to make reliable predictions about the system's behavior under interventions. We take a step towards answering this question for time-series data generated from systems of ordinary differential equations (ODEs). While the governing ODEs might not be identifiable from data alone, we show that combining simple regularization schemes with flexible neural ODEs can robustly recover the dynamics and causal structures from time-series data. Our results on a variety of (non)-linear first and second order systems as well as real data validate our method. We conclude by showing that we can also make accurate predictions under interventions on variables or the system itself.
A causal view on compositional data
Jun 21, 2021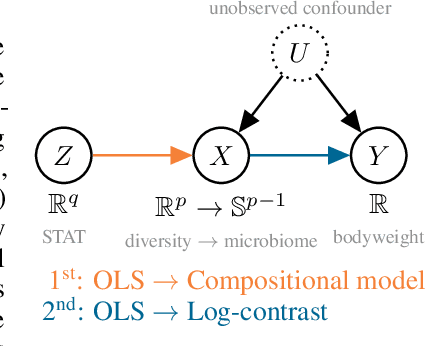
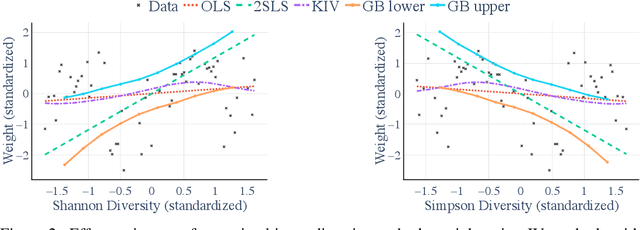
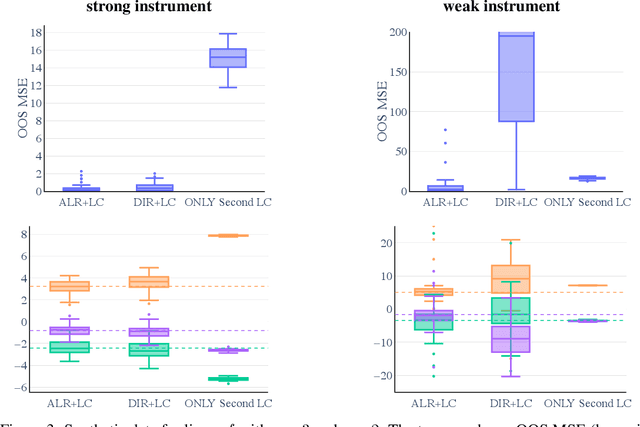
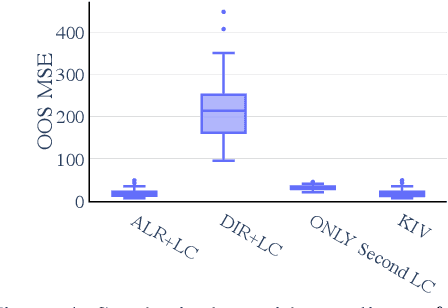
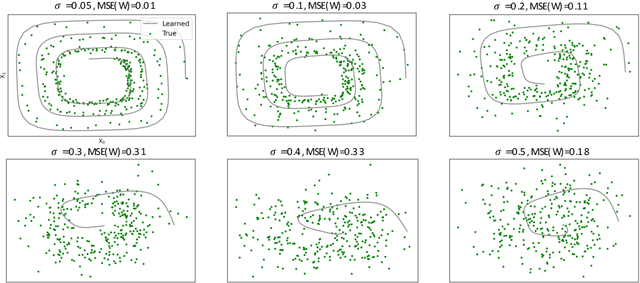
Many scientific datasets are compositional in nature. Important examples include species abundances in ecology, rock compositions in geology, topic compositions in large-scale text corpora, and sequencing count data in molecular biology. Here, we provide a causal view on compositional data in an instrumental variable setting where the composition acts as the cause. Throughout, we pay particular attention to the interpretation of compositional causes from the viewpoint of interventions and crisply articulate potential pitfalls for practitioners. Focusing on modern high-dimensional microbiome sequencing data as a timely illustrative use case, our analysis first reveals that popular one-dimensional information-theoretic summary statistics, such as diversity and richness, may be insufficient for drawing causal conclusions from ecological data. Instead, we advocate for multivariate alternatives using statistical data transformations and regression techniques that take the special structure of the compositional sample space into account. In a comparative analysis on synthetic and semi-synthetic data we show the advantages and limitations of our proposal. We posit that our framework may provide a useful starting point for cause-effect estimation in the context of compositional data.
Beyond traditional assumptions in fair machine learning
Jan 29, 2021This thesis scrutinizes common assumptions underlying traditional machine learning approaches to fairness in consequential decision making. After challenging the validity of these assumptions in real-world applications, we propose ways to move forward when they are violated. First, we show that group fairness criteria purely based on statistical properties of observed data are fundamentally limited. Revisiting this limitation from a causal viewpoint we develop a more versatile conceptual framework, causal fairness criteria, and first algorithms to achieve them. We also provide tools to analyze how sensitive a believed-to-be causally fair algorithm is to misspecifications of the causal graph. Second, we overcome the assumption that sensitive data is readily available in practice. To this end we devise protocols based on secure multi-party computation to train, validate, and contest fair decision algorithms without requiring users to disclose their sensitive data or decision makers to disclose their models. Finally, we also accommodate the fact that outcome labels are often only observed when a certain decision has been made. We suggest a paradigm shift away from training predictive models towards directly learning decisions to relax the traditional assumption that labels can always be recorded. The main contribution of this thesis is the development of theoretically substantiated and practically feasible methods to move research on fair machine learning closer to real-world applications.